
This put up was written with John Spencer, Sreeram Thoom, and Dipankar Kushari from Databricks.
Organizations want seamless entry to information throughout a number of platforms and enterprise models. A typical state of affairs entails one workforce utilizing Amazon EMR for information processing whereas needing to entry information that one other workforce manages in Databricks Unity Catalog. Historically, this could require information duplication or complicated handbook setups.
Though each Amazon EMR and Databricks Unity Catalog are highly effective instruments on their very own, integrating them successfully is essential for sustaining sturdy information governance, safety, and operational effectivity. On this put up, we exhibit easy methods to obtain this integration utilizing Amazon EMR Serverless, although the strategy works nicely with different Amazon EMR deployment choices and Unity Catalog OSS.
EMR Serverless makes working large information analytics frameworks easy by providing a serverless possibility that routinely provisions and manages the infrastructure required to run large information purposes. Groups can run Apache Spark and different workloads with out the complexity of cluster administration, whereas offering cost-effective scaling primarily based on precise workload calls for and seamless integration with AWS companies and safety controls.
Databricks Unity Catalog serves as a unified governance answer for information and AI belongings, offering centralized entry management and auditing capabilities. It allows fine-grained permissions throughout workspaces and cloud platforms, whereas supporting complete metadata administration and information discovery throughout the group, and might complement governance instruments like AWS Lake Formation.
To allow Amazon EMR to course of information maintained in Unity Catalog, the information workforce historically copies information merchandise throughout the platforms to a location accessible by Amazon EMR. The follow of information duplication not solely results in elevated storage prices, but additionally severely impacts information high quality and makes it difficult to successfully implement identical governance insurance policies throughout totally different techniques, monitor information lineage, implement information retention insurance policies, and keep constant entry controls throughout the group.
Now utilizing Unity Catalog’s Open REST APIs, Amazon EMR clients can learn from and write to Databricks Unity Catalog and Unity Catalog OSS tables utilizing Spark, enabling cross-platform interoperability whereas sustaining governance and entry controls throughout Amazon EMR and Unity Catalog.
Resolution overview
On this put up, we are going to present an summary of EMR Spark workload integration with Databricks Unity Catalog and stroll via the end-to-end technique of studying from and writing to Databricks Unity Catalog tables utilizing Amazon EMR and Spark. We present you easy methods to configure EMR Serverless to work together with Databricks Unity Catalog, run an interactive Spark workload to entry the information, and run an evaluation to derive insights.
The next diagram illustrates the answer structure.
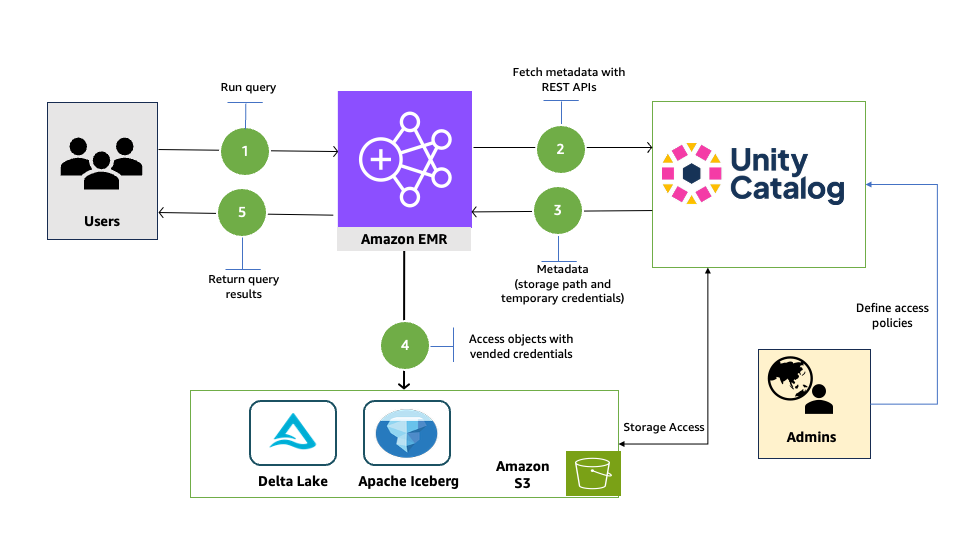
Conditions
You have to have the next conditions:
Within the following sections, we stroll via the method of studying and writing to Unity Catalog with EMR Serverless.
Allow Unity Catalog for exterior entry
Log in to your workspace as a Databricks admin and full the next steps to configure exterior entry to learn Databricks objects:
- Allow exterior information entry on your metastore. For directions, see Allow exterior information entry on the metastore.
- Arrange a principal that can be configured with Amazon EMR for information entry.
- Grant the principal the privilege to configure the mixing of the EXTERNAL USE SCHEMA privilege on the schema containing the objects. For directions, see Grant a principal EXTERNAL USE SCHEMA.
- For this put up, we generate a Databricks private entry token (PAT) for the principal and notice it down. For directions, check with Authorizing entry to Databricks sources and Databricks private entry token authentication.
For a manufacturing deployment, retailer the PAT in AWS Secrets and techniques Supervisor. You need to use it in a later step to learn and write to Unity Catalog with Amazon EMR.
Configure EMR Spark to entry Unity Catalog
On this walkthrough, we run PySpark interactive queries via notebooks utilizing EMR Studio. Full the next steps:
- Open the AWS Administration Console with administrator permission.
- Create an EMR Studio to run interactive workloads. To create a workspace, you have to specify the S3 bucket created within the conditions and the minimal service position for EMR Serverless. For directions, see Arrange an EMR Studio.
- For this put up, we create two EMR Serverless purposes. For directions, see Creating an EMR Serverless utility from the EMR Studio console.
- For Iceberg tables, create an EMR Serverless utility known as dbx-demo-application-iceberg with model 7.8.0 or larger. Ensure that to deselect Use AWS Glue Knowledge Catalog as Metastore underneath Extra Configurations, Metastore configuration. Add the next Spark configuration (see Configure purposes). Present the identify of the catalog in Unity Catalog that incorporates your tables and the URL of the Databricks workspace.
- For Delta tables, create an EMR Serverless utility known as dbx-demo-application and model 7.8.0 or larger. Ensure that to deselect Use AWS Glue Knowledge Catalog as Metastore underneath Extra Configurations, Metastore configuration. Add the next Spark configuration (see Configure purposes). Present the identify of the catalog in Unity Catalog that incorporates your tables and the URL of the Databricks workspace.
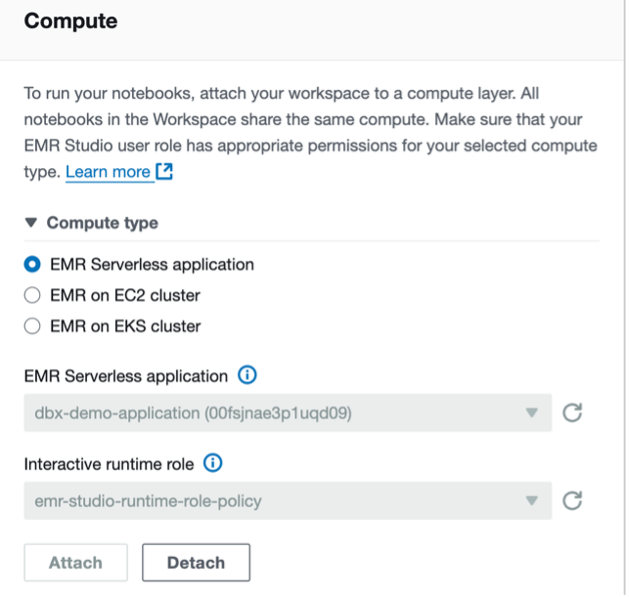
- To arrange your interactive workload with a runtime position, see Run interactive workloads with EMR Serverless via EMR Studio.
Learn and write to Unity Catalog with Amazon EMR
Launch the workspace created within the earlier step. Obtain the notebooks create-delta-table and create-iceberg-table and add them to the EMR Studio workspace.
The create-delta-table.ipynb pocket book configures the metastore properties to work with Delta tables. The create-iceberg-table.ipynb pocket book configures the metastore properties to work with Iceberg tables.
Add the generated token to the session.
For a manufacturing deployment, retailer the PAT in Secrets and techniques Supervisor.

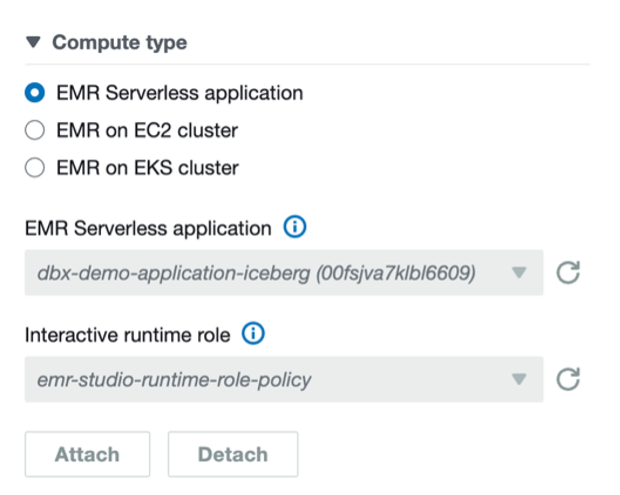
For Iceberg tables, connect with the EMR Serverless utility dbx-demo-application-iceberg with the runtime position created in earlier steps underneath compute and run the pocket book (create-iceberg-table). Choose PySpark because the kernel and execute every cell within the pocket book by selecting the run icon. Check with Submit a job run or interactive workload for additional particulars about easy methods to run an interactive pocket book.
We use the next code to create an exterior Iceberg desk within the catalog:
For Delta tables, connect with the EMR Serverless utility dbx-demo-application with the runtime position created in earlier steps and run the pocket book (create-delta-table). Choose PySpark because the kernel and execute every cell within the pocket book by selecting the run icon. Check with Submit a job run or interactive workload for additional particulars about easy methods to run an interactive pocket book.
We use the next code to create an exterior Delta desk within the catalog:
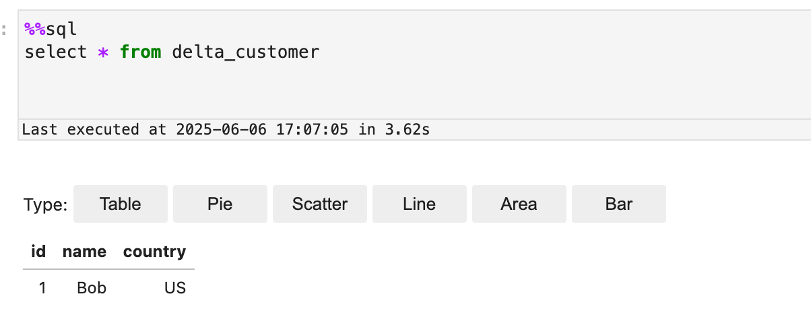
Confirm in Databricks for each Iceberg and Delta tables
Now you may run queries in Databricks Unity Catalog to point out the data inserted into the Iceberg and Delta tables from EMR Serverless:
- Log in to your Databricks workspace.
- Select SQL Editor within the navigation pane.
- Run queries for each Iceberg and Delta tables.
- Confirm the outcomes present the identical as what you noticed within the Jupyter pocket book in EMR Studio.
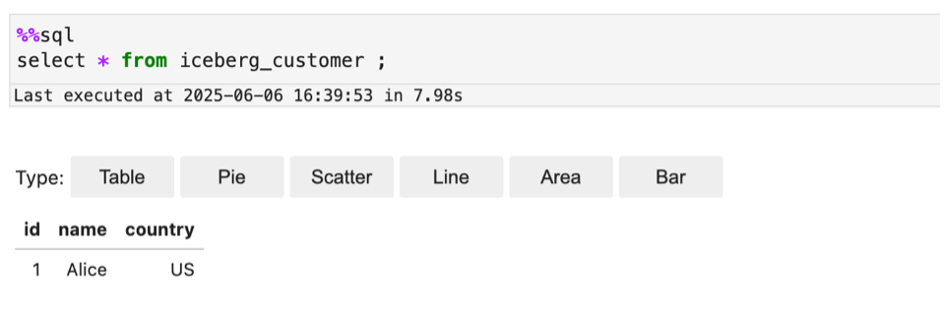
The next screenshot reveals an instance of querying the Iceberg desk.
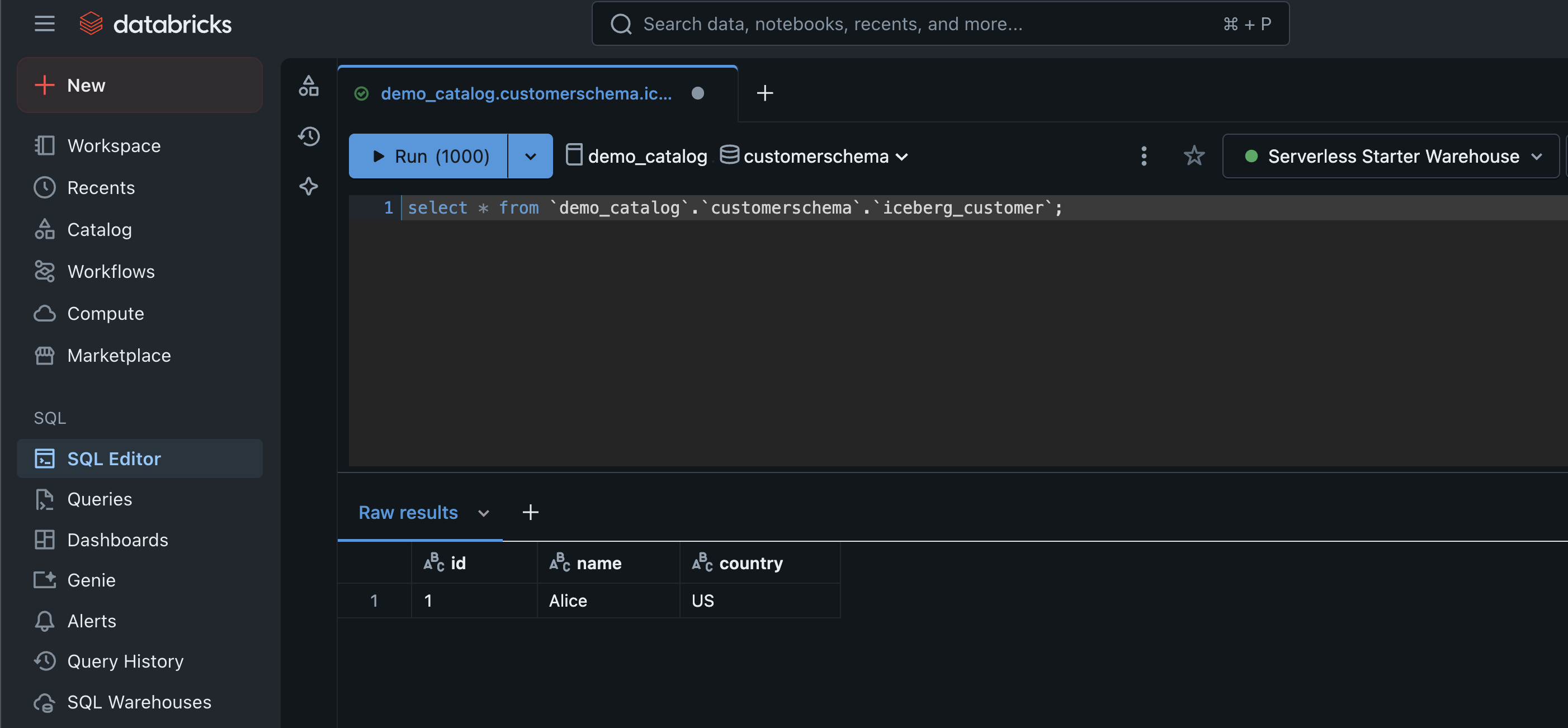
The next screenshot reveals an instance of querying the Delta desk.

Clear up
Clear up the sources used on this put up to keep away from extra fees:
- Delete the IAM roles for this put up.
- Delete the EMR purposes and EMR Studio setup created for this put up.
- Delete the sources created in Unity Catalog.
- Empty after which delete the S3 bucket.
Abstract
On this put up, we demonstrated the highly effective interoperability between Amazon EMR and Databricks Unity Catalog by strolling via easy methods to allow exterior entry to Unity Catalog, configure EMR Spark to attach seamlessly with Unity Catalog, and carry out DML and DDL operations on Unity Catalog tables utilizing EMR Serverless.
To be taught extra about utilizing EMR Serverless, see Getting began with Amazon EMR Serverless. To be taught extra about utilizing instruments like EMR Spark with Unity Catalog, see Unity Catalog integrations.
Concerning the authors
 Venkatavaradhan (Venkat) Viswanathan is a International Associate Options Architect at Amazon Internet Providers. Venkat is a Expertise Technique Chief in Knowledge, AI, ML, generative AI, and Superior Analytics. Venkat is a International SME for Databricks and helps AWS clients design, construct, safe, and optimize Databricks workloads on AWS.
Venkatavaradhan (Venkat) Viswanathan is a International Associate Options Architect at Amazon Internet Providers. Venkat is a Expertise Technique Chief in Knowledge, AI, ML, generative AI, and Superior Analytics. Venkat is a International SME for Databricks and helps AWS clients design, construct, safe, and optimize Databricks workloads on AWS.
 Srividya Parthasarathy is a Senior Huge Knowledge Architect on the AWS Lake Formation workforce. She works with the product workforce and clients to construct strong options and options for his or her analytical information platform. She enjoys constructing information mesh options and sharing them with the group.
Srividya Parthasarathy is a Senior Huge Knowledge Architect on the AWS Lake Formation workforce. She works with the product workforce and clients to construct strong options and options for his or her analytical information platform. She enjoys constructing information mesh options and sharing them with the group.
 Ramkumar Nottath is a Principal Options Architect at AWS specializing in Analytics companies. He enjoys working with varied clients to assist them construct scalable, dependable large information and analytics options. His pursuits prolong to varied applied sciences reminiscent of analytics, information warehousing, streaming, information governance, and machine studying. He loves spending time along with his household and buddies.
Ramkumar Nottath is a Principal Options Architect at AWS specializing in Analytics companies. He enjoys working with varied clients to assist them construct scalable, dependable large information and analytics options. His pursuits prolong to varied applied sciences reminiscent of analytics, information warehousing, streaming, information governance, and machine studying. He loves spending time along with his household and buddies.
 John Spencer is a Product Supervisor at Databricks, devoted to creating Unity Catalog work seamlessly with clients’ ecosystems of instruments and platforms to allow them to simply entry, govern, and use their information.
John Spencer is a Product Supervisor at Databricks, devoted to creating Unity Catalog work seamlessly with clients’ ecosystems of instruments and platforms to allow them to simply entry, govern, and use their information.
 Sreeram Thoom is a Specialist Options Architect at Databricks serving to clients design safe, scalable purposes on the Knowledge Lakehouse.
Sreeram Thoom is a Specialist Options Architect at Databricks serving to clients design safe, scalable purposes on the Knowledge Lakehouse.
 Dipankar Kushari is a specialist options architect at Databricks serving to buyer architect and construct secured purposes on Knowledge Lakehouse.
Dipankar Kushari is a specialist options architect at Databricks serving to buyer architect and construct secured purposes on Knowledge Lakehouse.

{kind=link}