![Save 60% on Tokens [A new file format for the AI Age]](https://i1.wp.com/cdn.analyticsvidhya.com/wp-content/uploads/2025/11/JASON-VS-TOON-1.png?w=1920&resize=1920,1036&ssl=1 "Save 60% on Tokens [A new file format for the AI Age]")
Within the present period of AI, all of the technical engineers could be conversant in LLMs. These LLMs have made it simpler for us to finish duties by assigning them to tackle sure repetitive duties. As AI engineers, this has undoubtedly elevated our output.
Nonetheless, every time we use LLMs, we use a major variety of tokens. These tokens act as a ticket for us to speak with these fashions. Further tokens are used as reasoning tokens when utilizing a reasoning mannequin. Sadly, the tokens which are getting used are additionally very costly, which ends up in the consumer hitting the speed restrict or a subscription paywall.
With the intention to decrease our token utilization and, thus, decrease total prices, we might be exploring a brand new notation that has simply emerged referred to as the Token-Oriented Object Notation, or TOON.
What’s JSON?
JavaScript Object Notation, or JSON, is a light-weight data-interchange format that’s easy for computer systems to parse and produce in addition to for people to learn and write. It’s excellent for exchanging structured information between programs, reminiscent of between a consumer and a server in net purposes, as a result of it represents information as key-value pairs, arrays, and nested constructions. Practically all programming languages can settle for JSON natively as a result of it’s text-based and impartial of language. A JSON formatted information appears to be like just like this:
{ "identify": "Hamzah",
"age": 22,
"abilities": ["Gen AI", "CV", "NLP"],
"work": {
"group": "Analytics Vidhya",
"function": "Information Scientist"
}
}
Learn extra: JSON Prompting
What’s TOON?
Token-Oriented Object Notation (TOON) is a compact, human-readable serialization format designed to effectively move structured information to Giant Language Fashions (LLMs) whereas utilizing considerably fewer tokens. It serves as a lossless, drop-in substitute for JSON, optimized particularly for LLM enter.
For datasets with uniform arrays of objects, the place each merchandise has the identical construction (reminiscent of rows in a desk), TOON works particularly nicely. It creates a structured and token-efficient format by fusing the tabular compactness of CSV with the indentation-based readability of YAML. JSON should still be a greater illustration for deeply nested or irregular information, although TOON excels at managing tabular or reliably structured information.
In essence, TOON presents the compactness of CSV with the structure-awareness of JSON, serving to LLMs parse and motive about information extra reliably. Consider it as a translation layer: you need to use JSON programmatically, then convert it to TOON for environment friendly LLM enter.
For instance:
JSON (token-heavy):
{ "customers": [
{ "id": 1, "name": "Alice", "role": "admin" },
{ "id": 2, "name": "Bob", "role": "user" }
]
}
TOON (token-efficient):
customers[2]{id,identify,function}:1,Alice,admin
2,Bob,consumer
Key Options
- Token-efficient: Achieves 30–60% fewer tokens than formatted JSON for giant, uniform datasets, considerably decreasing LLM enter prices.
- LLM-friendly guardrails: Express subject names and declared array lengths make it simpler for fashions to validate construction and keep consistency.
- Minimal syntax: Eliminates redundant punctuation reminiscent of braces, brackets, and most citation marks, preserving the format light-weight and readable.
- Indentation-based construction: Much like YAML, TOON makes use of indentation as an alternative of nested braces to signify hierarchy, enhancing readability.
- Tabular arrays: Defines keys as soon as, then streams rows of information effectively, ideally suited for datasets with a constant schema.
- Non-obligatory key folding: Permits nested single-key wrappers to be collapsed into dotted paths (e.g., information.metadata.objects), decreasing indentation and token rely additional.
Benchmark Efficiency
In keeping with the check outcomes, TOON frequently performs higher by way of accuracy and token effectivity than extra standard information codecs like JSON, YAML, and XML. With 73.9% accuracy and simply 2,744 tokens, TOON reveals the most effective steadiness between correctness and compactness over 209 retrieval issues and 4 distinct LLMs. In comparison with JSON, which achieves a lesser accuracy of 69.7% whereas utilizing 39.6% extra tokens, that is much more environment friendly. Amongst all examined types, TOON has the best total effectivity as a result of benchmark scoring takes accuracy per 1,000 tokens into consideration.
Total, the benchmark exhibits that TOON presents a greater steadiness between structural readability, token value, and accuracy. Due to its design, LLMs can extract info extra constantly, comprehend tabular and nested patterns extra readily, and keep glorious efficiency throughout quite a lot of dataset sorts. In lots of real-world retrieval purposes, these traits make TOON a extra LLM-friendly information format than JSON, YAML, XML, and even CSV.
On a playground, you’ll be able to check out the TOON efficiency:
When to not use TOON?
Whereas TOON performs exceptionally nicely for uniform arrays of objects, there are eventualities the place different information codecs are extra environment friendly or sensible:
- Deeply nested or non-uniform constructions: When information has many nested ranges or inconsistent fields (tabular eligibility ≈ 0%), compact JSON may very well use fewer tokens. That is widespread with advanced configuration recordsdata or hierarchical metadata.
- Semi-uniform arrays (~40–60% tabular eligibility): Token financial savings turn into much less vital as structural consistency decreases. In case your present information pipelines are already constructed round JSON, sticking with it might be extra handy.
- Pure tabular information: For flat datasets, CSV stays essentially the most compact format. TOON introduces a small overhead (~5–10%) to incorporate structural components like subject headers and array declarations, which enhance LLM reliability however barely enhance dimension.
- Latency-critical purposes: In setups the place end-to-end response time is the highest precedence, benchmark TOON and JSON earlier than deciding. Some deployments, particularly with native or quantized fashions (e.g., Ollama)—might course of compact JSON quicker regardless of TOON’s token financial savings. All the time evaluate TTFT (Time To First Token), tokens per second, and complete processing time for each codecs.
Working TOON
A variety of TOON implementations at the moment exist throughout a number of programming languages, supported by each official and community-driven efforts. Many mature variations are already accessible, whereas 5 implementations are nonetheless beneath energetic growth, indicating ongoing progress and ecosystem growth. The implementations at the moment in growth are: .NET (toon_format), Dart (toon), Go (gotoon), Python (toon_format), and Rust (toon_format).
You may observe the set up of TOON from right here. However for now I might be implementing TOON with the assistance of toon-python bundle.
Let’s run some primary code to see the primary perform of toon-python:
Set up
Let’s first get began with the set up
!pip set up git+https://github.com/toon-format/toon-python.git -qThe TOON API is centered round two major capabilities: encode and decode.
encode() converts any JSON-serializable worth into compact TOON format, dealing with nested objects, arrays, dates, and BigInts mechanically whereas providing non-compulsory controls like indentation and key folding.
decode() reverses this course of, studying TOON textual content and reconstructing the unique JavaScript values, with strict validation accessible to catch malformed or inconsistent constructions.
TOON additionally helps customizable delimiters reminiscent of commas, tabs, and pipes. These have an effect on how array rows and tabular information are separated, permitting customers to optimize for readability or token effectivity. Tabs specifically can additional scale back token utilization since they tokenize cheaply and decrease quoting.
You may examine this out right here.
Code Implementation
So, let’s take a look at some code implementations.
I’ve included a hyperlink to my github repository the place I’ve used TOON in a simple chatbot after the conclusion half if you wish to see how one can incorporate TOON into your code. Check out it.
The primary import perform for Python implementation could be from toon_format.
1. estimate_savings + compare_formats + count_tokens
This block takes a Python dictionary, converts it to each JSON and TOON, and calculates what number of tokens every format would use. It then prints the share of token financial savings and exhibits a side-by-side comparability, and eventually counts the tokens for a TOON string straight.
from toon_format import estimate_savings, compare_formats, count_tokens
# Measure financial savings
information = {
"customers": [
{
"id": 1,
"name": "Alice"
},
{
"id": 2,
"name": "Bob"
}
]
}
outcome = estimate_savings(information)
print(f"Saves {outcome['savings_percent']:.1f}% tokens") # Saves 42.3% tokens
# Visible comparability
print(compare_formats(information))
# Rely tokens straight
toon_str = encode(information)
tokens = count_tokens(toon_str) # Makes use of tiktoken (gpt5/gpt5-mini)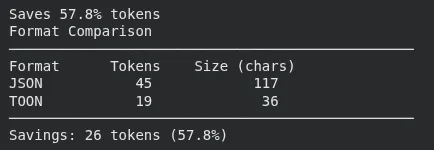
2. estimate_savings on user_data
This part measures what number of tokens the consumer’s information would produce in JSON vs TOON. It prints the token counts for each codecs and the share financial savings achieved by switching to TOON.
from toon_format import estimate_savings
# Your precise information construction
user_data = {
"customers": [
{"id": 1, "name": "Alice", "email": "[email protected]", "energetic": True},
{"id": 2, "identify": "Bob", "electronic mail": "[email protected]", "energetic": True},
{"id": 3, "identify": "Charlie", "electronic mail": "[email protected]", "energetic": False}
]
}
# Examine codecs
outcome = estimate_savings(user_data)
print(f"JSON: {outcome['json_tokens']} tokens")
print(f"TOON: {outcome['toon_tokens']} tokens")
print(f"Financial savings: {outcome['savings_percent']:.1f}%")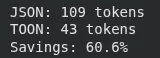
3. Estimating cash saved utilizing TOON
This block runs token financial savings on a bigger dataset (100 objects), then applies GPT-5 pricing to calculate how a lot every request prices in JSON versus TOON. It prints the associated fee distinction per request and the projected financial savings over 10,000 requests.
from toon_format import estimate_savings
# Your typical immediate information
prompt_data = {
"context": [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Analyze this data"}
],
"information": [
{"id": i, "value": f"Item {i}", "score": i * 10}
for i in range(1, 101) # 100 items
]
}
outcome = estimate_savings(prompt_data["data"])
# GPT-5 pricing (instance: $0.01 per 1K tokens)
cost_per_1k = 0.01
json_cost = (outcome['json_tokens'] / 1000) * cost_per_1k
toon_cost = (outcome['toon_tokens'] / 1000) * cost_per_1k
print(f"JSON value per request: ${json_cost:.4f}")
print(f"TOON value per request: ${toon_cost:.4f}")
print(f"Financial savings per request: ${json_cost - toon_cost:.4f}")
print(f"Financial savings per 10,000 requests: ${(json_cost - toon_cost) * 10000:.2f}")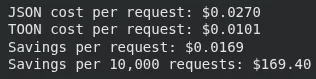
Conclusion
By offering an organised, compact, and intensely token-efficient substitute for standard codecs like JSON, TOON marks a major change in the way in which we put together information for LLMs. Lowering token utilization instantly leads to cheaper working bills, significantly for customers that pay per token via API credit, as extra builders rely on LLMs for automation, evaluation, and software workflows. TOON additionally will increase extraction accuracy, lowers ambiguity, and boosts mannequin reliability throughout quite a lot of datasets by making information extra predictable and easier for fashions to digest.
Codecs like TOON have the potential to utterly change how LLMs deal with structured information sooner or later. Environment friendly representations will turn into ever extra vital in managing value, delay, and efficiency as AI programs advance to deal with bigger, extra difficult contexts. Builders will be capable to create richer apps, scale their workloads extra successfully, and supply quicker, extra correct outcomes utilizing instruments that decrease token utilization with out compromising construction. TOON is not only a brand new information format. It’s a step in the direction of a time the place everybody can cope with LLMs extra intelligently, affordably, and successfully.
Try my Github challenge, the place I’ve applied TOON right here.
Often Requested Questions
A. TOON cuts token utilization by sending structured information to LLMs in a compact, clear format.
A. It removes most punctuation, makes use of indentation, and defines fields as soon as, which lowers token rely whereas preserving construction readable.
A. It shines with uniform arrays of objects, particularly tabular information the place each row shares the identical schema.
Information Scientist @ Analytics Vidhya | CSE AI and ML @ VIT Chennai
Enthusiastic about AI and machine studying, I am desperate to dive into roles as an AI/ML Engineer or Information Scientist the place I could make an actual affect. With a knack for fast studying and a love for teamwork, I am excited to carry modern options and cutting-edge developments to the desk. My curiosity drives me to discover AI throughout varied fields and take the initiative to delve into information engineering, making certain I keep forward and ship impactful tasks.
Login to proceed studying and revel in expert-curated content material.

{kind=link}