
(Credit: TigerData.com)
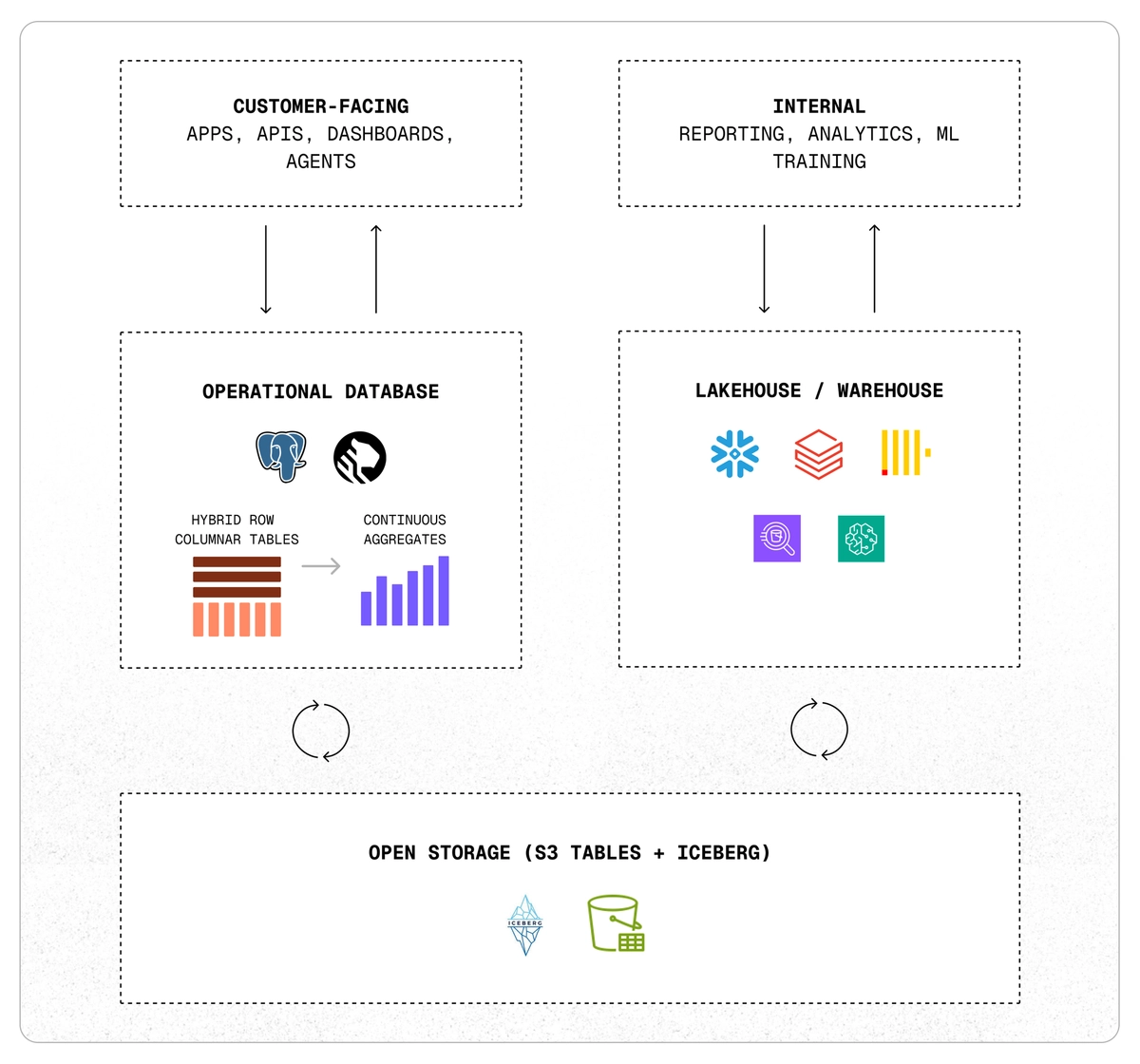
TigerData immediately launched Tiger Lake, an structure it calls “the lacking layer between Postgres and the lakehouse for the age of brokers.” The discharge is a part of the corporate’s effort to make it simpler for builders to work with each real-time and historic information with out counting on fragile pipelines or delayed batch syncing.
Tiger Lake is constructed straight into Tiger Postgres, the corporate’s personalized model of PostgreSQL designed for real-time and analytical workloads. Based on TigerData, the brand new structure permits Postgres to sync with Iceberg-backed lakehouses like AWS S3 in each instructions. The structure presently provides native help for AWS S3 Tables, with integration for different lakehouse codecs anticipated in future updates.
The objective with Tiger Lake is to present builders a less complicated approach to construct purposes, dashboards, and AI brokers that rely on each recent operational information and long-term analytical insights. TigerData says the structure is supposed to cut back complexity whereas preserving information programs versatile and open.
As co-founder and CTO Mike Freedman explains, Postgres has develop into the operational coronary heart of many trendy purposes, however it has remained remoted from the lakehouse layer. “With Tiger Lake, we’ve constructed a local, bidirectional bridge between Postgres and the lakehouse,” he stated. “It’s the structure we consider the trade has been ready for.”
Many groups presently depend on a patchwork of instruments to maneuver information between programs, typically utilizing Kafka, Flink, or customized scripts. That form of setup might be fragile and costly to take care of. TigerData says Tiger Lake replaces that complexity with built-in, real-time sync throughout Postgres and Iceberg.
(Credit:TigerData.com)
That was a key motivator for Speedcast. “We stitched collectively Kafka, Flink, and customized code to stream information from Postgres to Iceberg—it labored, however it was fragile and high-maintenance,” stated Kevin Otten, Director of Technical Structure at Speedcast. “Tiger Lake replaces all of that with native infrastructure. It’s not simply less complicated—it’s the structure we want we had from day one.”
Past syncing tables, a key function of Tiger Lake is its capacity to help a two-way circulation of data. Operational information strikes into the lakehouse for long-term storage or evaluation, whereas outcomes, like aggregates, ML options, or historic summaries, might be pushed again into Postgres to be used in reside purposes.
TigerData emphasizes that one of many major benefits of utilizing Tiger Lake is that it permits customers to keep away from vendor lock-in. It makes use of open codecs like Iceberg, runs on AWS S3, and connects with present ecosystems for machine studying, monitoring, and analytics. Builders don’t must rebuild their stack or swap platforms to make use of it.
This launch additionally displays broader shifts within the information world. Postgres continues to rise in reputation for operational workloads, whereas Iceberg is gaining floor as the usual for open lakehouses. With extra AI-driven apps needing entry to each latest context and deep historic perception, Tiger Lake positions itself because the connective tissue between these layers.
For ML groups that want recent options, analytics teams working with long-range traits, or builders constructing AI brokers and dashboards, Tiger Lake may make it simpler to attach totally different information programs with out having to handle complicated integrations.
If we zoom out a bit, the introduction of Tiger Lake aligns with TigerData’s broader focus. The corporate initially launched as Timescale in 2017, gaining recognition for its time-series extensions to PostgreSQL. However because it expanded into vector search, real-time analytics, and AI-native workloads, the workforce rebranded to TigerData earlier this yr to higher replicate its wider ambitions.

(Shutterstock AI Picture)
“Trendy purposes don’t match neatly into conventional database classes. They seize huge streams of knowledge, energy real-time analytics, and more and more depend on clever brokers that cause and act. These workloads—transactional, analytic, and agentic—require a brand new form of operational database,” stated Ajay Kulkarni, Co-founder and CEO. “That’s precisely what we’ve constructed at TigerData: a system that delivers velocity with out sacrifice.”
TigerData has grown to now serve greater than 2,000 organizations, together with Mistral, HuggingFace, Nvidia, Toyota, Tesla, NASA, JP Morgan Chase, Schneider Electrical, Palo Alto Networks, and Caterpillar. It’s also an AWS Accomplice with options accessible on AWS Market. The corporate has raised over $180 million from backers like Benchmark, NEA, Redpoint, and Tiger World.
The corporate says Tiger Lake is just the start. Future updates will embrace the flexibility to question Iceberg catalogs straight, ship analytical outcomes again into Postgres, and develop help for Iceberg-based workflows. TigerData can also be engaged on efficiency upgrades, together with sooner large-scale inserts and a brand new storage structure designed to make forks and replicas extra environment friendly.
Associated Gadgets
AI One Emerges from Stealth to “Finish the Information Lake Period”
Rethinking Danger: The Position of Selective Retrieval in Information Lake Methods
ETL vs ELT for Telemetry Information: Technical Approaches and Sensible Tradeoffs

{kind=link}