

Embedding fashions act as bridges between completely different information modalities by encoding various multimodal data right into a shared dense illustration house. There have been developments in embedding fashions in recent times, pushed by progress in massive basis fashions. Nevertheless, present multimodal embedding fashions are skilled on datasets comparable to MMEB and M-BEIR, with most focus solely on pure photos and images sourced from the MSCOCO, Flickr, and ImageNet datasets. These datasets fail to cowl bigger types of visible data, together with paperwork, PDFs, web sites, movies, and slides. This causes present embedding fashions to underperform on reasonable duties comparable to article looking out, web site looking out, and YouTube video search.
Multimodal embedding benchmarks comparable to MSCOCO, Flickr30K, and Conceptual Captions initially centered on static image-text pairs for duties like picture captioning and retrieval. More moderen benchmarks, comparable to M-BEIR and MMEB, launched multi-task evaluations, however stay restricted to static photos and quick contexts. Video illustration studying has developed by means of fashions like VideoCLIP and VideoCoCa, integrating contrastive studying with captioning targets. Visible doc illustration studying superior by means of fashions like ColPali and VisRAG, which use VLMs for doc retrieval. Unified modality retrieval strategies like GME and Uni-Retrieval obtain sturdy efficiency on common benchmarks. Nevertheless, none can unify picture, video, and visible doc retrieval inside a single framework.

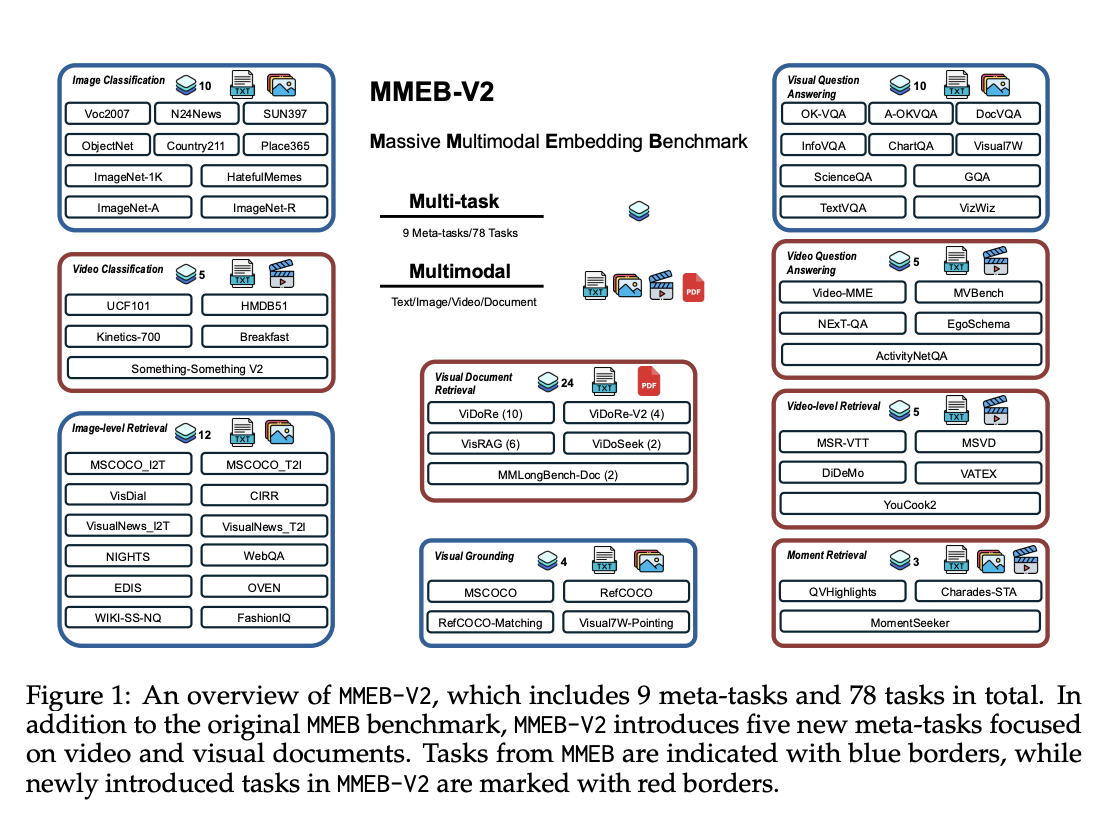
Researchers from Salesforce Analysis, UC Santa Barbara, College of Waterloo, and Tsinghua College have proposed VLM2Vec-V2 to unify picture, video, and visible doc retrieval inside a single framework. Firstly, researchers developed MMEB-V2, a benchmark that extends MMEB with 5 new process varieties, together with visible doc retrieval, video retrieval, temporal grounding, video classification, and video query answering. Secondly, VLM2Vec-V2 serves as a general-purpose embedding mannequin that helps a number of enter modalities whereas demonstrating sturdy efficiency on each newly launched duties and authentic picture benchmarks. This establishes a basis for extra scalable and versatile illustration studying in each analysis and sensible purposes.
VLM2Vec-V2 makes use of Qwen2-VL as its spine, chosen for its specialised capabilities in multimodal processing. Qwen2-VL gives three important options that help unified embedding studying: Naive Dynamic Decision, Multimodal Rotary Place Embedding (M-RoPE), and a unified framework that mixes 2D and 3D convolutions. To allow efficient multi-task coaching throughout various information sources, VLM2Vec-V2 introduces a versatile information sampling pipeline with two key parts: (a) on-the-fly batch mixing primarily based on predefined sampling weight tables that management the relative chances of every dataset, and (b) an interleaved sub-batching technique that splits full batches into independently sampled sub-batches, bettering the soundness of contrastive studying.
VLM2Vec-V2 achieves the best total common rating of 58.0 throughout 78 datasets overlaying picture, video, and visible doc duties, outperforming sturdy baselines together with GME, LamRA, and VLM2Vec constructed on the identical Qwen2-VL spine. On picture duties, VLM2Vec-V2 outperforms most baselines by important margins and achieves efficiency similar to VLM2Vec-7B regardless of being solely 2B parameters in dimension. For video duties, the mannequin achieves aggressive efficiency regardless of coaching on comparatively small quantities of video information. In visible doc retrieval, VLM2Vec-V2 outperforms all VLM2Vec variants, however nonetheless lags behind ColPali, which is particularly optimized for visible doc duties.
In conclusion, researchers launched VLM2Vec-V2, a powerful baseline mannequin skilled by means of contrastive studying throughout various duties and modality combos. VLM2Vec-V2 is constructed upon MMEB-V2 and makes use of Qwen2-VL as its spine mannequin. MMEB-V2 is a benchmark designed by researchers to evaluate multimodal embedding fashions throughout varied modalities, together with textual content, photos, movies, and visible paperwork. The experimental analysis demonstrates the effectiveness of VLM2Vec-V2 in attaining balanced efficiency throughout a number of modalities whereas highlighting the diagnostic worth of MMEB-V2 for future analysis.
Try the Paper, GitHub Web page and Mannequin on Hugging Face. All credit score for this analysis goes to the researchers of this venture. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.

Sajjad Ansari is a closing 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.

{kind=link}