

Dealing with questions that contain each pure language and structured tables has grow to be an important activity in constructing extra clever and helpful AI methods. These methods are sometimes anticipated to course of content material that features various information sorts, corresponding to textual content blended with numerical tables, that are generally present in enterprise paperwork, analysis papers, and public stories. Understanding such paperwork requires the AI to carry out reasoning that spans each textual explanations and table-based particulars—a course of that’s inherently extra difficult than conventional text-based query answering.
One of many main issues on this space is that present language fashions usually fail to interpret paperwork precisely when tables are concerned. Fashions are likely to lose the relationships between rows and columns when the tables are flattened into plain textual content. This distorts the underlying construction of the information and reduces the accuracy of solutions, particularly when the duty includes computations, aggregations, or reasoning that connects a number of information throughout the doc. Such limitations make it difficult to make the most of commonplace methods for sensible multi-hop question-answering duties that require insights from each textual content and tables.

To unravel these issues, earlier strategies have tried to use Retrieval-Augmented Technology (RAG) strategies. These contain retrieving textual content segments and feeding them right into a language mannequin for reply era. Nonetheless, these strategies are inadequate for duties that require compositional or international reasoning throughout giant tabular datasets. Instruments like NaiveRAG and TableGPT2 attempt to simulate this course of by changing tables into Markdown format or producing code-based execution in Python. But, these strategies nonetheless wrestle with duties the place sustaining the desk’s authentic construction is important for proper interpretation.
Researchers from Huawei Cloud BU proposed a technique named TableRAG that instantly addresses these limitations. Analysis launched TableRAG as a hybrid system that alternates between textual information retrieval and structured SQL-based execution. This method preserves the tabular structure and treats table-based queries as a unified reasoning unit. This new system not solely preserves the desk construction but in addition executes queries in a way that respects the relational nature of information, organized in rows and columns. The researchers additionally created a dataset referred to as HeteQA to benchmark the efficiency of their methodology throughout totally different domains and multi-step reasoning duties.
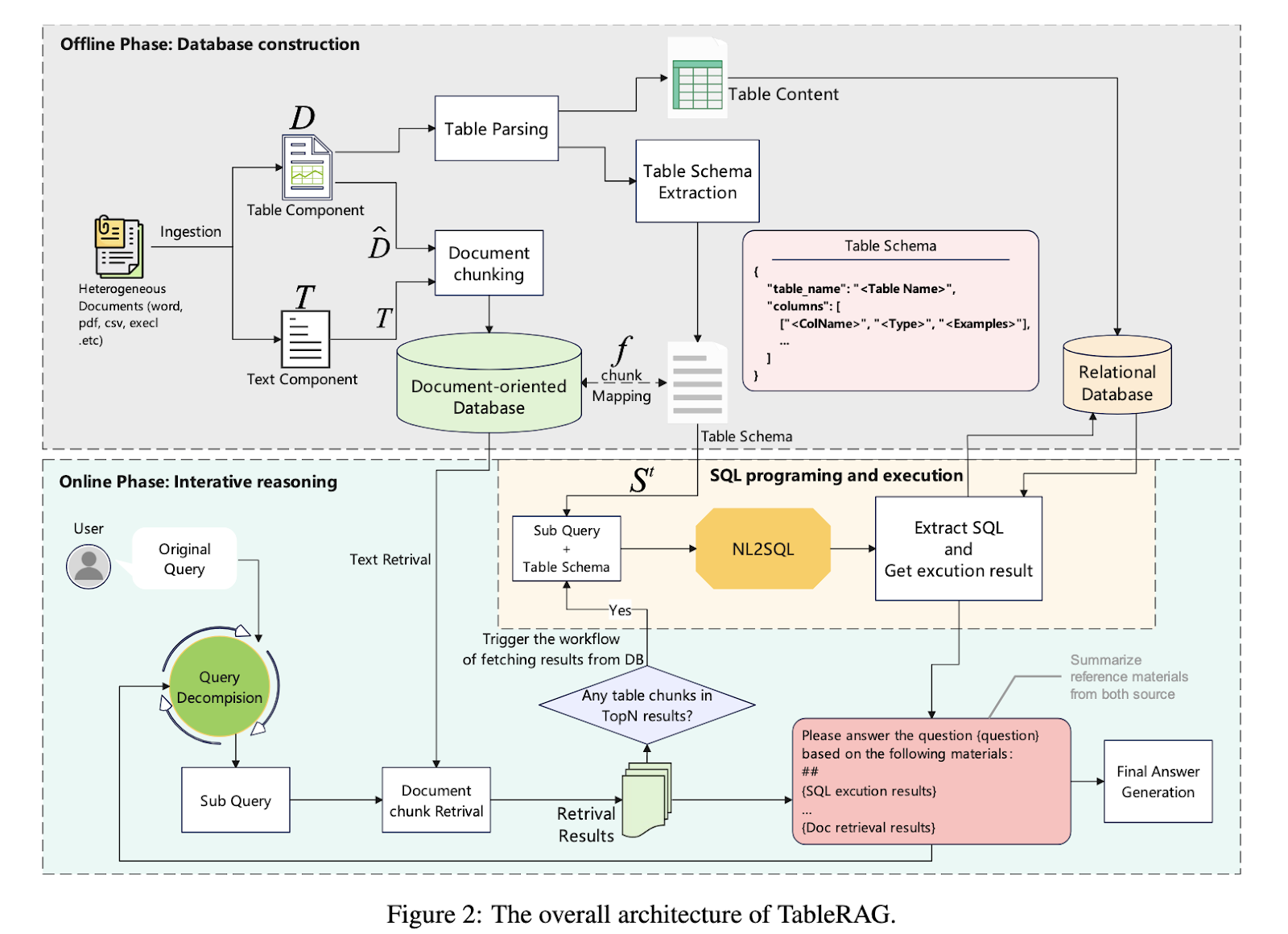
TableRAG features in two principal phases. The offline stage includes parsing heterogeneous paperwork into structured databases by extracting tables and textual content material individually. These are saved in parallel corpora—a relational database for tables and a chunked information base for textual content. The net part handles consumer questions by way of an iterative four-step course of: question decomposition, textual content retrieval, SQL programming and execution, and intermediate reply era. When a query is obtained, the system identifies whether or not it requires tabular or textual reasoning, dynamically chooses the suitable technique, and combines the outputs. SQL is used for exact symbolic execution, enabling higher efficiency in numerical and logical computations.
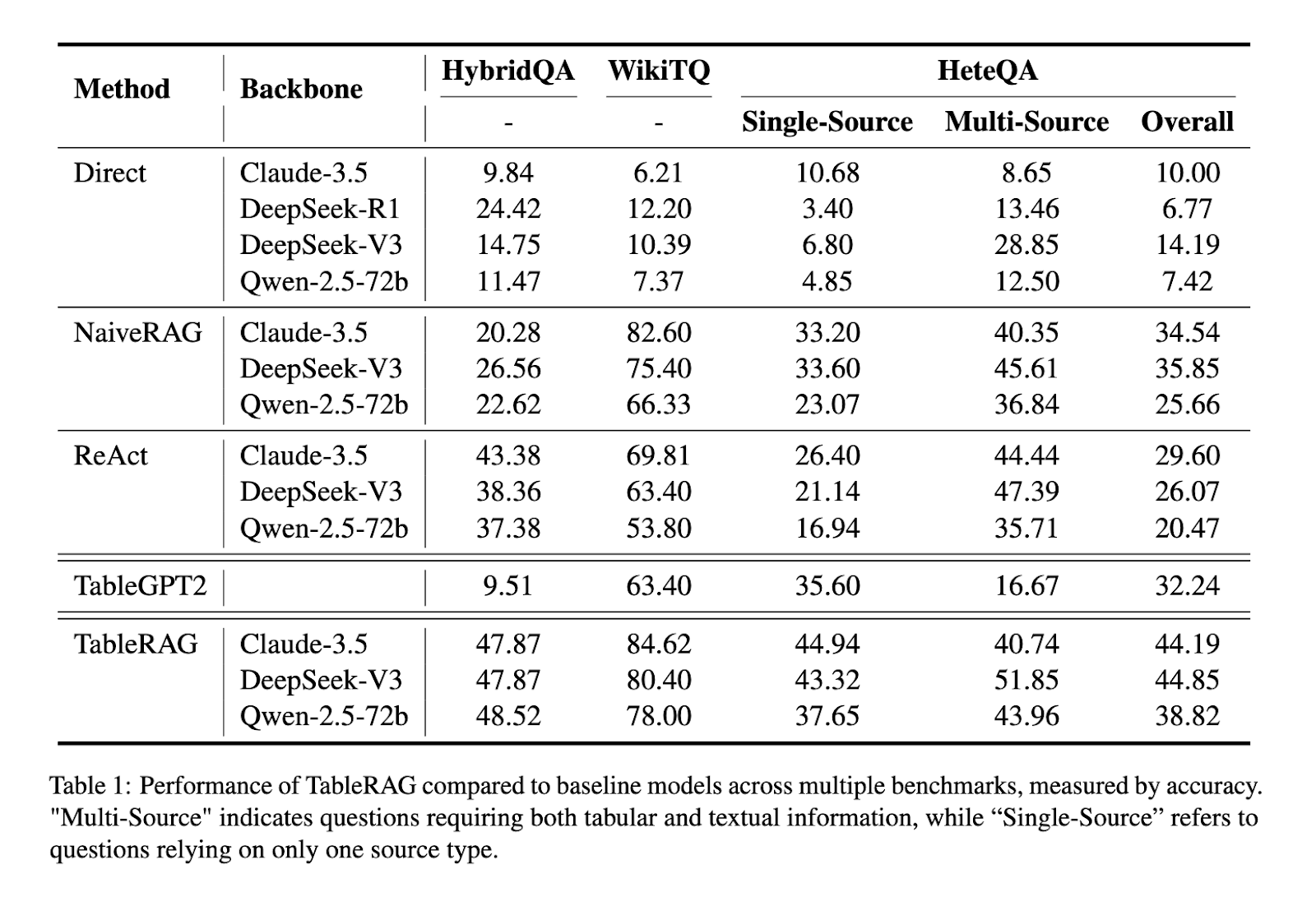
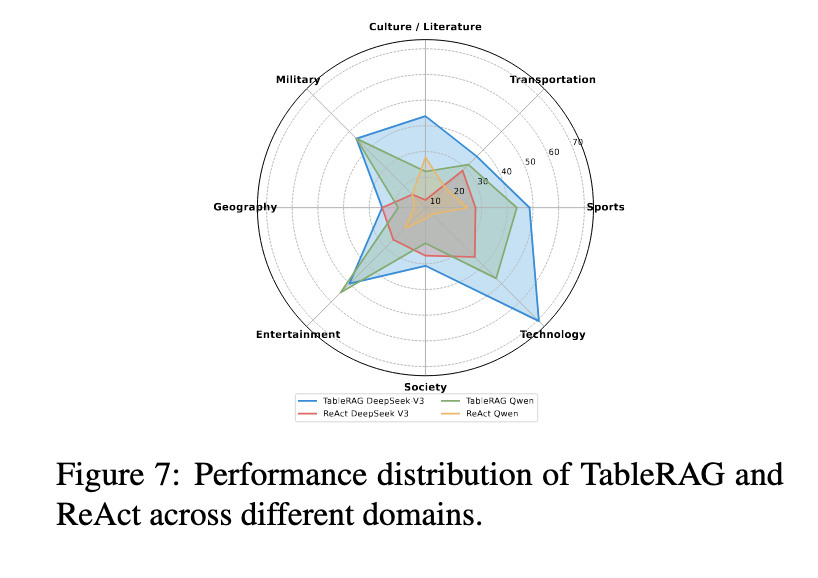
Throughout experiments, TableRAG was examined on a number of benchmarks, together with HybridQA, WikiTableQuestions, and the newly constructed HeteQA. HeteQA consists of 304 complicated questions throughout 9 various domains and contains 136 distinctive tables, in addition to over 5,300 Wikipedia-derived entities. The dataset challenges fashions with duties like filtering, aggregation, grouping, calculation, and sorting. TableRAG outperformed all baseline strategies, together with NaiveRAG, React, and TableGPT2. It achieved constantly larger accuracy, with document-level reasoning powered by as much as 5 iterative steps, and utilized fashions corresponding to Claude-3.5-Sonnet and Qwen-2.5-72B to confirm the outcomes.
The work introduced a powerful and well-structured answer to the problem of reasoning over mixed-format paperwork. By sustaining structural integrity and adopting SQL for structured information operations, the researchers demonstrated an efficient different to present retrieval-based methods. TableRAG represents a major step ahead in question-answering methods that deal with paperwork containing each tables and textual content, providing a viable methodology for extra correct, scalable, and interpretable doc understanding.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Prepared to attach with 1 Million+ AI Devs/Engineers/Researchers? See how NVIDIA, LG AI Analysis, and high AI firms leverage MarkTechPost to achieve their audience [Learn More]
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.

{kind=link}