
After exhibiting spectacular effectivity with Gemma 3, operating highly effective AI on a single GPU, Google has pushed the boundaries even additional with Gemma 3n. This new launch brings state-of-the-art AI to cell and edge gadgets, utilizing minimal reminiscence whereas delivering quick, multimodal efficiency. On this article, we’ll discover what makes Gemma 3n so highly effective, the way it works underneath the hood with improvements like Per-Layer Embeddings (PLE) and MatFormer structure, and the way to entry Gemma 3n simply utilizing Google AI Studio. For those who’re a developer trying to construct quick, good, and light-weight AI apps, that is your start line.
What’s Gemma 3n?
Gemma 3 confirmed us that highly effective AI fashions can run effectively, even on a single GPU, whereas outperforming bigger fashions like DeepSeek V3 in chatbot Elo scores with considerably much less compute. Now, Google has taken issues additional with Gemma 3n, designed to carry state-of-the-art efficiency to even smaller, on-device environments like cellphones and edge gadgets.
To make this attainable, Google partnered with {hardware} leaders like Qualcomm, MediaTek, and Samsung System LSI, introducing a brand new on-device AI structure that powers quick, personal, and multimodal AI experiences. The “n” in Gemma 3n stands for nano, reflecting its small measurement but highly effective capabilities.
This new structure is constructed on two key improvements:
- Per-Layer Embeddings (PLE): Innovated by Google DeepMind to reduces reminiscence utilization by caching and managing layer-specific information exterior the mannequin’s fundamental reminiscence. It permits bigger fashions (5B and 8B parameters) to run with simply 2GB to 3GB of RAM, much like 2B and 4B fashions.
- MatFormer (Matryoshka Transformer): A nested mannequin structure that permits smaller sub-models to perform independently inside a bigger mannequin. This provides builders flexibility to decide on efficiency or velocity with out switching fashions or rising reminiscence utilization.
Collectively, these improvements make Gemma 3n environment friendly for operating high-performance, multimodal AI on low-resource gadgets.
How Does PLE Improve Gemma 3n’s Efficiency?
When Gemma 3n fashions are executed, Per-Layer Embedding (PLE) settings are employed to generate information that improves every mannequin layer’s efficiency. As every layer executes, the PLE information might be created independently, exterior the mannequin’s working reminiscence, cached to fast storage, after which included to the mannequin inference course of. By stopping PLE parameters from getting into the mannequin reminiscence house, this methodology lowers useful resource utilization with out sacrificing the standard of the mannequin’s response.
Gemma 3n fashions are labeled with parameter counts like E2B and E4B, which check with their Efficient parameter utilization, a price decrease than their whole variety of parameters. The “E” prefix signifies that these fashions can function utilizing a diminished set of parameters, because of the versatile parameter know-how embedded in Gemma 3n, permitting them to run extra effectively on lower-resource gadgets.
These fashions manage their parameters into 4 key classes: textual content, visible, audio, and per-layer embedding (PLE) parameters. As an example, whereas the E2B mannequin usually hundreds over 5 billion parameters throughout customary execution, it may scale back its energetic reminiscence footprint to only 1.91 billion parameters through the use of parameter skipping and PLE caching, as proven within the following picture:
Key Options of Gemma 3n
Gemma 3n is finetuned for machine duties:
- That is the mannequin’s capability to make use of consumer enter to provoke or name particular operations instantly on the machine, similar to launching apps, sending reminders, turning on a flashlight, and so forth. It permits the AI to do extra than simply reply; it may additionally talk with the machine itself.
- Gemma 3n can comprehend and react to inputs that mix textual content and graphics if they’re interleaved. As an example, the mannequin can deal with each while you add a picture and ask a textual content inquiry about it.
- For the primary time within the Gemma household, it has the power to grasp each audio and visible inputs. Audio and video weren’t supported by earlier Gemma fashions. Gemma 3n is now capable of view movies and take heed to sound so as to comprehend what is going on, similar to recognizing actions, detecting speech, or responding to inquiries primarily based on a video clip.
This permits the mannequin to work together with the setting and permits customers to naturally work together with purposes. Gemma 3n is 1.5 occasions sooner than Gemma 3 4B on cell. This will increase the fluidity within the consumer expertise (Overcomes the technology latency in LLMs).
Gemma 3n has a smaller submodel as a novel 2 in 1 matformer structure. This lets customers dynamically select efficiency and velocity as essential. And to do that we shouldn’t have to handle a separate mannequin. All this occurs in the identical reminiscence footprint.
How MatFormer Structure Helps?
A Matryoshka Transformer or MatFormer mannequin structure, which consists of nested smaller fashions inside an even bigger mannequin, is utilized by Gemma 3n fashions. It’s attainable to make inferences utilizing the layered sub-models with out triggering the enclosing fashions’ parameters whereas reacting to queries. Working solely the smaller, core fashions inside a MatFormer mannequin helps decrease the mannequin’s vitality footprint, response time, and compute value. The E2B mannequin’s parameters are included within the E4B mannequin for Gemma 3n. You may also select settings and put collectively fashions in sizes that fall between 2B and 4B with this structure.
The right way to Entry Gemma 3n?
Gemma 3n preview is obtainable in Google AI Studio, Google GenAI SDK and MediaPipe (Huggingface and Kaggle). We’ll entry Gemma 3n utilizing Google AI Studio.

- Step 1: Login to Google AI studio
- Step 2: Click on on the Get API key

- Step 3: Click on on the Create API key

- Step 4: Choose a undertaking of your selection and click on on Create API Key

- Step 5: Copy the API and put it aside for additional use to entry Gemma 3n.
- Step 6: Now that we now have the API Lets spin up a colab occasion. Use colab.new within the browser to create a brand new pocket book.
- Step 7: Set up dependencies
!pip set up google-genaiStep 8: Use secret keys in colab to retailer GEMINI_API_KEY, allow the pocket book entry as nicely.

- Step 9: Use the under code to set setting variables:
from google.colab import userdata
import os
os.environ["GEMINI_API_KEY"] = userdata.get('GEMINI_API_KEY')- Step 10: Run the under code to deduce outcomes from Gemma 3n:
import base64
import os
from google import genai
from google.genai import varieties
def generate():
consumer = genai.Shopper(
api_key=os.environ.get("GEMINI_API_KEY"),
)
mannequin = "gemma-3n-e4b-it"
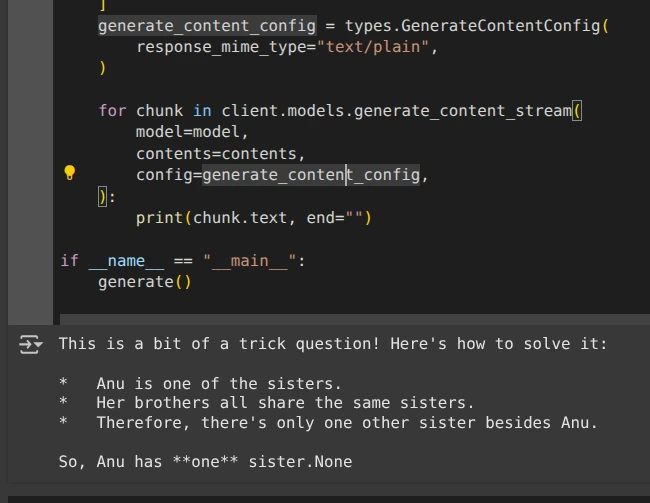
contents = [
types.Content(
role="user",
parts=[
types.Part.from_text(text="""Anu is a girl. She has three brothers. Each of her brothers has the same two sisters. How many sisters does Anu have?"""),
],
),
]
generate_content_config = varieties.GenerateContentConfig(
response_mime_type="textual content/plain",
)
for chunk in consumer.fashions.generate_content_stream(
mannequin=mannequin,
contents=contents,
config=generate_content_config,
):
print(chunk.textual content, finish="")
if __name__ == "__main__":
generate()Output:
Additionally Learn: Prime 13 Small Language Fashions (SLMs)
Conclusion
Gemma 3n is an enormous leap for AI on small gadgets. It runs highly effective fashions with much less reminiscence and sooner velocity. Because of PLE and MatFormer, it’s environment friendly and good. It really works with textual content, photos, audio, and even video all on-device. Google has made it straightforward for builders to check and use Gemma 3n by way of Google AI Studio. For those who’re constructing cell or edge AI apps, Gemma 3n is certainly price exploring. Checkout Google AI Edge to run the Gemma 3n Regionally.
Information science Trainee at Analytics Vidhya, specializing in ML, DL and Gen AI. Devoted to sharing insights by way of articles on these topics. Desirous to be taught and contribute to the sector’s developments. Enthusiastic about leveraging information to unravel advanced issues and drive innovation.
Login to proceed studying and revel in expert-curated content material.

{kind=link}