
Voice AI is changing into probably the most necessary frontiers in multimodal AI. From clever assistants to interactive brokers, the power to grasp and cause over audio is reshaping how machines interact with people. But whereas fashions have grown quickly in functionality, the instruments for evaluating them haven’t saved tempo. Current benchmarks stay fragmented, gradual, and narrowly centered, typically making it troublesome to check fashions or check them in life like, multi-turn settings.
To deal with this hole, UT Austin and ServiceNow Analysis Group has launched AU-Harness, a brand new open-source toolkit constructed to guage Massive Audio Language Fashions (LALMs) at scale. AU-Harness is designed to be quick, standardized, and extensible, enabling researchers to check fashions throughout a variety of duties—from speech recognition to advanced audio reasoning—inside a single unified framework.
Why do we want a brand new audio analysis framework?
Present audio benchmarks have centered on functions like speech-to-text or emotion recognition. Frameworks resembling AudioBench, VoiceBench, and DynamicSUPERB-2.0 broadened protection, however they left some actually essential gaps.
Three points stand out. First is throughput bottlenecks: many toolkits don’t make the most of batching or parallelism, making large-scale evaluations painfully gradual. Second is prompting inconsistency, which makes outcomes throughout fashions exhausting to check. Third is restricted job scope: key areas like diarization (who spoke when) and spoken reasoning (following directions delivered in audio) are lacking in lots of instances.
These gaps restrict the progress of LALMs, particularly as they evolve into multimodal brokers that should deal with lengthy, context-heavy, and multi-turn interactions.
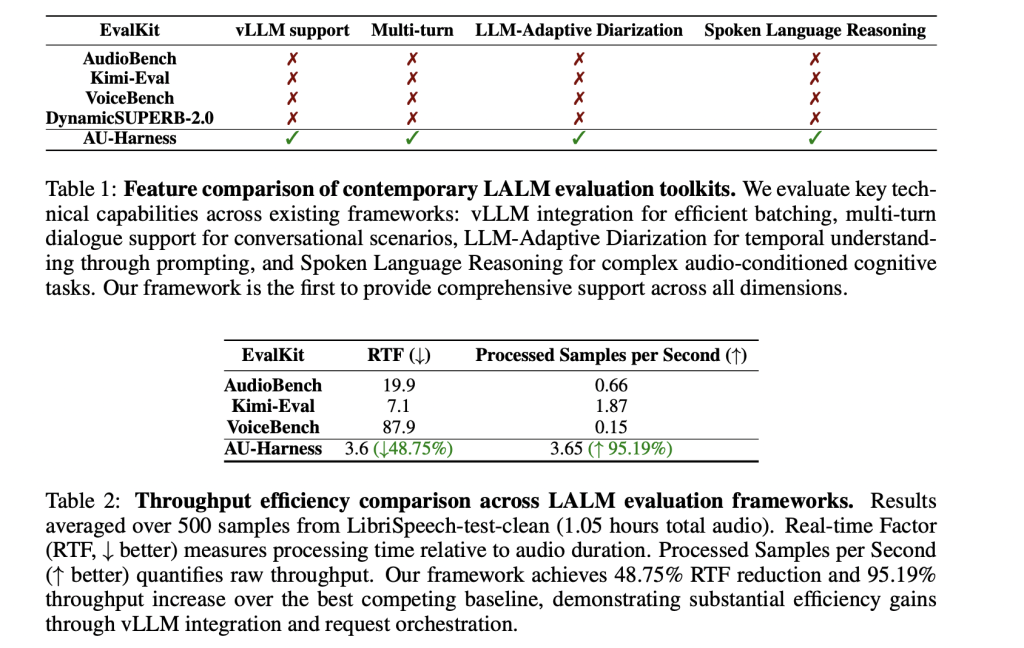
How does AU-Harness enhance effectivity?
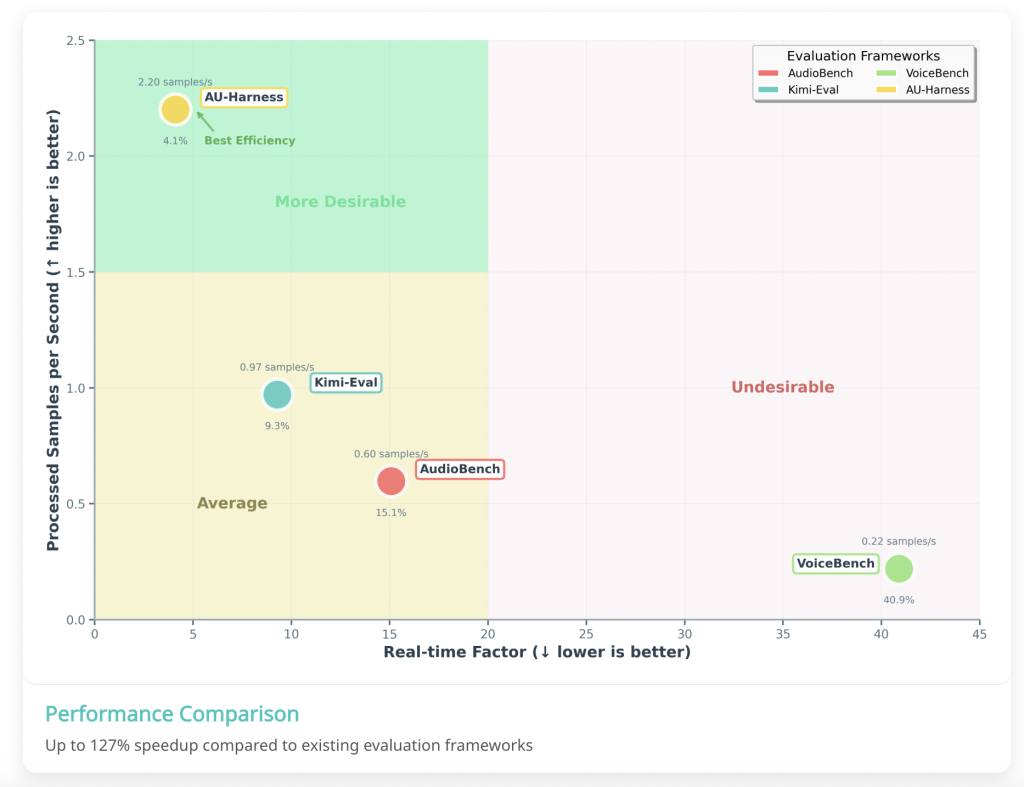
The analysis workforce designed AU-Harness with deal with pace. By integrating with the vLLM inference engine, it introduces a token-based request scheduler that manages concurrent evaluations throughout a number of nodes. It additionally shards datasets in order that workloads are distributed proportionally throughout compute assets.
This design permits near-linear scaling of evaluations and retains {hardware} totally utilized. In observe, AU-Harness delivers 127% greater throughput and reduces the real-time issue (RTF) by almost 60% in comparison with current kits. For researchers, this interprets into evaluations that after took days now finishing in hours.

Can evaluations be personalized?
Flexibility is one other core characteristic of AU-Harness. Every mannequin in an analysis run can have its personal hyperparameters, resembling temperature or max token settings, with out breaking standardization. Configurations enable for dataset filtering (e.g., by accent, audio size, or noise profile), enabling focused diagnostics.
Maybe most significantly, AU-Harness helps multi-turn dialogue analysis. Earlier toolkits had been restricted to single-turn duties, however fashionable voice brokers function in prolonged conversations. With AU-Harness, researchers can benchmark dialogue continuity, contextual reasoning, and adaptableness throughout multi-step exchanges.
What duties does AU-Harness cowl?
AU-Harness dramatically expands job protection, supporting 50+ datasets, 380+ subsets, and 21 duties throughout six classes:
- Speech Recognition: from easy ASR to long-form and code-switching speech.
- Paralinguistics: emotion, accent, gender, and speaker recognition.
- Audio Understanding: scene and music comprehension.
- Spoken Language Understanding: query answering, translation, and dialogue summarization.
- Spoken Language Reasoning: speech-to-coding, perform calling, and multi-step instruction following.
- Security & Safety: robustness analysis and spoofing detection.
Two improvements stand out:
- LLM-Adaptive Diarization, which evaluates diarization by prompting slightly than specialised neural fashions.
- Spoken Language Reasoning, which assessments fashions’ means to course of and cause about spoken directions, slightly than simply transcribe them.

What do the benchmarks reveal about at this time’s fashions?
When utilized to main techniques like GPT-4o, Qwen2.5-Omni, and Voxtral-Mini-3B, AU-Harness highlights each strengths and weaknesses.
Fashions excel at ASR and query answering, displaying sturdy accuracy in speech recognition and spoken QA duties. However they lag in temporal reasoning duties, resembling diarization, and in advanced instruction-following, notably when directions are given in audio kind.
A key discovering is the instruction modality hole: when similar duties are introduced as spoken directions as an alternative of textual content, efficiency drops by as a lot as 9.5 factors. This means that whereas fashions are adept at processing text-based reasoning, adapting these expertise to the audio modality stays an open problem.
Abstract
AU-Harness marks an necessary step towards standardized and scalable analysis of audio language fashions. By combining effectivity, reproducibility, and broad job protection—together with diarization and spoken reasoning—it addresses the long-standing gaps in benchmarking voice-enabled AI. Its open-source launch and public leaderboard invite the group to collaborate, examine, and push the boundaries of what voice-first AI techniques can obtain.
Take a look at the Paper, Undertaking and GitHub Web page. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}