
Massive Language Mannequin utility outputs might be unpredictable and hard to guage. As a LangChain developer, you may already be creating subtle chains and brokers, however to make them run reliably, you want nice analysis and debugging instruments. LangSmith is a product created by the LangChain group to handle this requirement. On this tutorial-style information, we’ll discover how LangSmith integrates with LangChain to hint and consider LLM functions, utilizing sensible examples from the official LangSmith Cookbook. We’ll cowl how you can allow tracing, create analysis datasets, log suggestions, run automated evaluations, and interpret the outcomes. Alongside the best way, we’ll examine LangSmith’s strategy to conventional analysis strategies and share finest practices for integrating it into your workflow.
What’s LangSmith?
LangSmith is an end-to-end set of instruments for constructing, debugging, and deploying LLM-enabled functions. It brings various capabilities collectively into one platform: you may monitor each step of your LLM app, check output high quality, do immediate testing, and deploy administration inside one atmosphere. LangSmith integrates properly with LangChain’s open-source libraries, nonetheless it isn’t LangChain framework focussed solely. You should use it even in proprietary LLM pipelines past LangChain and different frameworks.. By instrumenting your app with LangSmith, you may have visibility into its actions and an automatic technique of quantifying efficiency.
Not like common software program, LLM outputs might differ with the identical enter as a result of they’re probabilistic. This non-determinism makes observability and strict testing necessary for staying accountable for high quality. Outdated-school testing instruments don’t cowl it as a result of they’re not designed for the evaluations of language outputs. LangSmith solves this by providing LLM-based analysis and observability workflows. Briefly, LangSmith prevents you from sudden and unintentional mishappening, it lets you statistically measure your LLM utility’s efficiency and resolve points earlier than any mishappening
Tracing and Debugging LLM Functions
One in every of LangSmith’s key elements is tracing, which information each step and LLM name in your utility for debugging. When utilizing LangChain, turning on LangSmith tracing is easy: you need to use atmosphere variables (LANGCHAIN_API_KEY and LANGCHAIN_TRACING_V2=true) to robotically ahead LangChain runs to LangSmith. Alternatively, you may instantly instrument your code utilizing the LangSmith SDK.
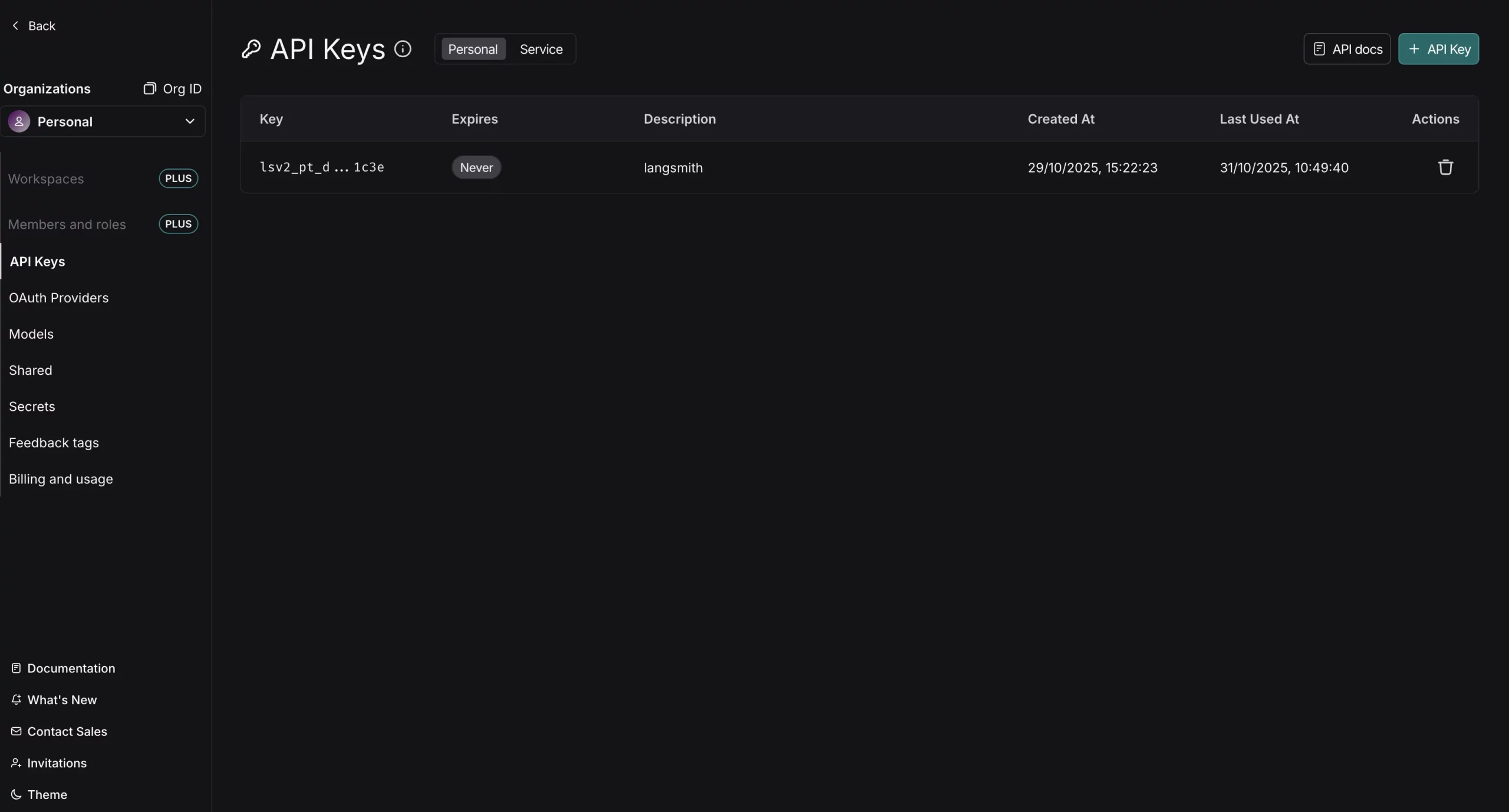
Head over to https://smith.langchain.com, create a brand new account or login. Now, go to settings from the appropriate down house and you can see the API keys part. Now create a brand new API Key and retailer it someplace.
os.environ['OPENAI_API_KEY'] = “YOUR_OPENAI_API_KEY”
os.environ['LANGCHAIN_TRACING_V2'] = “true”
os.environ['LANGCHAIN_API_KEY'] = “YOUR_LANGSMITH_API_KEY”
os.environ['LANGCHAIN_PROJECT'] = 'demo-langsmith'We’ve got configured the API keys right here and now we’re able to hint our LLM calls. Let’s check a easy instance. For example, wrapping your LLM consumer and features ensures each response and request is traced:
import openai
from langsmith.wrappers import wrap_openai
from langsmith import traceable
consumer = wrap_openai(openai.OpenAI())
@traceable
def example_pipeline(user_input: str) -> str:
response = consumer.chat.completions.create(
mannequin="gpt-4o-mini",
messages=[{"role": "user", "content": user_input}]
)
return response.selections[0].message.content material
reply = example_pipeline("Hi there, world!")We wrapped the OpenAI consumer utilizing wrap_openai, and the @traceable decorator to hint our pipeline perform. This may log a hint to LangSmith each time example_pipeline is invoked (and each inner LLM API name). Traces permit you to evaluation the chain of prompts, mannequin outputs, software calls, and so on., which is value its weight in gold when debugging difficult chains.

LangSmith’s structure allows tracing from the beginning of improvement, wrap your LLM perform and calls early on with the intention to see what your system is doing. Should you’re constructing a LangChain app in prototype, you may allow tracing with minimal work and start to catch issues nicely earlier than you attain manufacturing.
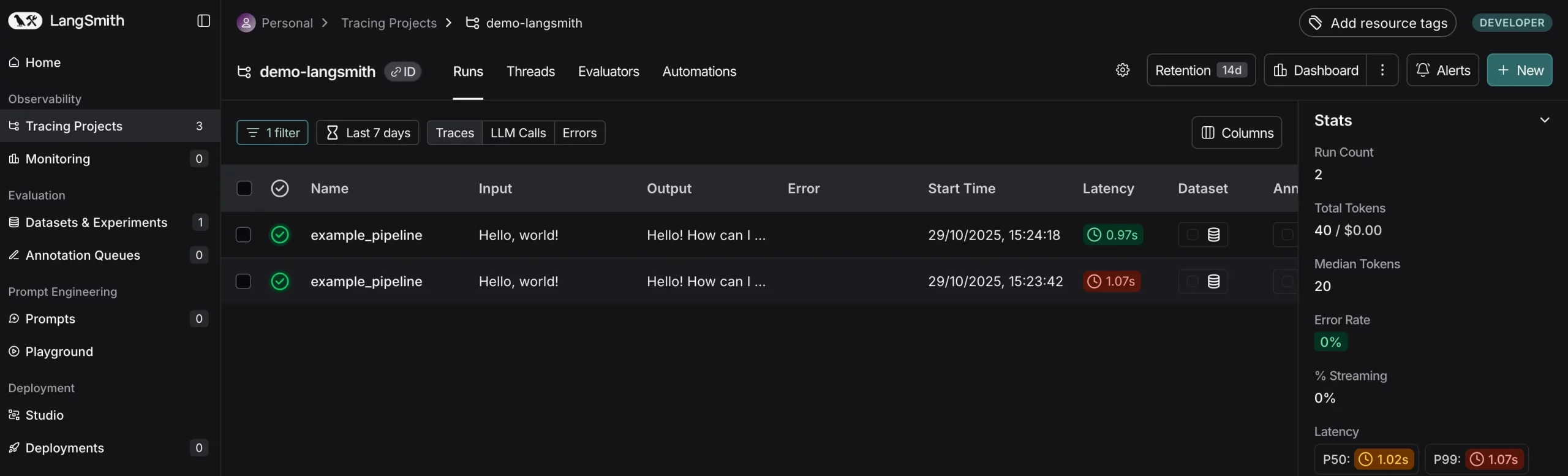
Every hint is structured as a tree of runs (a root run for the top-level name and little one runs for every internal name). In LangSmith‘s UI, you may see these traces step-by-step, observe inputs and outputs at every step, and even add notes or suggestions. This tight integration of tracing and debugging signifies that when an analysis (which we’ll cowl subsequent) flags a foul output, you may soar straight into the corresponding hint to diagnose the issue.

Creating Analysis Datasets
To check your LLM app systematically, you require a check instance dataset. In LangSmith, a Dataset is only a set of examples, with every instance containing an enter (the parameters you cross to your utility) and an anticipated or reference output. Check datasets might be small and hand-selected or giant and extracted from precise utilization. In actuality, most groups start with a couple of dozen necessary check circumstances that tackle frequent and edge circumstances, even 10-20 cleverly chosen examples might be very useful for regression testing
LangSmith simplifies dataset creation. You may insert examples instantly by means of code or the interface, and you’ll even retailer actual traces from debugging or manufacturing instantly right into a dataset for use in future testing. For instance, if in a consumer question, you discover there was a flaw in your agent’s reply, you may report that hint as a brand new check case (with the correct anticipated reply) in order that the error will get corrected and doesn’t get repeated. Datasets are principally the bottom fact towards which your LLM app shall be judged sooner or later
Let’s go over writing a easy dataset in code. With the LangSmith Python SDK, we first arrange a consumer after which outline a dataset with some examples:
!pip set up -q langsmith
from langsmith import Shopper
consumer = Shopper()
# Create a brand new analysis dataset
dataset = consumer.create_dataset("Pattern Dataset", description="A pattern analysis dataset.")
# Insert examples into the dataset: every instance has 'inputs' and 'outputs'
consumer.create_examples(
dataset_id=dataset.id,
examples=[
{
"inputs": {"postfix": "to LangSmith"},
"outputs": {"output": "Welcome to LangSmith"}
},
{
"inputs": {"postfix": "to Evaluations in LangSmith"},
"outputs": {"output": "Welcome to Evaluations in LangSmith"}
}
]
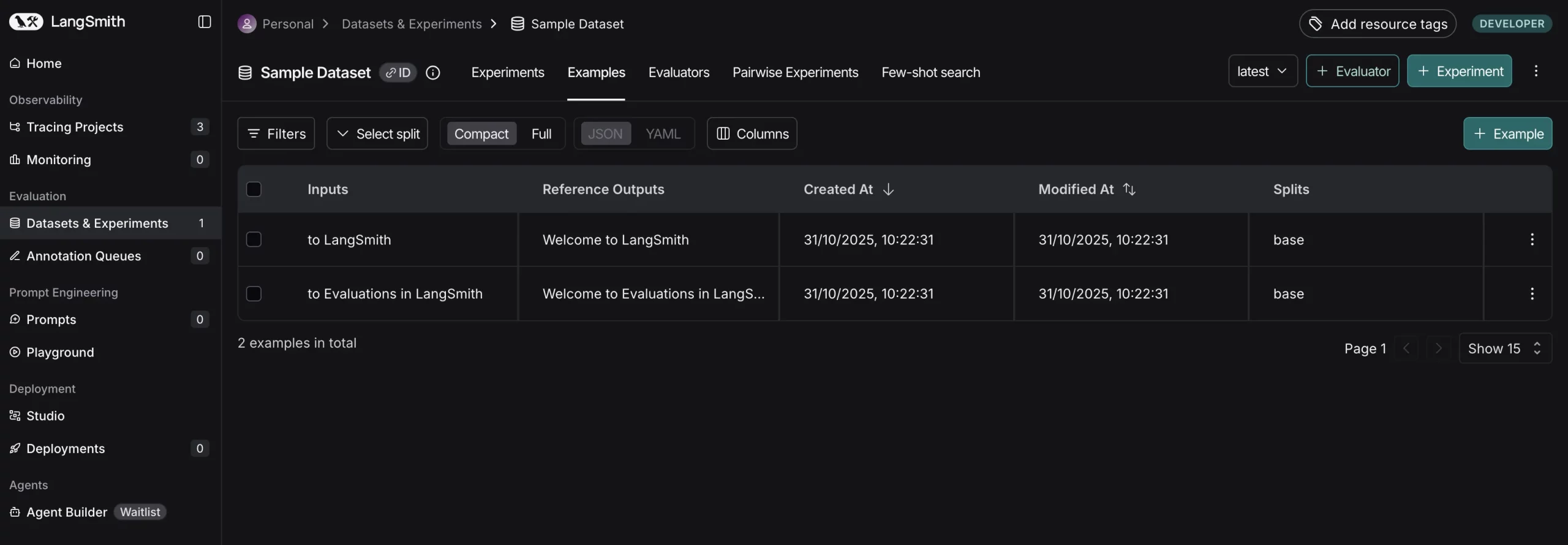
)On this toy knowledge set, the enter provides a postfix string, and the output needs to be a greeting message starting with “Welcome “. We’ve got two examples, however you could embody as many as you want. Internally, LangSmith caches every instance along with the enter JSON and output JSON. The keys of the enter dict have to match the parameters your utility accepts. Keys within the output dict are the reference output (superb or right reply for the given enter). In our case, we wish the app to only add “Welcome ” to the start of the postfix.
Output:

This knowledge set is now saved in your LangSmith workspace (with the label “Pattern Dataset”). You may see it within the LangSmith UI.

Now inside this dataset we will see all examples together with their inputs/anticipated outputs.
Instance: We are able to additionally create an analysis dataset from our Manufacturing Traces. To construct datasets from actual traces (e.g., failed consumer interactions), use the SDK to learn traces and create examples. Assume you may have a hint ID from the UI:
from langsmith import Shopper
consumer = Shopper()
# Fetch a hint by ID (substitute along with your hint ID)
hint = consumer.read_run(run_id="your-trace-run-id", project_name="demo-langsmith")
# Create dataset from the hint (add anticipated output manually)
dataset = consumer.create_dataset("Hint-Based mostly Dataset", description="From manufacturing traces.")
consumer.create_examples(
dataset_id=dataset.id,
examples=[
{
"inputs": {"input": trace.inputs}, # e.g., user query
"outputs": {"output": "Expected corrected response"} # Manually add ground truth
}
]
)We at the moment are able to specify how we measure the mannequin’s efficiency on such examples.
Writing Analysis Metrics with Evaluators
LangSmith evaluators are tiny features (or packages) that grade outputs of your app for a selected instance. An evaluator could also be as easy as verifying if the output is equivalent to the anticipated textual content, or as superior as using a distinct LLM to guage the output’s high quality. LangSmith accommodates each customized evaluators and inner ones. It’s possible you’ll create your individual Python/TypeScript perform to execute any analysis logic and execute it by means of the SDK, or make the most of LangSmith’s inner evaluators throughout the UI for in style metrics. For instance, LangSmith has some out-of-the-box evaluators for issues like similarity comparability, factuality checking, and so on., however on this case we are going to develop a customized one for the sake of instance.
Given our easy pattern job (the output should precisely match “Welcome X” for enter X), we will make a precise match evaluator. This evaluator will verify the mannequin output towards the reference output and return a rating of success or failure:
from langsmith.schemas import Run, Instance
# Create an evaluator perform for actual string match
def exact_match(run: Run, instance: Instance) -> dict:
# 'run.outputs' is the true output from the mannequin run
# 'instance.outputs' is the anticipated output from the dataset
return {"key": "exact_match", "rating": run.outputs["output"] == instance.outputs["output"]}Right here on this Python evaluator, we get a run (which holds the mannequin’s outputs for a selected instance) and the instance (which holds the anticipated outputs). We then examine the 2 strings and return a dict with a “rating” key. LangSmith requires evaluators to return a dict of measures; we use a boolean consequence right here, however you may return a numeric rating and even a number of measures if applicable. We are able to interpret the results of {“rating”: True} as a cross, and False as a fail for this check.
Notice: If we have been to have a extra subtle evaluation, we might calculate a proportion match or score. LangSmith leaves it as much as you to specify what the rating represents. For instance, you may return {“accuracy”: 0.8} or {“BLEU”: 0.67} for translation work, and even textual suggestions. For simplicity, our actual match merely returns a boolean rating.
The power of LangSmith’s analysis framework is you could insert any logic right here. Some in style strategies are:
- Gold Commonplace Comparability: In case your knowledge set does comprise a reference resolution (like ours does), then you may examine the mannequin output instantly with the reference (actual match or by way of similarity measures). That is what we’ve performed above
- LLM-as-Choose: You may make the most of a second LLM to grade the response towards a immediate or rubric. For example, for open-ended questions, you may ask an evaluator mannequin the consumer question, the mannequin’s response, and request a rating or verdict
- Useful Checks: Evaluators might be written to verify format or structural correctness. For instance, if the duty requires a JSON response, an evaluator can attempt to parse the JSON and return {”rating”: True} provided that the parsing is profitable (guaranteeing the mannequin didn’t hallucinate a flawed format.
- Human-in-the-loop Suggestions: Whereas not strictly a code evaluator within the classical sense, LangSmith additionally facilitates human analysis by means of an annotation interface, through which human reviewers can present scores to output (these scores are consumed as suggestions in the identical system).
That is useful for refined standards comparable to “helpfulness” or “model” that it’s tough to encode in code.
At present, our exact_match perform is ample for testing the pattern dataset. We’d additionally specify abstract evaluators which calculate a worldwide measure over the whole dataset (comparable to an total precision or accuracy). In LangSmith, a abstract evaluator is handed the record of all runs and all examples and returns a dataset-level measure (e.g. whole accuracy = right predictions / whole). We received’t be doing so right here, however bear in mind LangSmith does permit it (e.g., by means of a summary_evaluators param we’ll have a look at later). Generally automated aggregation like imply rating will get executed, however you may tailor additional if obligatory.
For subjective duties, we will use an LLM to attain outputs. Set up: pip set up langchain-openai. Outline a decide:
from langchain_openai import ChatOpenAI
from langsmith.schemas import Run, Instance
llm = ChatOpenAI(mannequin="gpt-4o-mini")
def llm_judge(run: Run, instance: Instance) -> dict:
immediate = f"""
Charge the standard of this response on a scale of 1-10 for relevance to the enter.
Enter: {instance.inputs}
Reference Output: {instance.outputs['output']}
Generated Output: {run.outputs['output']}
Reply with only a quantity.
"""
rating = int(llm.invoke(immediate).content material.strip())
return {"key": "relevance_score", "rating": rating / 10.0} # Normalize to 0-1This makes use of gpt-4o-mini to evaluate relevance, returning a float rating. Combine it into evaluations for non-exact duties.
Working Evaluations with LangSmith
Having a dataset ready and evaluators established, we will now carry out the analysis. LangSmith affords an consider perform (and an equal Shopper.consider technique) to handle this. Once you invoke consider, LangSmith will execute every instance within the dataset, apply your utility on the enter of the instance, retrieve the output, then invoke every evaluator on the output to generate scores. All these executes and scores shall be logged in LangSmith so that you can study.
Let’s run an analysis for our pattern utility. Suppose our utility is simply the perform: lambda enter: “Welcome ” + enter[‘postfix’] (which is what we wish it to do). We’ll present that because the goal to guage with our dataset title and the evaluators record:
from langsmith.analysis import consider
# Outline the goal perform to guage (our "utility below check")
def generate_welcome(inputs: dict) -> dict:
# The perform returns a dict of outputs just like an precise chain would
return {"output": "Welcome " + inputs["postfix"]}
# Use the analysis on the dataset with our evaluator
outcomes = consider(
generate_welcome,
knowledge="Pattern Dataset", # we will entry the dataset by title
evaluators=[exact_match], # use our exact_match evaluator
experiment_prefix="sample-eval", # label for this analysis run
metadata={"model": "1.0.0"} # non-obligatory metadata tags
)Output:

After efficiently operating the experiment you’ll get a hyperlink to the detailed breakdown of the experiment like this:
A number of issues happen once we execute this code:
- Calling the goal: For each instance in “Pattern Dataset”, the generate_welcome perform is named with the instance’s inputs. The perform returns an output dict (on this instance merely{“output”: “Welcome .”}). In an precise utility, this may be an invocation of an LLM or a LangChain chain, for example, you could provide an agent or chain object because the goal moderately than a fundamental perform. LangSmith is flexible: the goal could also be a perform, a LangChain Runnable, and even a whole beforehand executed chain run (for comparability assessments)
- Scoring utilizing evaluators: On each run, LangSmith calls the exact_match evaluator, giving it the run and instance. Our evaluator returns a rating (True/False). In case we had a couple of evaluator, every would give its personal rating/suggestions for a given run.
- Recording outcomes: LangSmith information all this knowledge as an Experiment in its system. An Experiment is principally a set of runs (one per instance within the dataset) plus all of the suggestions scores from evaluators. In our code, we provided an experiment_prefix of “sample-eval”. LangSmith will construct an experiment with a particular title like sample-eval-
(or add to an present experiment for those who favor). We additionally appended a metadata tag model: 1.0.0 – that is helpful for understanding which model of our utility or immediate was examined - Analysis at Scale: The above instance is tiny, however LangSmith is designed for bigger evaluations. When you have a number of hundred or 1000’s of check circumstances, you could favor to execute evaluations within the background asynchronously. LangSmith SDK gives an
aevaluatetechnique for Python which behaves just likeconsiderhowever executes the roles in parallel.
You can even use the max_concurrency parameter to set parallelism. That is useful to speed up analysis runs, notably if each check makes a name to a reside mannequin (which is gradual). Merely pay attention to the speed limits and charges when sending plenty of mannequin calls concurrently.
Let’s take yet one more instance by Evaluating a LangChain Chain. Change the straightforward perform with a LangChain chain (set up: pip set up langchain-openai). Outline a series that may fail on edge circumstances:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langsmith.analysis import consider
llm = ChatOpenAI(mannequin="gpt-4o-mini")
immediate = PromptTemplate.from_template("Say: Welcome {postfix}")
chain = immediate | llm
# Consider the chain instantly
outcomes = consider(
chain,
knowledge="Pattern Dataset",
evaluators=[exact_match],
experiment_prefix="langchain-eval",
metadata={"chain_type": "prompt-llm"}
)
This traces the chain’s execution per instance, scoring outputs. Test for mismatches (e.g., further LLM phrasing) within the UI.
Deciphering Analysis Outcomes
As soon as it has executed an analysis, LangSmith affords to investigate the outcomes utilizing instruments. Each experiment is accessible throughout the LangSmith UI. You’ll have a desk of all examples with inputs, outputs, and suggestions scores for every evaluator.
Listed below are some methods you need to use the outcomes:
- Discover Failures: Have a look at which exams scored badly or failed. LangSmith factors these out, and you’ll filter or kind on rating. If any check failed, you may have immediate proof of a problem to right. Since LangSmith information suggestions on each hint, you may click on a failure run and study its hint for a touch.
- View Metrics: Should you return abstract evaluators (or simply need an mixture), LangSmith can show a complete metric for the experiment. For instance, for those who returned {“rating”: True/False} for each run, it might show an total accuracy (whole True proportion) for the experiment. In additional subtle evaluations, you could have a number of metrics – all of those could be seen per instance and in abstract.
- Exporting Information: LangSmith lets you question or export outcomes of evaluations by means of the SDK or API. You may, for instance, retrieve all scores of suggestions for a specific experiment and make the most of that in a bespoke report or pipeline.
Fetching Experiment Outcomes Programmatically
To entry outcomes exterior the UI, record experiments and fetch suggestions. Modify your experiment title from the UI.
from langsmith import Shopper
consumer = Shopper()
project_name = "sample-eval-d2203052" # Matches experiment_prefix
# Checklist tasks and discover the goal venture
tasks = consumer.list_projects()
target_project = None
for venture in tasks:
if venture.title == project_name:
target_project = venture
break
if target_project:
# Fetch suggestions for runs throughout the goal venture
runs = consumer.list_runs(project_name=project_name)
for run in runs:
feedbacks = consumer.list_feedback(run_id=run.id)
for fb in feedbacks:
# Entry outputs safely, dealing with potential None values
run_outputs = run.outputs if run.outputs shouldn't be None else "No outputs"
print(f"Run: {run_outputs}, Rating: {fb.rating}") # e.g., {'key': 'exact_match', 'rating': True}
else:
print(f"Venture '{project_name}' not discovered.") This prints scores per run, helpful for customized reporting or CI integration.

Outcomes interpretation shouldn’t be cross/fail; it’s understanding why the mannequin is failing on explicit inputs. Since LangSmith hyperlinks evaluation to wealthy hint knowledge and suggestions, it completes the loop so that you can intelligently debug. If, for instance, a number of failures got here on a specific query kind, that could possibly be a immediate or data base hole, one thing you may repair. If a common measure is under your threshold of acceptance, you may drill down into explicit circumstances to inquire.
LangSmith vs. Conventional LLM Analysis Practices
How does LangSmith differ from the “conventional” strategies builders use to check LLM functions? Here’s a comparability of the 2:
| Facet | Conventional Strategies | LangSmith Strategy |
|---|---|---|
| Immediate Testing | Handbook trial-and-error iteration. | Systematic, scalable immediate testing with metrics. |
| Analysis Model | One-off accuracy checks or visible inspections. | Steady analysis in dev, CI, and manufacturing. |
| Metrics | Restricted to fundamental like accuracy or ROUGE. | Customized standards together with multi-dimensional scores. |
| Debugging | No context; guide evaluation of failures. | Full traceability with traces linked to failures. |
| Software Integration | Scattered instruments and customized code. | Unified platform for tracing, testing, and monitoring. |
| Operational Components | Ignores latency/price or handles individually. | Tracks high quality alongside latency and value. |
General, LangSmith applies self-discipline and group to LLM testing. It’s like going from hand-coded exams to automated check batteries in programming. By doing so, you might be extra sure that you just’re not flying blind along with your LLM app – you may have proof to help adjustments and religion in your mannequin’s conduct throughout completely different conditions.
Finest Practices for Incorporating LangSmith into Your Workflow
To realize essentially the most from LangSmith, bear in mind the next finest practices, notably for those who’re integrating it right into a present LangChain venture:
- Activate tracing early: Arrange LangSmith tracing from day one so you may see how prompts and chains behave and debug sooner.
- Begin with a small, significant dataset: Create a handful of examples that cowl core duties and tough edge circumstances, then hold including to it as new points seem.
- Combine analysis strategies: Use exact-match checks for information, LLM-based scoring for subjective qualities, and format checks for schema compliance.
- Feed consumer suggestions again into the system: Log and tag unhealthy responses in order that they develop into future check circumstances.
- Automate regression exams: Run LangSmith evaluations in CI/CD to catch immediate or mannequin regressions earlier than they hit manufacturing.
- Model and tag every part: Label runs with immediate, mannequin, or chain variations to check efficiency over time.
- Monitor in manufacturing: Arrange on-line evaluators and alerts to catch real-time high quality drops when you go reside.
- Steadiness velocity, price, and accuracy: Evaluate qualitative and quantitative metrics to seek out the appropriate trade-offs to your use case.
- Preserve people within the loop: Periodically ship tough outputs for human evaluation and feed that knowledge again into your eval set.
By adopting these practices, you’ll bake LangSmith in as a one-time verify, but in addition as an ongoing high quality guardian throughout your LLM utility’s lifetime. From prototyping (the place you debug and iterate utilizing traces and tiny exams) to manufacturing (the place you monitor and obtain suggestions at scale), LangSmith might be included in every step to assist guarantee reliability.
Conclusion
Testing and debugging LLM functions is tough, however LangSmith makes it a lot simpler. By integrating tracing, structured datasets, automated evaluators, and suggestions logging, it affords a whole system for testing AI techniques. We have been capable of see how LangSmith might be employed to hint a LangChain app, generate reference datasets, have customized analysis metrics, and iterate quickly with considerate suggestions. This technique is an enchancment over the traditional immediate tweaking or stand-alone accuracy testing. It applies a software program engineering self-discipline to the realm of LLMs.
Able to take your LLM app’s reliability to the following stage? Strive LangSmith in your subsequent venture. Create some traces, write a few evaluators to your most necessary outputs, and conduct an experiment. What you study will allow you to iterate with certainty and ship updates supported by knowledge, not vibes. Evaluating made straightforward!
Incessantly Requested Questions
A. LangSmith is a platform for tracing, evaluating, and debugging LLM functions, integrating seamlessly with LangChain by way of atmosphere variables like LANGCHAIN_TRACING_V2 for automated run logging.
A. Set atmosphere variables comparable to LANGCHAIN_API_KEY and LANGCHAIN_TRACING_V2=”true”, then use decorators like @traceable or wrap purchasers to log each LLM name and chain step.
A. Datasets are collections of input-output examples used to check LLM apps, created by way of the SDK with consumer.create_dataset and consumer.create_examples for reference floor fact.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Massive Language Fashions than precise people. Keen about GenAI, NLP, and making machines smarter (in order that they don’t substitute him simply but). When not optimizing fashions, he’s in all probability optimizing his espresso consumption. 🚀☕
Login to proceed studying and revel in expert-curated content material.

{kind=link}