
Orchestrating machine studying pipelines is complicated, particularly when information processing, coaching, and deployment span a number of companies and instruments. On this submit, we stroll via a hands-on, end-to-end instance of creating, testing, and working a machine studying (ML) pipeline utilizing workflow capabilities in Amazon SageMaker, accessed via the Amazon SageMaker Unified Studio expertise. These workflows are powered by Amazon Managed Workflows for Apache Airflow (Amazon MWAA).
Whereas SageMaker Unified Studio features a visible builder for low-code workflow creation, this information focuses on the code-first expertise: authoring and managing workflows as Python-based Apache Airflow DAGs (Directed Acyclic Graphs). A DAG is a set of duties with outlined dependencies, the place every process runs solely after its upstream dependencies are full, selling right execution order and making your ML pipeline extra reproducible and resilient.We’ll stroll via an instance pipeline that ingests climate and taxi information, transforms and joins datasets, and makes use of ML to foretell taxi fares—all orchestrated utilizing SageMaker Unified Studio workflows.
If you happen to desire a less complicated, low-code expertise, see Orchestrate information processing jobs, querybooks, and notebooks utilizing visible workflow expertise in Amazon SageMaker.
Answer overview
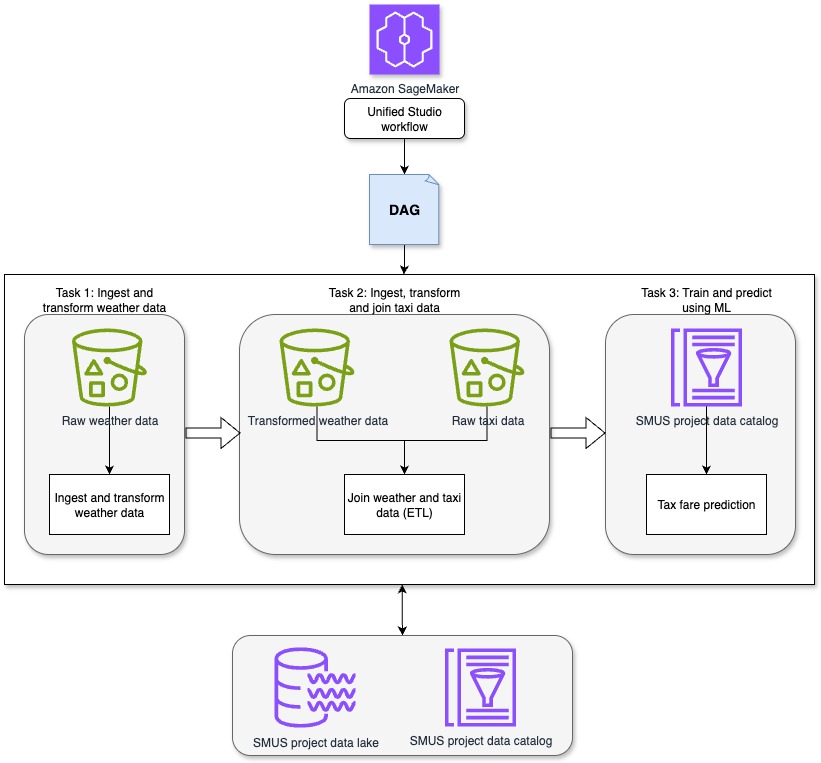
This resolution demonstrates how SageMaker Unified Studio workflows can be utilized to orchestrate a whole data-to-ML pipeline in a centralized atmosphere. The pipeline runs via the next sequential duties, as proven within the previous diagram.
- Process 1: Ingest and remodel climate information: This process makes use of a Jupyter pocket book in SageMaker Unified Studio to ingest and preprocess artificial climate information. The artificial climate dataset contains hourly observations with attributes resembling time, temperature, precipitation, and cloud cowl. For this process, the main target is on time, temperature, rain, precipitation, and wind velocity.
- Process 2: Ingest, remodel and be a part of taxi information: A second Jupyter pocket book in SageMaker Unified Studio ingests the uncooked New York Metropolis taxi trip dataset. This dataset contains attributes resembling pickup time, drop-off time, journey distance, passenger depend, and fare quantity. The related fields for this process embrace pickup and drop-off time, journey distance, variety of passengers, and complete fare quantity. The pocket book transforms the taxi dataset in preparation for becoming a member of it with the climate information. After transformation, the taxi and climate datasets are joined to create a unified dataset, which is then written to Amazon S3 for downstream use.
- Process 3: Prepare and predict utilizing ML: A 3rd Jupyter pocket book in SageMaker Unified Studio applies regression strategies to the joined dataset to create a mannequin to find out how attributes of the climate and taxi information resembling rain and journey distance affect taxi fares and create a fare prediction mannequin. The skilled mannequin is then used to generate fare predictions for brand spanking new journey information.
This unified strategy permits orchestration of extract, remodel, and cargo (ETL) and ML steps with full visibility into the information lifecycle and reproducibility via ruled workflows in SageMaker Unified Studio.
Conditions
Earlier than you start, full the next steps:
- Create a SageMaker Unified Studio area: Observe the directions in Create an Amazon SageMaker Unified Studio area – fast setup
- Check in to your SageMaker Unified Studio area: Use the area you created in Step 1 sign up. For extra info, see Entry Amazon SageMaker Unified Studio.
- Create a SageMaker Unified Studio challenge: Create a brand new challenge in your area by following the challenge creation information. For Challenge profile, choose All capabilities.
Arrange workflows
You should use workflows in SageMaker Unified Studio to arrange and run a collection of duties utilizing Apache Airflow to design information processing procedures and orchestrate your querybooks, notebooks, and jobs. You’ll be able to create workflows in Python code, check and share them together with your workforce, and entry the Airflow UI instantly from SageMaker Unified Studio. It supplies options to view workflow particulars, together with run outcomes, process completions, and parameters. You’ll be able to run workflows with default or customized parameters and monitor their progress. Now that you’ve got your SageMaker Unified Studio challenge arrange, you may construct your workflows.
- In your SageMaker Unified Studio challenge, navigate to the Compute part and choose Workflow atmosphere.
- Select Create atmosphere to arrange a brand new workflow atmosphere.
- Assessment the choices and select Create atmosphere. By default, SageMaker Unified Studio creates an mw1.micro class atmosphere, which is appropriate for testing and small-scale workflows. To replace the atmosphere class earlier than challenge creation, navigate to Area and choose Challenge Profiles after which All Capabilities and go to OnDemand Workflows blueprint deployment settings. Through the use of these settings, you may override default parameters and tailor the atmosphere to your particular challenge necessities.
Develop workflows
You should use workflows to orchestrate notebooks, querybooks, and extra in your challenge repositories. With workflows, you may outline a set of duties organized as a DAG that may run on a user-defined schedule.To get began:
- Obtain Climate Information Ingestion, Taxi Ingest and Be a part of to Climate, and Prediction notebooks to your native atmosphere.
- Go to Construct and choose JupyterLab; select Add information and import the three notebooks you downloaded within the earlier step.
- Configure your SageMaker Unified Studio house: Areas are used to handle the storage and useful resource wants of the related software. For this demo, configure the house with an ml.m5.8xlarge occasion
- Select Configure House within the right-hand nook and cease the house.
- Replace occasion kind to ml.m5.8xlarge and begin the house. Any lively processes might be paused in the course of the restart, and any unsaved modifications might be misplaced. Updating the workspace may take a take jiffy.
- Go to Construct and choose Orchestration after which Workflows.
- Choose the down arrow (▼) subsequent to Create new workflow. From the dropdown menu that seems, choose Create in code editor.
- Within the editor, create a brand new Python file named
multinotebook_dag.pyunderneathsrc/workflows/dags. Copy the next DAG code, which implements a sequential ML pipeline that orchestrates a number of notebooks in SageMaker Unified Studio. ChangeNOTEBOOK_PATHSto match your precise pocket book areas.
The code makes use of the NotebookOperator to execute three notebooks so as: information ingestion for climate information, information ingestion for taxi information, and the skilled mannequin created by combining the climate and taxi information. Every pocket book runs as a separate process, with dependencies to assist be certain that they execute in sequence. You’ll be able to customise with your individual notebooks. You’ll be able to modify the NOTEBOOK_PATHS record to orchestrate any variety of notebooks of their workflow whereas sustaining sequential execution order.
The workflow schedule may be personalized by updating WORKFLOW_SCHEDULE (for instance: '@hourly', '@weekly', or cron expressions like ‘13 2 1 * *’) to match your particular enterprise wants.
- After a workflow atmosphere has been created by a challenge proprietor, and when you’ve saved your workflows DAG information in JupyterLab, they’re mechanically synced to the challenge. After the information are synced, all challenge members can view the workflows you’ve gotten added within the workflow atmosphere. See Share a code workflow with different challenge members in an Amazon SageMaker Unified Studio workflow atmosphere.
Check and monitor workflow execution
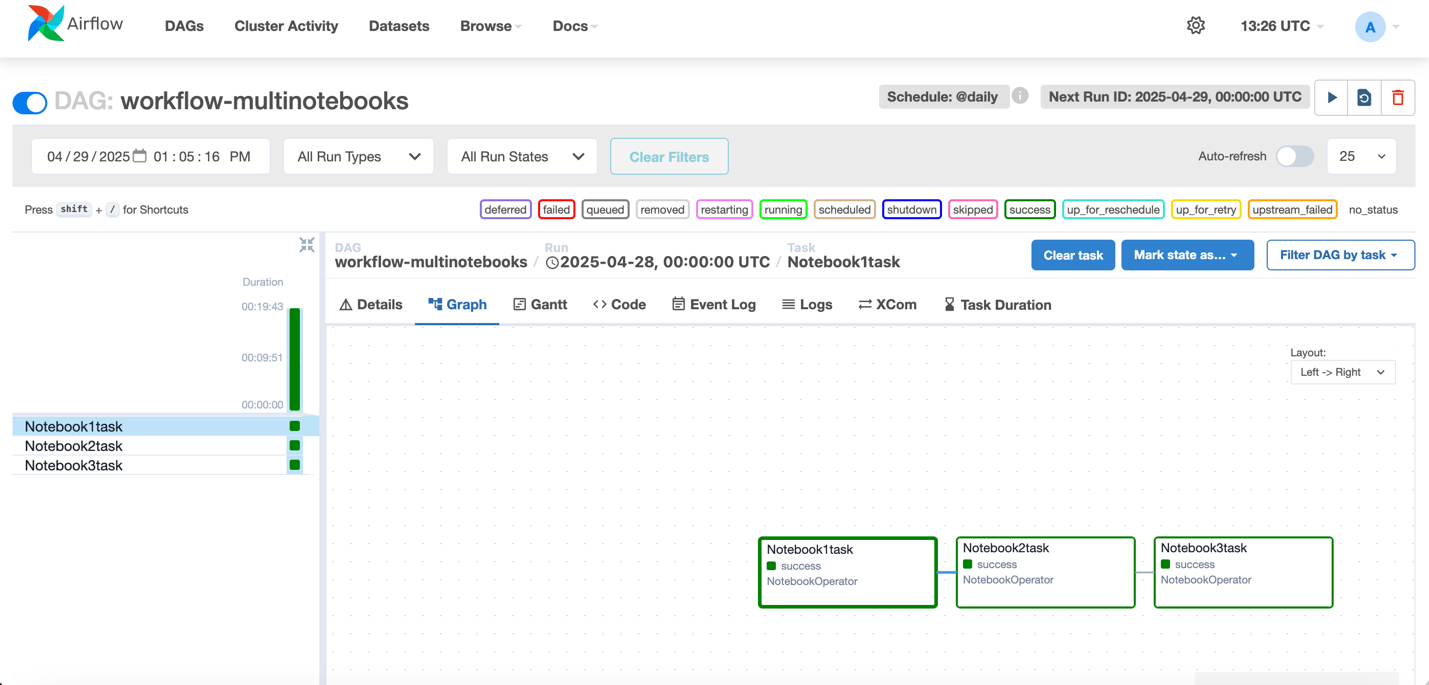
- To validate your DAG, Go to Construct > Orchestration > Workflows. You must now see the workflow working in Native House primarily based on the Schedule.
- As soon as the execution completes, workflow would change to success begin as proven beneath.
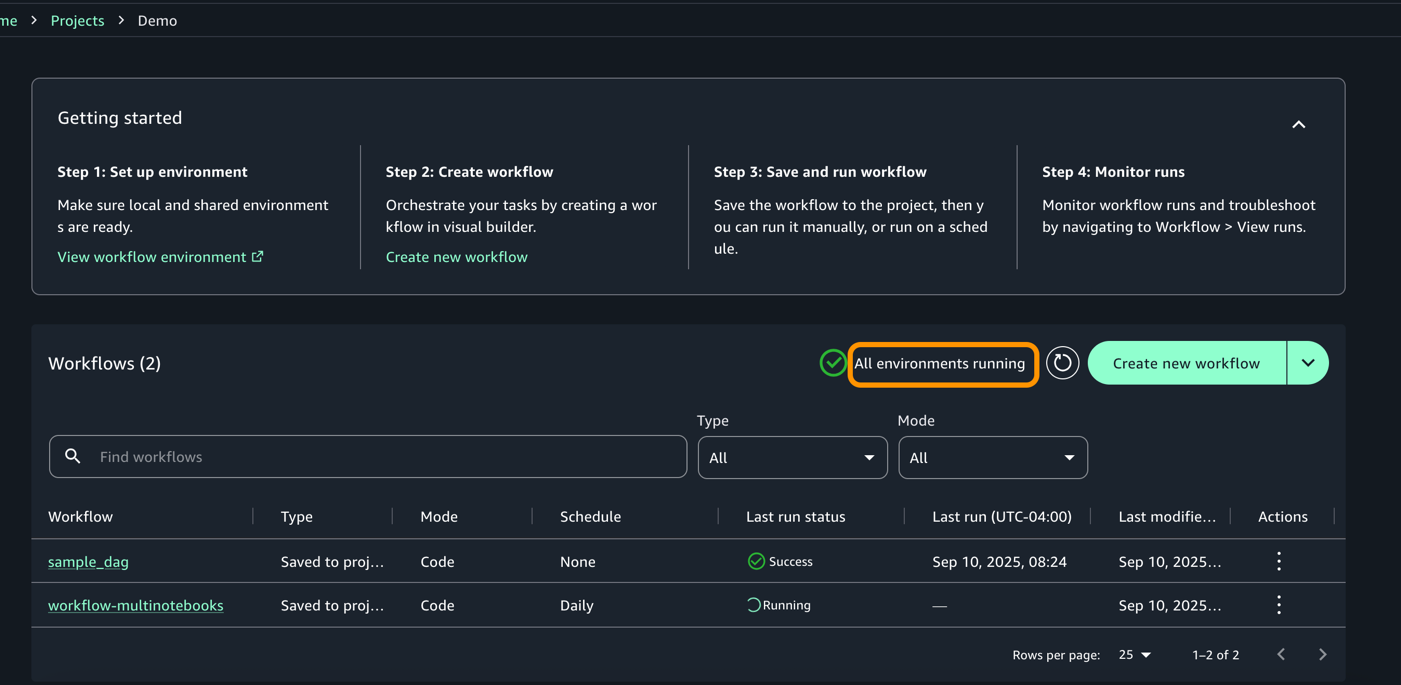
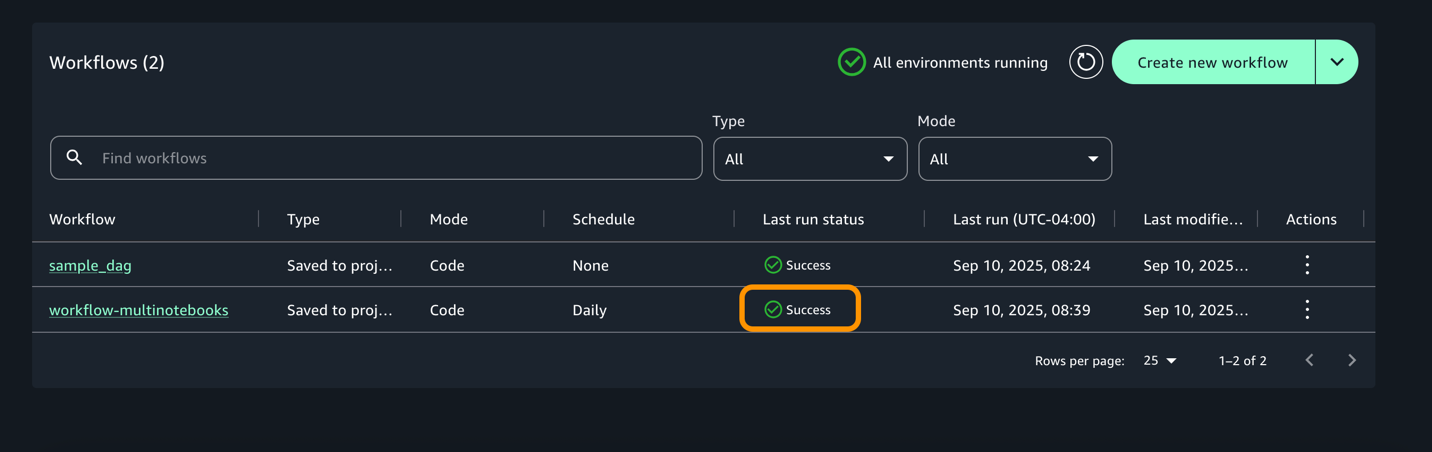
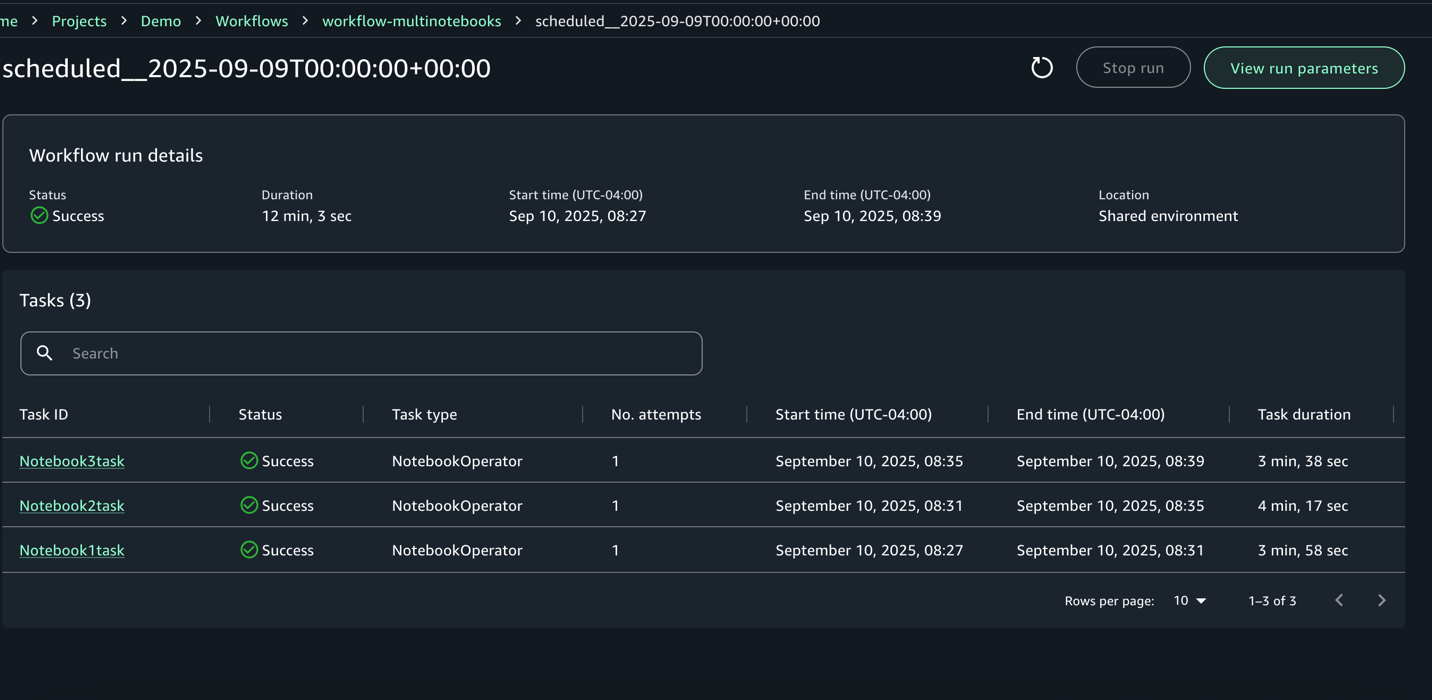
- For every execution, you may zoom in to get an in depth workflow run particulars and process logs
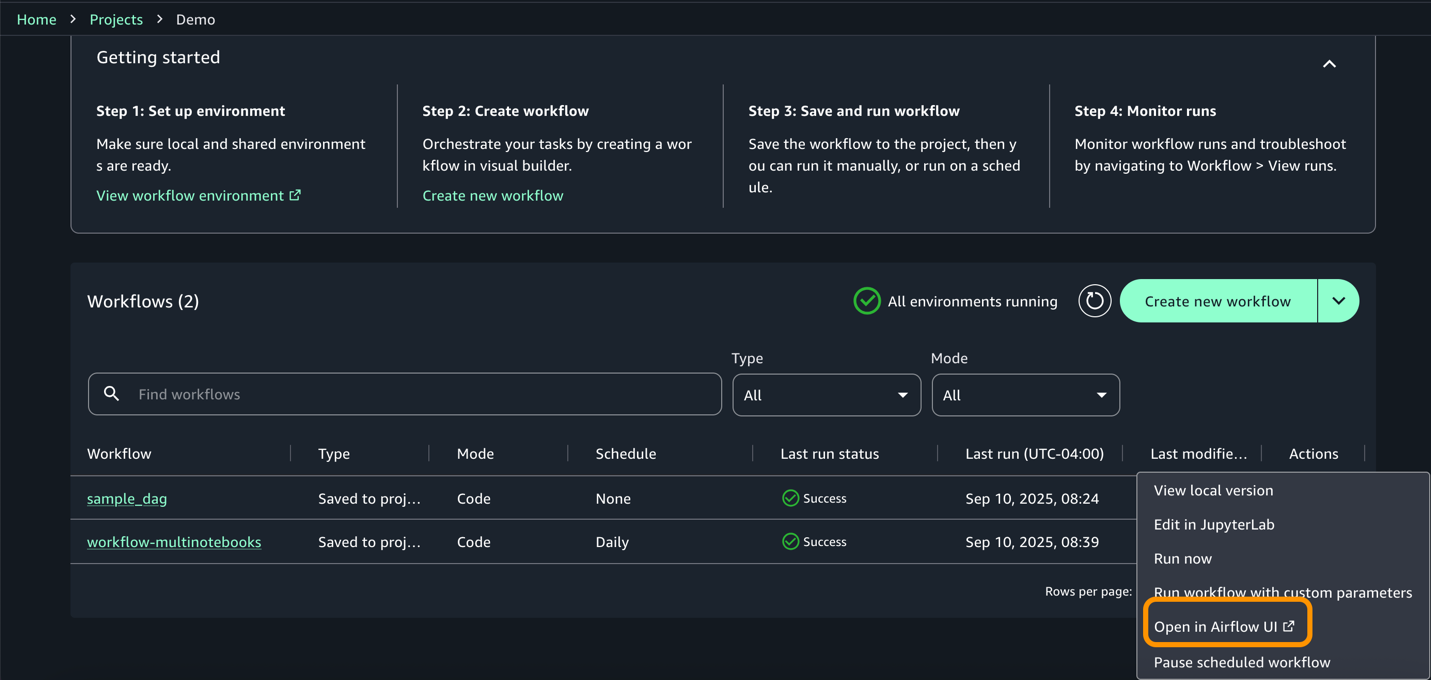
- Entry the airflow UI from actions for extra info on the dag and execution.
Outcomes
The mannequin’s output is written to the Amazon Easy Storage Service (Amazon S3) output folder as proven the next determine. These outcomes ought to be evaluated for correctness of match, prediction accuracy, and the consistency of relationships between variables. If any outcomes seem sudden or unclear, you will need to assessment the information, engineering steps, and mannequin assumptions to confirm that they align with the meant use case.
Clear up
To keep away from incurring extra fees related to assets created as a part of this submit, be sure to delete the gadgets created within the AWS account for this submit.
- The SageMaker area
- The S3 bucket related to the SageMaker area
Conclusion
On this submit, we demonstrated how you should use Amazon SageMaker to construct highly effective, built-in ML workflows that span the total information and AI/ML lifecycle. You discovered easy methods to create an Amazon SageMaker Unified Studio challenge, use a multi-compute pocket book to course of information, and use the built-in SQL editor to discover and visualize outcomes. Lastly, we confirmed you easy methods to orchestrate your entire workflow throughout the SageMaker Unified Studio interface.
SageMaker gives a complete set of capabilities for information practitioners to carry out end-to-end duties, together with information preparation, mannequin coaching, and generative AI software improvement. When accessed via SageMaker Unified Studio, these capabilities come collectively in a single, centralized workspace that helps eradicate the friction of siloed instruments, companies, and artifacts.
As organizations construct more and more complicated, data-driven purposes, groups can use SageMaker, along with SageMaker Unified Studio, to collaborate extra successfully and operationalize their AI/ML belongings with confidence. You’ll be able to uncover your information, construct fashions, and orchestrate workflows in a single, ruled atmosphere.
To study extra, go to the Amazon SageMaker Unified Studio web page.
Concerning the authors

{kind=link}