
In machine studying and information science, evaluating a mannequin is as necessary as constructing it. Accuracy is commonly the primary metric individuals use, however it may be deceptive when the info is imbalanced. Because of this, metrics akin to precision, recall, and F1 rating are broadly used. This text focuses on the F1 rating. It explains what the F1 rating is, why it issues, the right way to calculate it, and when it needs to be used. The article additionally features a sensible Python instance utilizing scikit-learn and discusses widespread errors to keep away from throughout mannequin analysis.
What Is the F1 Rating in Machine Studying?
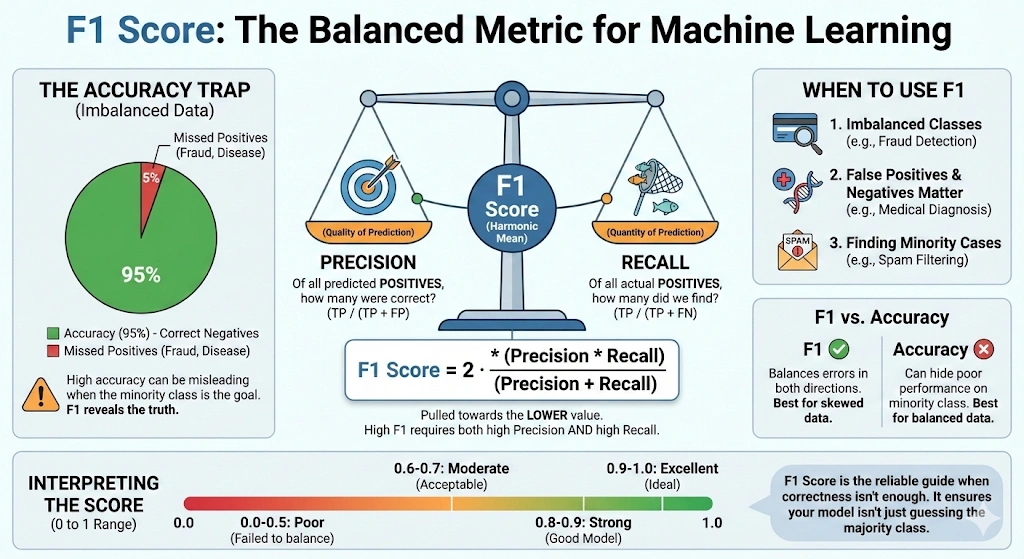
The F1 rating, also referred to as the balanced F-score or F-measure, is a metric used to guage a mannequin by combining precision and recall right into a single worth. It’s generally utilized in classification issues, particularly when the info is imbalanced or when false positives and false negatives matter.
Precision measures what number of predicted constructive circumstances are literally constructive. In easy phrases, it solutions the query: out of all predicted constructive circumstances, what number of are appropriate. Recall, additionally referred to as sensitivity, measures what number of precise constructive circumstances the mannequin appropriately identifies. It solutions the query: out of all actual constructive circumstances, what number of did the mannequin detect.
Precision and recall typically have a tradeoff. Enhancing one can cut back the opposite. The F1 rating addresses this by utilizing the harmonic imply, which supplies extra weight to decrease values. Because of this, the F1 rating is excessive solely when each precision and recall are excessive.
F1 = 2 ×
Precision × Recall
Precision + Recall
The F1 rating ranges from 0 to 1, or from 0 to 100%. A rating of 1 signifies excellent precision and recall. A rating of 0 signifies that both precision or recall is zero, or each. This makes the F1 rating a dependable metric for evaluating classification fashions.
Additionally Learn: 8 Methods to Enhance Accuracy of Machine Studying Fashions
When Ought to You Use the F1 Rating?
When the precision alone can’t present a clear image of the mannequin’s efficiency, the F1 rating is employed. This principally happens in lopsided information. A mannequin is likely to be extremely correct in such conditions, solely by making predictions on the majority of class. However, it may possibly completely fail to establish minority teams. F1 rating is beneficial in fixing this concern as a result of it pays consideration to precision and recall.
F1 rating is useful when the false positives are necessary in addition to the false negatives. It supplies one worth by which a mannequin balances these two classes of errors. To have a excessive F1 rating on a mannequin, it should carry out properly on precision and recall. This renders it extra reliable than precision in most duties completed in the true world.
Actual-World Use Circumstances of the F1 Rating
F1 rating is normally utilized within the following conditions:
- Imbalanced classification points like spam filtering, fraud detection, and medical analysis.
- The knowledge retrieval and search methods, through which the helpful outcomes needs to be positioned with a minimal variety of false coincidences.
- Mannequin or threshold tuning, when each precision and recall are necessary.
When one type of error is considerably costlier than the opposite one, then that kind of error shouldn’t be utilized independently to F1 rating. Recall is likely to be extra vital in case it’s worse to overlook a constructive case. When false alarms are extra unhealthy, accuracy could be the superior level of consideration. When accuracy and the flexibility to recall are of equal significance, the F1 rating is essentially the most appropriate.
Find out how to Calculate the F1 Rating Step by Step
The F1 rating could be calculated as soon as precision and recall are recognized. These metrics are derived from the confusion matrix in a binary classification downside.
Precision measures what number of predicted constructive circumstances are literally constructive. It’s outlined as:
Precision =
TP
TP + FP
Recall is used to find out the variety of precise positives which might be retrieved. It’s outlined as:
Recall =
TP
TP + FN
Right here, TP represents true positives, FP represents false positives, and FN represents false negatives.
F1 Rating Method Utilizing Precision and Recall
After understanding precision (P) and recall (R), the F1 rating could be decided because the harmonic imply of the 2:
F1 =
2 × P × R
P + R
The harmonic imply offers extra weight to smaller values. Because of this, the F1 rating is pulled towards the decrease of precision or recall. For instance, if precision is 0.90 and recall is 0.10, the F1 rating is roughly 0.18. If each precision and recall are 0.50, the F1 rating can be 0.50.
This ensures {that a} excessive F1 rating is achieved solely when each precision and recall are excessive.
F1 Rating Method Utilizing the Confusion Matrix
One may also write out the identical system utilizing phrases of the confusion matrix:
F1 =
2 TP
2 TP + FP + FN
Contemplating an instance, when the mannequin is characterised by the precision of 0.75 and a recall of 0.60, the F1 rating is:
F1 =
2 × 0.75 × 0.60
0.75 + 0.60
=
0.90
/
1.35
≈
0.67
In multi-class classification issues, the F1 rating is computed individually for every class after which averaged. Macro averaging treats all lessons equally, whereas weighted averaging accounts for sophistication frequency. In extremely imbalanced datasets, weighted F1 is normally the higher general metric. All the time test the averaging methodology when evaluating mannequin efficiency.
Computing the F1 Rating in Python utilizing scikit-learn
An instance of binary classification is as follows. Precision, recall, and F1 rating will likely be calculated with the assistance of scikit-learn. This assists in demonstrating the best way these metrics are sensible.
To start with, carry within the mandatory capabilities.
from sklearn.metrics import precision_score, recall_score, f1_score, classification_report Now, outline the true labels and the mannequin predictions for ten samples.
# True labels
y_true = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0] # 1 = constructive, 0 = detrimental
# Predicted labels
y_pred = [1, 0, 1, 1, 0, 0, 0, 1, 0, 0] Subsequent, compute precision, recall, and the F1 rating for the constructive class.
precision = precision_score(y_true, y_pred, pos_label=1)
recall = recall_score(y_true, y_pred, pos_label=1)
f1 = f1_score(y_true, y_pred, pos_label=1)
print("Precision:", precision)
print("Recall:", recall)
print("F1 rating:", f1) You may as well generate a full classification report.
print ("nClassification Report:n", classification_report(y_true, y_pred)) Working this code produces output like the next:
Precision: 0.75 Recall: 0.6 F1 rating: 0.6666666666666666
Classification Report:
Classification Report:
precision recall f1-score help
0 0.67 0.80 0.73 5
1 0.75 0.60 0.67 5
accuracy 0.70 10
macro avg 0.71 0.70 0.70 10
weighted avg 0.71 0.70 0.70 10
Understanding Classification Report Output in scikit-learn
Let’s interpret these outcomes.
Within the constructive class (label 1), the accuracy is 0.75. This suggests that three quarters of the samples that have been postulated to be constructive have been constructive. The recall is 0.60 indicating that the mannequin recognized 60% of all of the true constructive samples appropriately. When these two values are added, the result’s a worth of about F1 of 0.67.
In case of the detrimental class (label 0), the recall is bigger at 0.80. This demonstrates that the mannequin is more practical in figuring out negativism than positivism. Its accuracy is 70% general, which isn’t a measurement of the effectiveness of the mannequin in every separate classification.
This may be simpler seen within the classification report. It presents precision, recall, and F1 by the class, macro, and weighted averages. On this balanced case, the macro and weighted F1 scores are comparable. Weighted F1 scores in additional unbalanced datasets locations extra emphasis on the dominant class.
That is demonstrated by a sensible instance of computing and decoding the F1 rating. The F1 rating on the validation/check information in actual tasks could be used to decide the stability of false positives and false negatives could be like your mannequin is.
Finest Practices and Widespread Pitfalls in the usage of F1 Rating
Select F1 based mostly in your goal:
- F1 is used when recall and precision are equally necessary.
- There is no such thing as a want to make use of F1 when one type of erroneousness is costlier.
- Use weighted F-scores the place mandatory.
Don’t depend on F1 alone:
- F1 is a mixed metric.
- It hides the stability between precision and recall.
- All the time overview precision and recall individually.
Deal with class imbalance rigorously:
- F1 performs properly as in comparison with accuracy when confronted with imbalanced information.
- Averaging strategies have an effect on the ultimate rating.
- Macro F1 treats all lessons equally.
- Weighted F1 favors frequent lessons.
- Decide the tactic that displays your objectives.
Look ahead to zero or lacking predictions:
- F1 could be zero when a category isn’t predicted.
- This will likely sign a mannequin or information concern.
- All the time examine the confusion matrix.
Use F1 properly for mannequin choice:
- F1 works properly for evaluating fashions.
- Small variations might not be significant.
- Mix F1 with area data and different metrics.
Conclusion
The F1 rating is a robust metric for evaluating classification fashions. It combines precision and recall right into a single worth and is particularly helpful when each varieties of errors matter. It’s significantly efficient for issues with imbalanced information.
In contrast to accuracy, the F1 rating highlights weaknesses that accuracy can conceal. This text defined what the F1 rating is, how it’s calculated, and the right way to interpret it utilizing Python examples.
The F1 rating needs to be used with care, like several analysis metric. It really works greatest when precision and recall are equally necessary. All the time select analysis metrics based mostly in your challenge objectives. When utilized in the precise context, the F1 rating helps construct extra balanced and dependable fashions.
Often Requested Questions
A. An F1 rating of 0.5 signifies reasonable efficiency. It means the mannequin balances precision and recall poorly and is commonly acceptable solely as a baseline, particularly in imbalanced datasets or early-stage fashions.
A. An excellent F1 rating is determined by the issue. Usually, scores above 0.7 are thought-about first rate, above 0.8 sturdy, and above 0.9 glorious, particularly in classification duties with class imbalance.
A. No. Decrease F1 scores point out worse efficiency. Since F1 combines precision and recall, the next worth at all times means the mannequin is making fewer false positives and false negatives general.
A. F1 rating is used when class imbalance exists or when each false positives and false negatives matter. It supplies a single metric that balances precision and recall, not like accuracy, which could be deceptive.
A. 80% accuracy could be good or unhealthy relying on context. In balanced datasets it could be acceptable, however in imbalanced issues, excessive accuracy can conceal poor efficiency on minority lessons.
A. Use accuracy for balanced datasets the place all errors matter equally. Use F1 rating when coping with class imbalance or when precision and recall are extra necessary than general correctness.
Hello, I’m Janvi, a passionate information science fanatic at the moment working at Analytics Vidhya. My journey into the world of knowledge started with a deep curiosity about how we are able to extract significant insights from advanced datasets.
Login to proceed studying and revel in expert-curated content material.

{kind=link}