
Introduction
As massive language fashions (LLMs) advance in software program engineering duties—starting from code technology to bug fixing—efficiency optimization stays an elusive frontier, particularly on the repository degree. To bridge this hole, researchers from TikTok and collaborating establishments have launched SWE-Perf—the primary benchmark particularly designed to guage the flexibility of LLMs to optimize code efficiency in real-world repositories.
Not like prior benchmarks targeted on correctness or function-level effectivity (e.g., SWE-Bench, Mercury, EFFIBench), SWE-Perf captures the complexity and contextual depth of repository-scale efficiency tuning. It offers a reproducible, quantitative basis to review and enhance the efficiency optimization capabilities of recent LLMs.
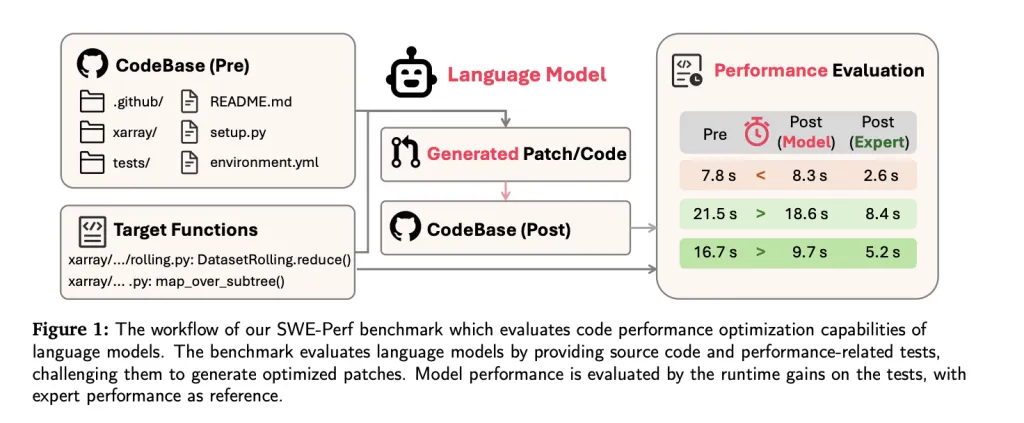
Why SWE-Perf Is Wanted
Actual-world codebases are sometimes massive, modular, and intricately interdependent. Optimizing them for efficiency requires understanding of cross-file interactions, execution paths, and computational bottlenecks—challenges past the scope of remoted function-level datasets.
LLMs immediately are largely evaluated on duties like syntax correction or small operate transformations. However in manufacturing environments, efficiency tuning throughout repositories can yield extra substantial system-wide advantages. SWE-Perf is explicitly constructed to measure LLM capabilities in such settings.
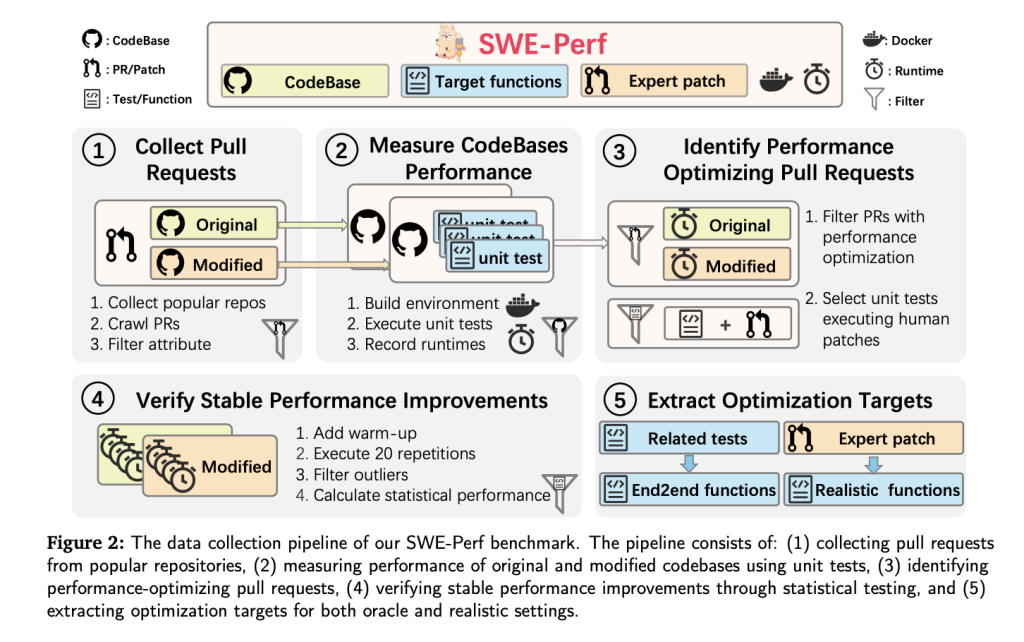
Dataset Development
SWE-Perf is constructed from over 100,000 pull requests throughout high-profile GitHub repositories. The ultimate dataset lined 9 repositories together with:
- 140 curated situations demonstrating measurable and secure efficiency enhancements.
- Full codebases pre- and post-optimization.
- Goal features categorized as oracle (file-level) or reasonable (repo-level).
- Unit assessments and Docker environments for reproducible execution and efficiency measurement.
- Professional-authored patches used as gold requirements.
To make sure validity, every unit take a look at should:

- Go earlier than and after the patch.
- Present statistically vital runtime beneficial properties over 20 repetitions (Mann-Whitney U take a look at, p
Efficiency is measured utilizing minimal efficiency achieve (δ), isolating statistical enhancements attributable to the patch whereas filtering noise.
Benchmark Settings: Oracle vs. Practical
- Oracle Setting: The mannequin receives solely the goal features and corresponding information. This setting assessments localized optimization abilities.
- Practical Setting: The mannequin is given a complete repository and should determine and optimize performance-critical paths autonomously. This can be a nearer analog to how human engineers work.
Analysis Metrics
SWE-Perf defines a three-tier analysis framework, reporting every metric independently:
- Apply: Can the model-generated patch be utilized cleanly?
- Correctness: Does the patch protect useful integrity (all unit assessments move)?
- Efficiency: Does the patch yield measurable runtime enchancment?
The metrics are usually not aggregated right into a single rating, permitting extra nuanced analysis of tradeoffs between syntactic correctness and efficiency beneficial properties.
Experimental Outcomes
The benchmark evaluates a number of top-tier LLMs beneath each oracle and reasonable settings:
| Mannequin | Setting | Efficiency (%) |
|---|---|---|
| Claude-4-opus | Oracle | 1.28 |
| GPT-4o | Oracle | 0.60 |
| Gemini-2.5-Professional | Oracle | 1.48 |
| Claude-3.7 (Agentless) | Practical | 0.41 |
| Claude-3.7 (OpenHands) | Practical | 2.26 |
| Professional (Human Patch) | – | 10.85 |
Notably, even the best-performing LLM configurations fall considerably in need of human-level efficiency. The agent-based technique OpenHands, constructed on Claude-3.7-sonnet, outperforms different configurations within the reasonable setting however nonetheless lags behind expert-crafted optimizations.
Key Observations
- Agent-based frameworks like OpenHands are higher suited to complicated, multi-step optimization, outperforming direct mannequin prompts and pipeline-based approaches like Agentless.
- Efficiency degrades because the variety of goal features will increase—LLMs battle with broader optimization scopes.
- LLMs exhibit restricted scalability in long-runtime situations, the place skilled programs proceed to point out efficiency beneficial properties.
- Patch evaluation exhibits LLMs focus extra on low-level code buildings (e.g., imports, setting setup), whereas specialists goal high-level semantic abstractions for efficiency tuning.
Conclusion
SWE-Perf represents a pivotal step towards measuring and bettering the efficiency optimization capabilities of LLMs in reasonable software program engineering workflows. It uncovers a big functionality hole between current fashions and human specialists, providing a robust basis for future analysis in repository-scale efficiency tuning. As LLMs evolve, SWE-Perf can function a north star guiding them towards sensible, production-ready software program enhancement at scale.
Try the Paper, GitHub Web page and Undertaking. All credit score for this analysis goes to the researchers of this mission.
Sponsorship Alternative: Attain probably the most influential AI builders in US and Europe. 1M+ month-to-month readers, 500K+ group builders, infinite potentialities. [Explore Sponsorship]
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}