
Understanding Subgroup Equity in Machine Studying ML
Evaluating equity in machine studying usually includes analyzing how fashions carry out throughout completely different subgroups outlined by attributes equivalent to race, gender, or socioeconomic background. This analysis is important in contexts equivalent to healthcare, the place unequal mannequin efficiency can result in disparities in remedy suggestions or diagnostics. Subgroup-level efficiency evaluation helps reveal unintended biases that could be embedded within the information or mannequin design. Understanding this requires cautious interpretation as a result of equity isn’t nearly statistical parity—it’s additionally about guaranteeing that predictions result in equitable outcomes when deployed in real-world methods.
Information Distribution and Structural Bias
One main problem arises when mannequin efficiency differs throughout subgroups, not as a consequence of bias within the mannequin itself however due to actual variations within the subgroup information distributions. These variations usually replicate broader social and structural inequities that form the information out there for mannequin coaching and analysis. In such situations, insisting on equal efficiency throughout subgroups may result in misinterpretation. Moreover, if the information used for mannequin growth just isn’t consultant of the goal inhabitants—as a consequence of sampling bias or structural exclusions—then fashions might generalize poorly. Inaccurate efficiency on unseen or underrepresented teams can introduce or amplify disparities, particularly when the construction of the bias is unknown.
Limitations of Conventional Equity Metrics
Present equity evaluations usually contain disaggregated metrics or conditional independence assessments. These metrics are broadly utilized in assessing algorithmic equity, together with accuracy, sensitivity, specificity, and optimistic predictive worth, throughout numerous subgroups. Frameworks like demographic parity, equalized odds, and sufficiency are widespread benchmarks. For instance, equalized odds make sure that true and false optimistic charges are comparable throughout teams. Nevertheless, these strategies can produce deceptive conclusions within the presence of distribution shifts. If the prevalence of labels differs amongst subgroups, even correct fashions may fail to fulfill sure equity standards, main practitioners to imagine bias the place none exists.
A Causal Framework for Equity Analysis
Researchers from Google Analysis, Google DeepMind, New York College, Massachusetts Institute of Expertise, The Hospital for Sick Youngsters in Toronto, and Stanford College launched a brand new framework that enhances equity evaluations. The analysis launched causal graphical fashions that explicitly mannequin the construction of information technology, together with how subgroup variations and sampling biases affect mannequin habits. This method avoids assumptions of uniform distributions and offers a structured approach to perceive how subgroup efficiency varies. The researchers suggest combining conventional disaggregated evaluations with causal reasoning, encouraging customers to assume critically in regards to the sources of subgroup disparities relatively than relying solely on metric comparisons.
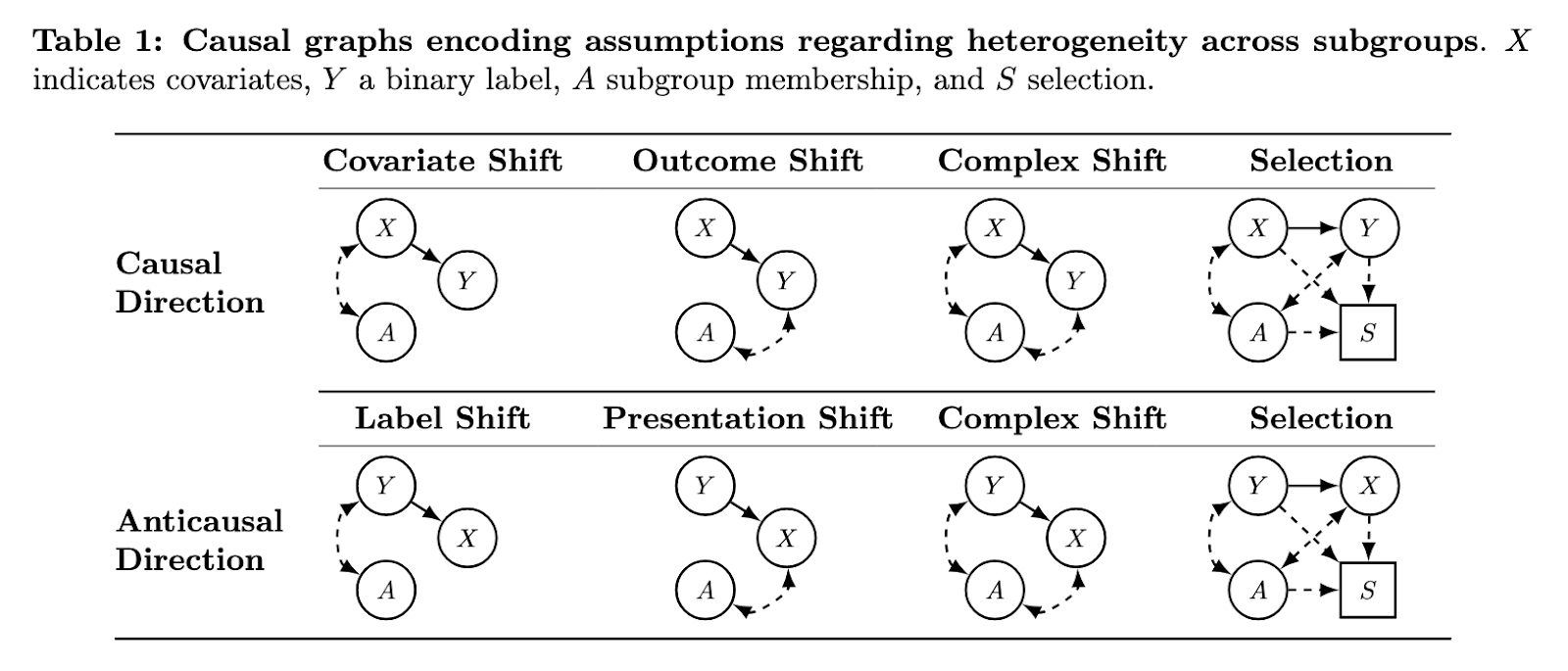
Forms of Distribution Shifts Modeled
The framework categorizes forms of shifts equivalent to covariate shift, final result shift, and presentation shift utilizing causal-directed acyclic graphs. These graphs embrace key variables like subgroup membership, final result, and covariates. As an example, covariate shift describes conditions the place the distribution of options differs throughout subgroups, however the relationship between the end result and the options stays fixed. Consequence shift, against this, captures instances the place the connection between options and outcomes adjustments by subgroup. The graphs additionally accommodate label shift and choice mechanisms, explaining how subgroup information could also be biased in the course of the sampling course of. These distinctions permit researchers to foretell when subgroup-aware fashions would enhance equity or once they will not be vital. The framework systematically identifies the situations below which normal evaluations are legitimate or deceptive.
Empirical Analysis and Outcomes
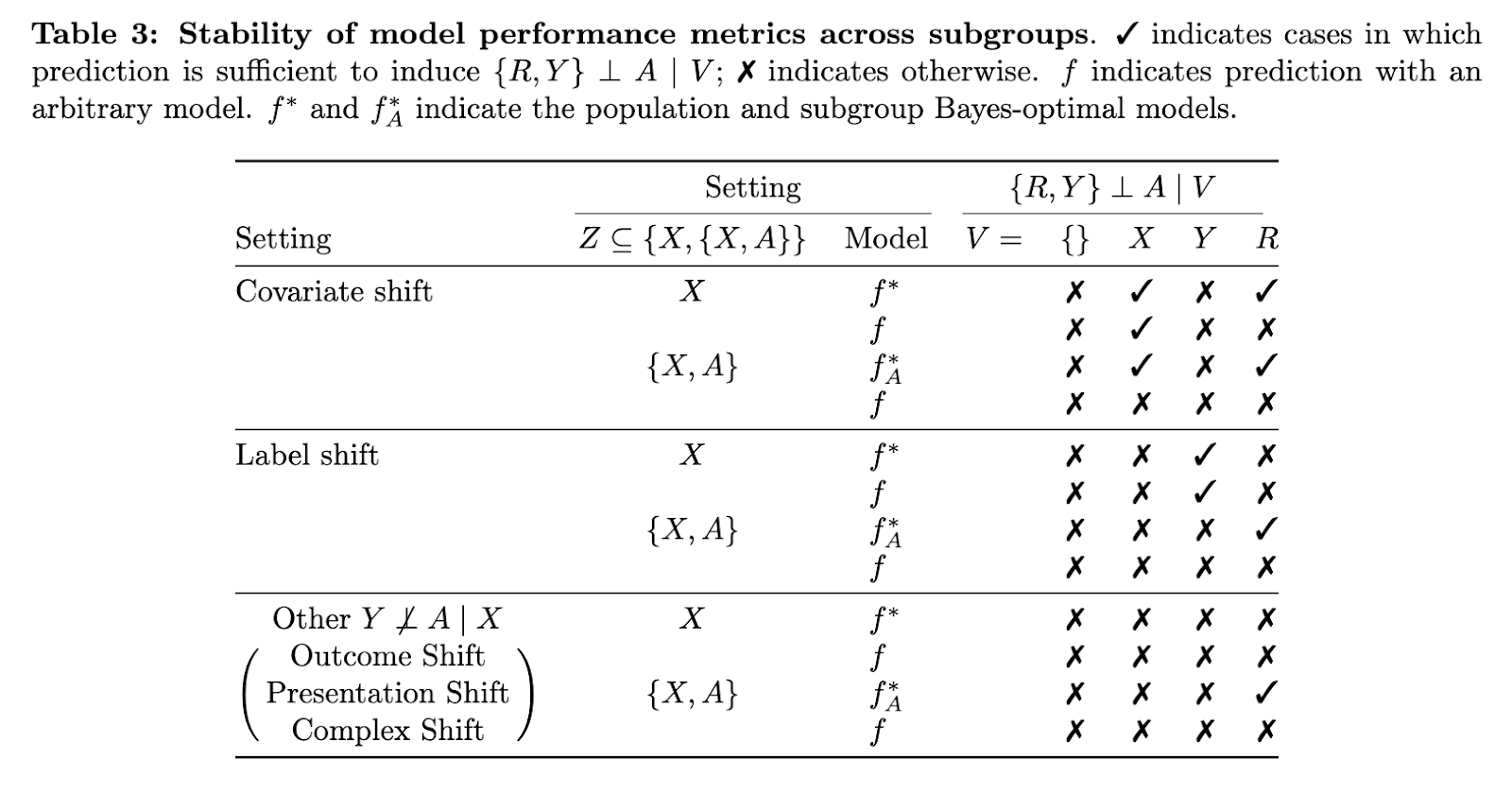
Of their experiments, the workforce evaluated Bayes-optimal fashions below numerous causal buildings to look at when equity situations, equivalent to sufficiency and separation, maintain. They discovered that sufficiency, outlined as Y ⊥ A | f*(Z), is glad below covariate shift however not below different forms of shifts equivalent to final result or complicated shift. In distinction, separation, outlined as f*(Z) ⊥ A | Y, solely held below label shift when subgroup membership wasn’t included in mannequin enter. These outcomes present that subgroup-aware fashions are important in most sensible settings. The evaluation additionally revealed that when choice bias relies upon solely on variables like X or A, equity standards can nonetheless be met. Nevertheless, when choice is determined by Y or combos of variables, subgroup equity turns into more difficult to keep up.
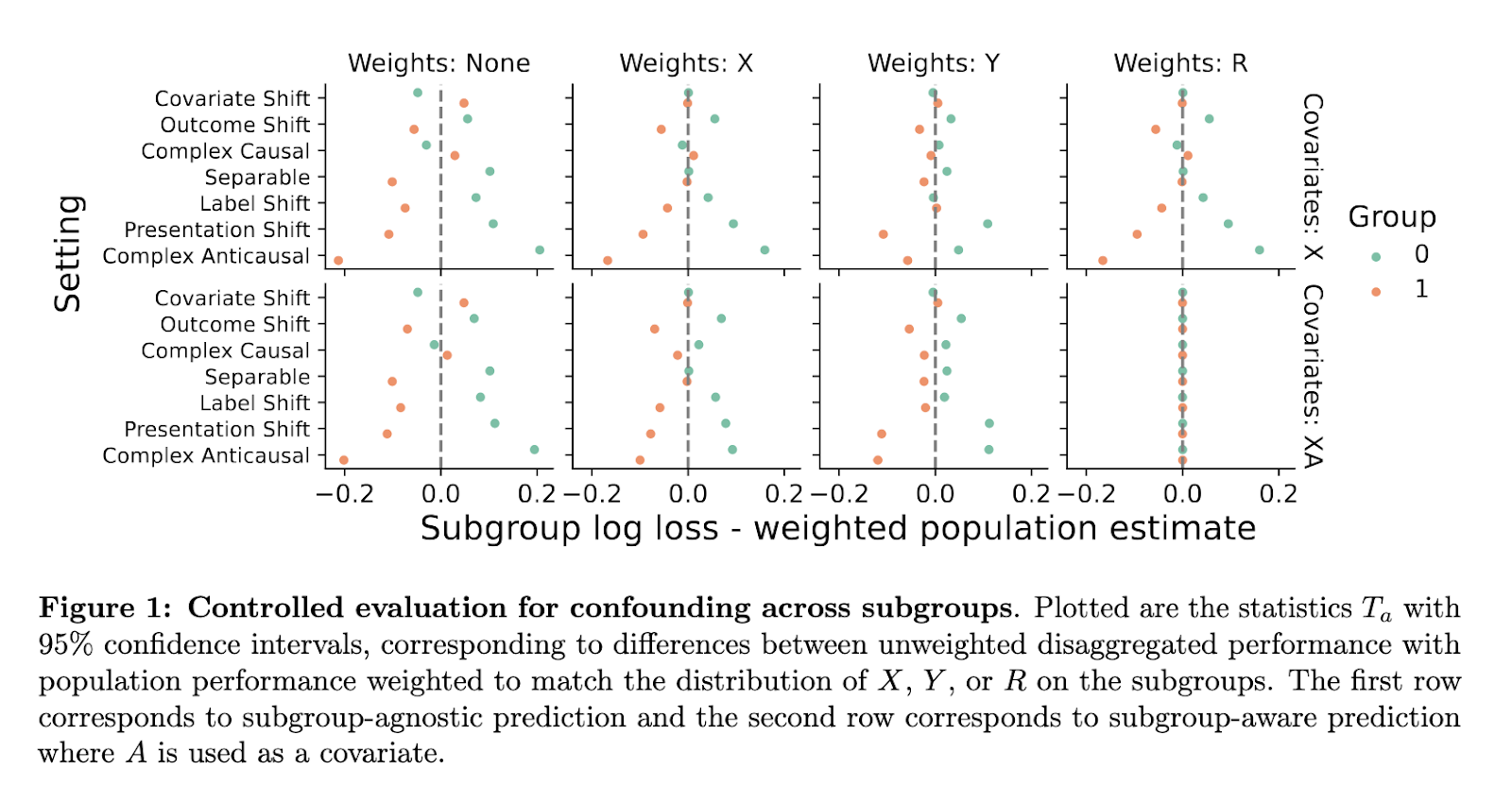
Conclusion and Sensible Implications
This research clarifies that equity can’t be precisely judged by means of subgroup metrics alone. Variations in efficiency might stem from underlying information buildings relatively than biased fashions. The proposed causal framework equips practitioners with instruments to detect and interpret these nuances. By modeling causal relationships explicitly, researchers present a path towards evaluations that replicate each statistical and real-world considerations about equity. The tactic doesn’t assure excellent fairness, nevertheless it offers a extra clear basis for understanding how algorithmic selections impression completely different populations.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


{kind=link}