
As analytical workloads more and more demand real-time insights, organizations want enterprise knowledge to enter the information lake instantly after era. Whereas varied strategies exist for real-time CDC knowledge ingestion (corresponding to AWS Glue and Amazon EMR Serverless), Amazon MSK Join with Iceberg Kafka Join gives a totally managed, streamlined method that reduces operational complexity and permits steady knowledge synchronization.
On this submit, we display how you can use Iceberg Kafka Join with Amazon Managed Streaming for Apache Kafka (Amazon MSK) Join to speed up real-time knowledge ingestion into knowledge lakes, simplifying the synchronization course of from transactional databases to Apache Iceberg tables.
Answer overview
On this submit, we present you how you can implement capturing transaction log knowledge from Amazon Relational Database Service (Amazon RDS) for MySQL and writing it to Amazon Easy Storage Service (Amazon S3) in Iceberg desk format utilizing append mode, masking each single-table and multi-table synchronization, as proven within the following determine.

Downstream shoppers then course of these change information to reconstruct the information state earlier than writing to Iceberg tables.
On this resolution, you utilize the Iceberg Kafka Sink Connector to implement the enterprise on the sink facet. The Iceberg Kafka Sink Connector has the next options:
- Helps exactly-once supply
- Assist multi-table synchronization
- Assist schema adjustments
- Discipline title mapping by means of Iceberg’s column mapping function
Conditions
Earlier than starting the deployment, guarantee you’ve gotten the next parts in place:
Amazon RDS for MySQL: This resolution assumes you have already got an Amazon RDS for MySQL database occasion working with the information you need to synchronize to your Iceberg knowledge lake. Make sure that binary logging is enabled in your RDS occasion to assist Change Information Seize (CDC) operations.
Amazon MSK Cluster: You want an Amazon MSK cluster provisioned in your goal AWS Area. This cluster will function the streaming platform between your MySQL database and the Iceberg knowledge lake. Make sure the cluster is correctly configured with applicable safety teams and community entry.
Amazon S3 Bucket: Guarantee you’ve gotten an Amazon S3 bucket able to host the customized Kafka Join plugins. This bucket serves because the storage location from which AWS MSK Join retrieves and installs your plugins. The bucket should exist in your goal AWS Area, and you could have applicable permissions to add objects to it.
Customized Kafka Join Plugins: To allow real-time knowledge synchronization with MSK Join, you want to create two customized plugins. The primary plugin makes use of the Debezium MySQL Connector to learn transactional logs and produce Change Information Seize (CDC) occasions. The second plugin makes use of Iceberg Kafka Connect with synchronize knowledge from Amazon MSK to Apache Iceberg tables.
Construct Atmosphere: To construct the Iceberg Kafka Join plugin, you want a construct setting with Java and Gradle put in. You may both launch an Amazon EC2 occasion (advisable: Amazon Linux 2023 or Ubuntu) or use your native machine if it meets the necessities. Guarantee you’ve gotten adequate disk house (a minimum of 20GB) and community connectivity to clone the repository and obtain dependencies.
Construct Iceberg Kafka Join from open supply
The connector ZIP archive is created as a part of the Iceberg construct. You may run the construct utilizing the next code:
Create customized plugins
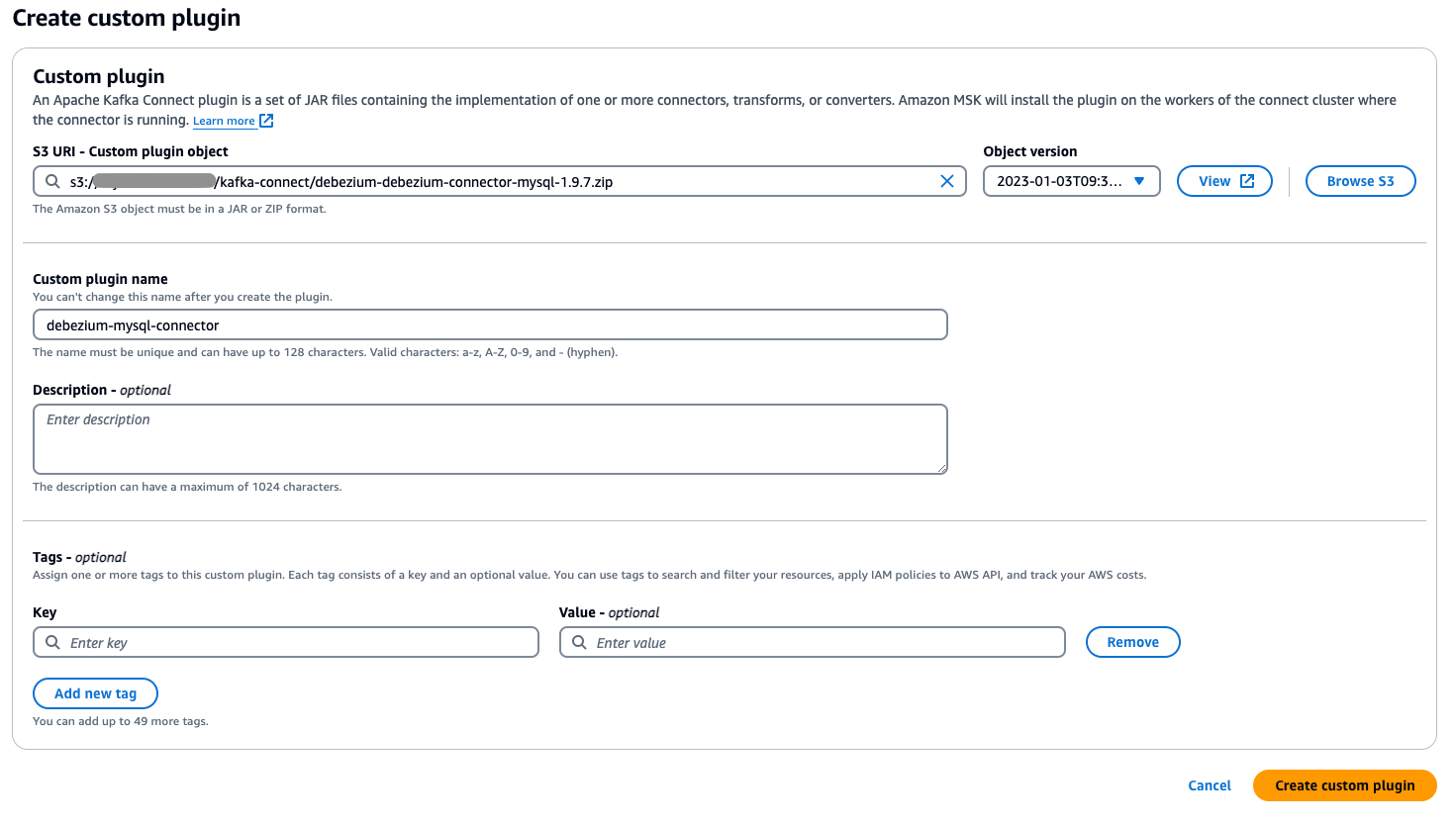
The subsequent step is to create customized plugins to learn and synchronize the information.
- Add the customized plugin ZIP file you compiled within the earlier step to your designated Amazon S3 bucket.
- Go to the AWS Administration Console and navigate to Amazon MSK and select Join within the navigation pane.
- Select Customized plugins, then choose the plugin file you uploaded to S3 by shopping or getting into its S3 URI.
- Specify a singular, descriptive title on your customized plugin (corresponding to my-connector-v1).
- Select Create customized plugin.
Configure MSK Join
With the plugins put in, you’re able to configure MSK Join.
Configure knowledge supply entry
Begin by configuring knowledge supply entry.
- To create a employee configuration, select Employee configurations within the MSK Join console.
- Select Create employee configuration and replica and paste the next configuration.
- Within the Amazon MSK console, select Connectors below Amazon MSK Join and select Create connector.
- Within the setup wizard, choose the Debezium MySQL Connector plugin created within the earlier step, enter the connector title and choose the MSK cluster of the synchronization goal. Copy and paste the next content material within the configuration:
Observe that within the configuration,
Routeis used to write down a number of information to the identical subject. Within the parametertransforms.Reroute.subject.regex, the common expression is configured to filter the desk names that should be written to the identical subject. Within the following instance, the information containingFor instance, after
transforms.Reroute.subject.alternativeis specified as$1all_records, the subject title created within the MSK is.all_records. - After you select Create, MSK Join creates a synchronization process for you.
Information synchronization (single desk mode)
Now, you may create a real-time synchronization process for the Iceberg desk. Begin by making a real-time synchronization job for a single desk.
- Within the Amazon MSK console, select Connectors below MSK Join
- Select Create connector.
- On the subsequent web page, choose the beforehand created Iceberg Kafka Join plugin
- Enter the connector title and choose the MSK cluster of the synchronization goal.
- Paste the next code within the configuration.
For Iceberg Connector, it can create a subject named
control-icebergby default to document offset. Choose the beforehand created employee configuration that featuressubject.creation.allow = true. In case you use the default employee configuration and auto-topic creation isn’t enabled on the MSK dealer stage, the connector won’t be able to robotically create subjects.You may also specify this subject title by setting the parameter
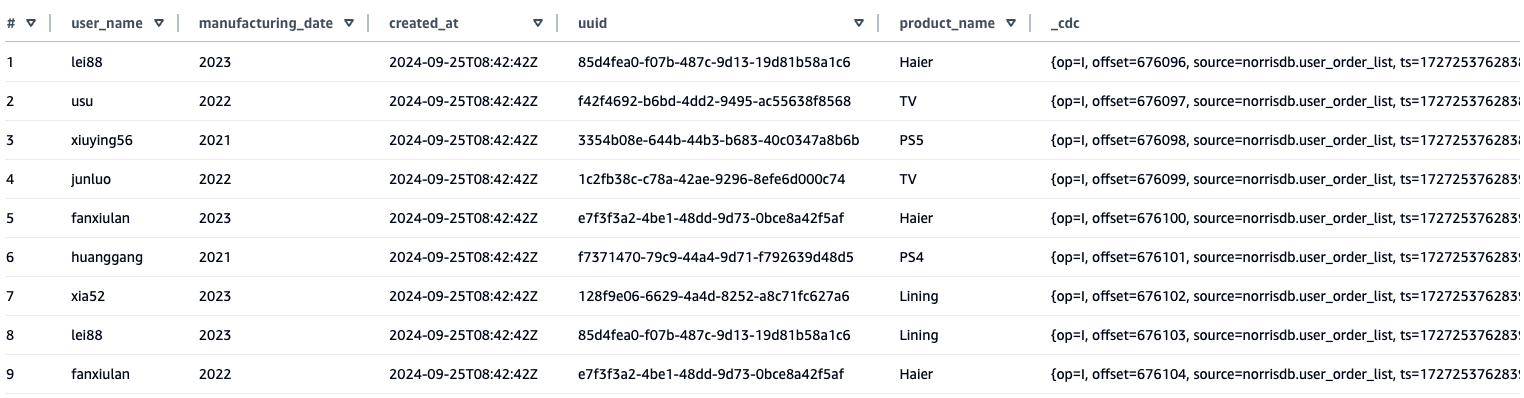
iceberg.management.subject =If you wish to use a customized subject, you should use the next code.. - Question the synchronized knowledge outcomes by means of Amazon Athena. From the desk synchronized to Athena, you may see that, along with the supply desk discipline, a further
_cdcdiscipline has been added to retailer the metadata content material of the CDC.
Compaction
Compaction is a necessary upkeep operation for Iceberg tables. Though frequent ingestion of small recordsdata can negatively impression question efficiency, common compaction mitigates this challenge by consolidating small recordsdata, minimizing metadata overhead, and considerably enhancing question effectivity. To take care of optimum desk efficiency, it is best to implement devoted compaction workflows. AWS Glue affords a wonderful resolution for this objective, offering automated compaction capabilities that intelligently merge small recordsdata and restructure desk layouts for enhanced question efficiency.
Schema Evolution Demonstration
To display the schema evolution capabilities of this resolution, we performed a check to indicate how discipline adjustments on the supply database are robotically synchronized to the Iceberg tables by means of MSK Join and Iceberg Kafka Join.
Preliminary Setup:
First, we created an RDS MySQL database with a buyer data desk (tb_customer_info) containing the next schema:
We then configured MSK Join utilizing the Debezium MySQL Connector to seize adjustments from this desk and stream them to Amazon MSK in actual time. Following that, we arrange Iceberg Kafka Connect with eat the information from MSK and write it to Iceberg tables.
Schema Modification Take a look at:
To check the schema evolution functionality, we added a brand new discipline named telephone to the supply desk:
We then inserted a brand new document with the telephone discipline populated:
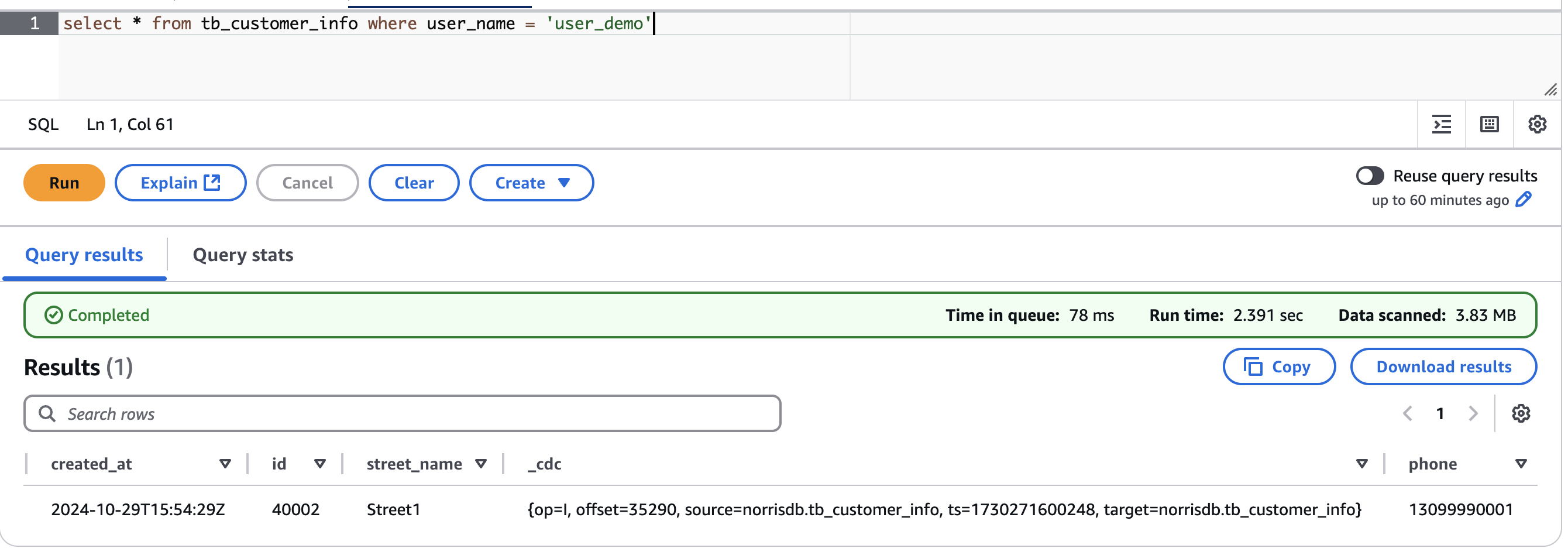
Outcomes:
Once we queried the Iceberg desk in Amazon Athena, we noticed that the telephone discipline had been robotically added because the final column, and the brand new document was efficiently synchronized with all discipline values intact. This demonstrates that Iceberg Kafka Join’s self-adaptive schema functionality seamlessly handles DDL adjustments on the supply, eliminating the necessity for guide schema updates within the knowledge lake.
Information synchronization (multi-table mode)
It’s widespread that knowledge admins need to use a single connector for transferring knowledge in a number of tables. For instance, you should use the CDC assortment instrument to write down knowledge from a number of tables to a subject after which write knowledge from one subject to a number of Iceberg tables by means of the patron facet. In Configure knowledge supply entry, you configured a MySQL synchronization Connector to synchronize tables with specified guidelines to a subject utilizing Route. Now let’s assessment how you can distribute knowledge from this subject to a number of Iceberg tables.
- When utilizing Iceberg Kafka Connect with synchronize a number of tables to Iceberg tables utilizing AWS Glue Information Catalog, you could pre-create a database within the Information Catalog earlier than beginning the synchronization course of. The database title in AWS Glue should precisely match the supply database title, as a result of the Iceberg Kafka Join connector robotically makes use of the supply database title because the goal database title throughout multi-table synchronization. This naming consistency is required as a result of the connector doesn’t present an choice to map supply database names to totally different goal database names in multi-table eventualities.
- If you wish to use your customized subject title, you may create a brand new subject to retailer the MSK Join document offset, see Information synchronization (single desk mode).
- Within the Amazon MSK console, create one other connector utilizing the next configuration.
On this configuration, two parameters have been added:
iceberg.tables.route-field: Specifies the routing discipline that distinguishes between totally different tables, specified ascdc.supplyfor CDC knowledge parsed by Debeziumiceberg.tables.dynamic-enabled: If theiceberg.tablesparameter isn’t set, it have to be specified astrueright here
- After completion, MSK Join will creates a sink connector for you.
- After the method is full, you may view the newly created desk by means of Athena.
Different suggestions
On this part, we share some extra issues that you should use to customise your deployment to suit your use case.
- Specified desk synchronizationWithin the Information synchronization (multi-table mode) part, you specify
iceberg.tables.route-field = _cdc.Supplyandiceberg.tables.dynamic-enabled=true, these two parameter settings can write a number of tables saved within the Iceberg desk. If you wish to synchronize solely the desired tables, you may specify the desk title you need to synchronize by settingiceberg.tables.dynamic-enabled = falseafter which setting theiceberg.tablesparameter. For instance, - Efficiency Testing Outcomes
We performed a efficiency check utilizing sysbench to judge the information synchronization capabilities of this resolution. The check simulated a high-volume write state of affairs to display the system’s throughput and scalability.Take a look at Configuration:- Database setup: Created 25 tables within the MySQL database utilizing sysbench
- Information loading: Wrote 20 million information to every desk (500 million whole information)
- Actual-time streaming: Configured MSK Connect with stream knowledge from MySQL to Amazon MSK in actual time throughout the write course of
- Kafka Join configuration:
- Began Kafka Iceberg Join
- Minimal employees: 1
- Most employees: 8
- Allotted two MCUs per employee
Efficiency Outcomes:
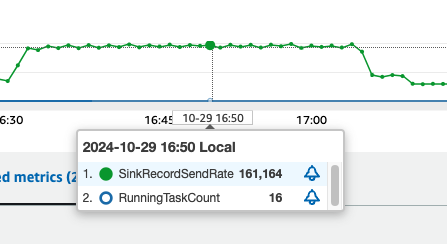
In our check utilizing the configuration above, every MCU achieved peak writing efficiency of roughly 10,000 information per second, as proven within the following determine. This demonstrates the answer’s capability to deal with high-throughput knowledge synchronization workloads successfully.
Clear up
To wash up your sources, full the next steps:
- Delete MSK Join connectors: Take away each the Debezium MySQL Connector and Iceberg Kafka Join connector created for this resolution.
- Delete the Amazon MSK cluster: In case you created a brand new MSK cluster particularly for this demonstration, delete it to cease incurring prices.
- Delete the S3 buckets: Take away the S3 buckets used to retailer the customized Kafka Join plugins and Iceberg desk knowledge. Guarantee you’ve gotten backed up any knowledge you want earlier than deletion.
- Delete the EC2 occasion: In case you launched an EC2 occasion to construct the Iceberg Kafka Join plugin, terminate it.
- Delete the RDS MySQL occasion (non-compulsory): In case you created a brand new RDS occasion particularly for this demonstration, delete it. In case you’re utilizing an current manufacturing database, skip this step.
- Take away IAM roles and insurance policies (if created): Delete any IAM roles and insurance policies that had been created particularly for this resolution to keep up safety greatest practices.
Conclusion
On this submit, we introduced an answer to realize real-time, environment friendly knowledge synchronization from transactional databases to knowledge lakes utilizing Amazon MSK Join and Iceberg Kafka Join. This resolution gives a low-cost and environment friendly knowledge synchronization paradigm for enterprise-level large knowledge evaluation. Whether or not you’re working with ecommerce transactions, monetary transactions, or IoT machine logs, this resolution will help you obtain fast entry to an information lake, enabling analytical companies to shortly acquire the newest enterprise knowledge. We encourage you to do that resolution in your personal setting and share your experiences within the feedback part. For extra data, go to Amazon MSK Join.
Concerning the creator

{kind=link}