
Over the previous few years, Immediate engineering has been the key handshake of the AI world. The best phrasing might make a mannequin sound poetic, humorous, or insightful; the improper one turned it flat and robotic. However a brand new Stanford-led paper argues that the majority of this “craft” has been compensating for one thing deeper, a hidden bias in how we educated these methods.
Their declare is easy: the fashions have been by no means boring. They have been educated to behave that means.
And the proposed answer, known as Verbalized Sampling, may not simply change how we immediate fashions; it might rewrite how we take into consideration alignment and creativity in AI.
The Core Downside: Alignment Made AI Predictable
To know the breakthrough, begin with a easy experiment. Ask an AI mannequin, “c” Do it 5 occasions. You’ll virtually all the time get the identical response:

This isn’t laziness; it’s mode collapse, a narrowing of the mannequin’s output distribution after alignment coaching. As a substitute of exploring all of the legitimate responses it might produce, the mannequin gravitates towards the most secure, commonest one.
The Stanford group traced this to typicality bias within the human suggestions knowledge used throughout reinforcement studying. When annotators choose mannequin responses, they persistently favor textual content that sounds acquainted. Over time, reward fashions educated on that desire study to reward normality as an alternative of novelty.
Mathematically, this bias provides a “typicality weight” (α) to the reward perform, amplifying no matter seems to be most statistically common. It’s a gradual squeeze on creativity, the explanation most aligned fashions sound alike.
The Twist: The Creativity Was By no means Misplaced
Right here’s the kicker: the variety isn’t gone. It’s buried.
If you ask for a single response, you’re forcing the mannequin to choose essentially the most possible completion. However for those who ask it to verbalize a number of solutions together with their chances, it immediately opens up its inner distribution, the vary of concepts it really “is aware of.”
That’s Verbalized Sampling (VS) in motion.
As a substitute of:
Inform me a joke about espresso
You ask:
Generate 5 jokes about espresso with their chances
This small change unlocks the variety that alignment coaching had compressed. You’re not retraining the mannequin, altering temperature, or hacking sampling parameters. You’re simply prompting in a different way—asking the mannequin to indicate its uncertainty reasonably than cover it.
The Espresso Immediate: Proof in Motion
To exhibit, the researchers ran the identical espresso joke immediate utilizing each conventional prompting and Verbalized Sampling.
Direct Prompting
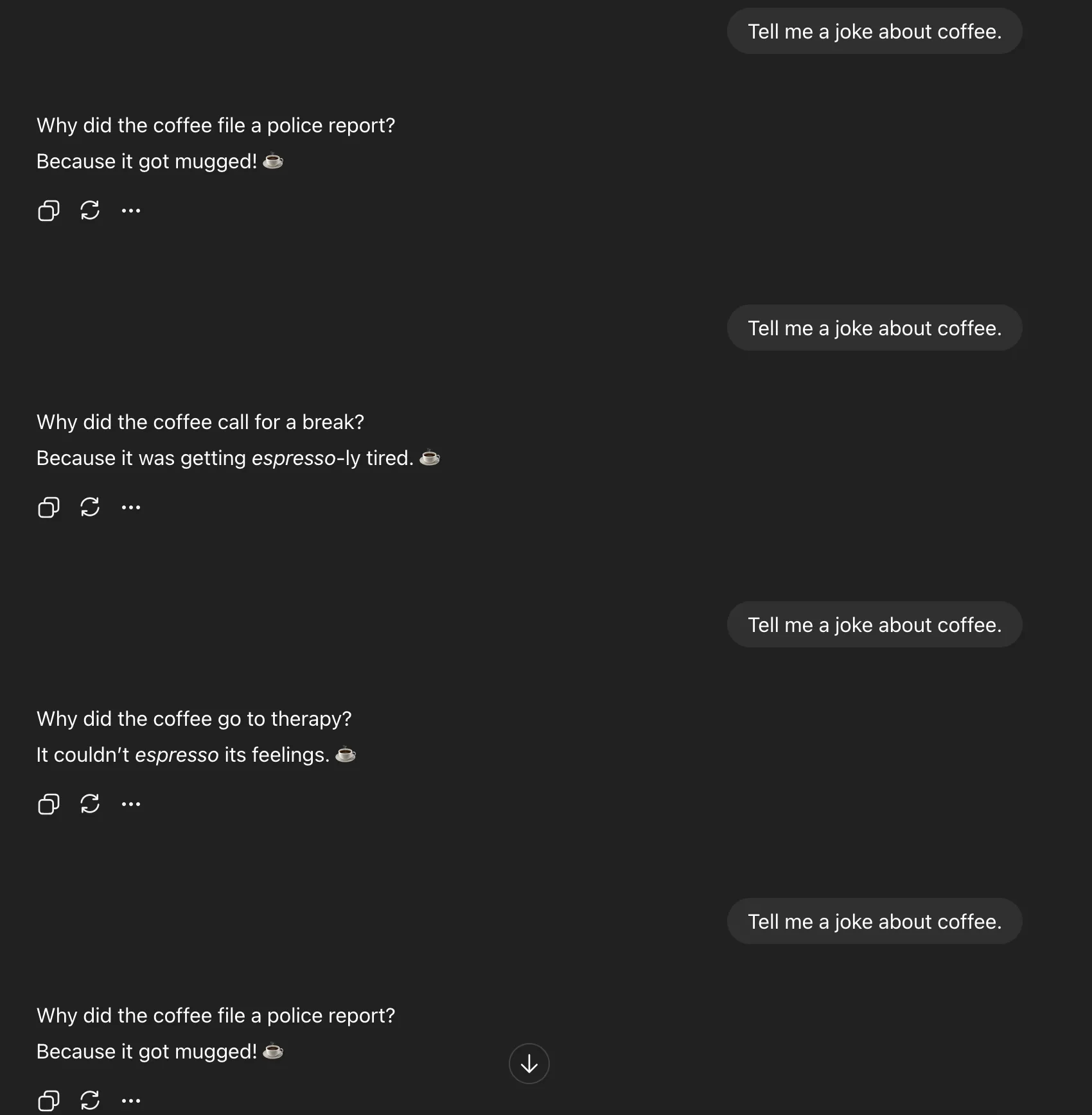
Verbalized Sampling
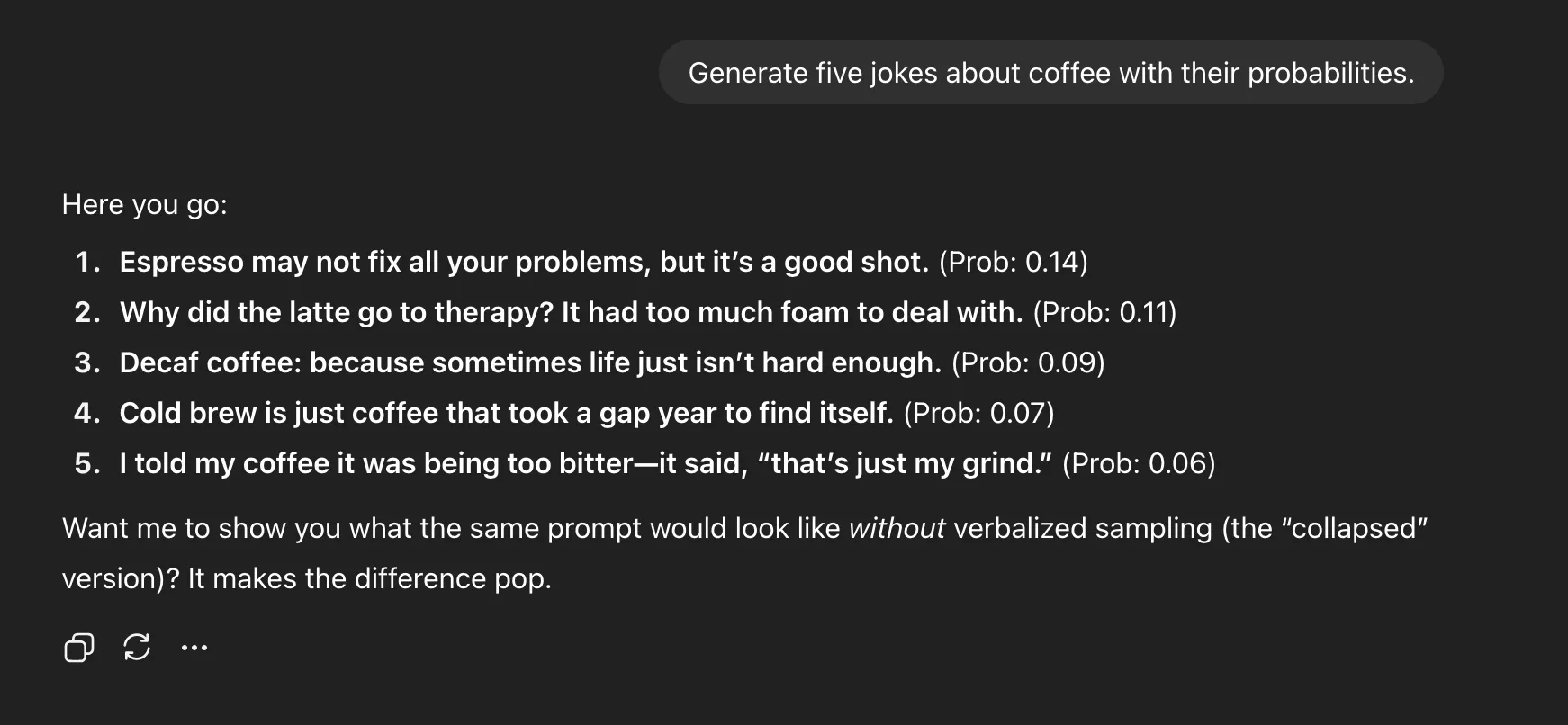
Why It Works
Throughout technology, a language mannequin internally samples tokens from a likelihood distribution, however we normally solely see the best choice. If you ask it to output a number of candidates with chances hooked up, you’re making it cause about its personal uncertainty explicitly.
This “self-verbalization” exposes the mannequin’s underlying variety. As a substitute of collapsing to a single high-probability mode, it reveals you many believable ones.
In observe, meaning “Inform me a joke” yields one mugging pun, whereas “Generate 5 jokes with chances” produces espresso puns, remedy jokes, chilly brew traces, and extra. It’s not simply selection, it’s interpretability. You may see what the mannequin thinks would possibly work.
The Information and the Positive factors
Throughout a number of benchmarks, inventive writing, dialogue simulation, and open-ended QA, the outcomes have been constant:
- 1.6–2.1× enhance in variety for inventive writing duties
- 66.8% restoration of pre-alignment variety
- No drop in factual accuracy or security (refusal charges above 97%)
Bigger fashions benefited much more. GPT-4-class methods confirmed double the variety enchancment in comparison with smaller ones, suggesting that massive fashions have deep latent creativity ready to be accessed.
The Bias Behind It All
To substantiate that typicality bias actually drives mode collapse, the researchers analyzed practically seven thousand response pairs from the HelpSteer dataset. Human annotators most well-liked “typical” solutions about 17–19% extra usually, even when each have been equally appropriate.
They modeled this as:
r(x, y) = r_true(x, y) + α log π_ref(y | x)
That α time period is the typicality bias weight. As α will increase, the mannequin’s distribution sharpens, pushing it towards the middle. Over time, this makes responses protected, predictable, and repetitive.
What does it imply for Immediate Engineering?
So, is immediate engineering useless? Not fairly. However it’s evolving.
Verbalized Sampling doesn’t take away the necessity for considerate prompting—it adjustments what skillful prompting seems to be like. The brand new sport isn’t about tricking a mannequin into creativity; it’s about designing meta-prompts that expose its full likelihood house.
You may even deal with it as a “creativity dial.” Set a likelihood threshold to manage how wild or protected you need the responses to be. Decrease it for extra shock, elevate it for stability.
The Actual Implications
The most important shift right here isn’t about jokes or tales. It’s about reframing alignment itself.
For years, we’ve accepted that alignment makes fashions safer however blander. This analysis suggests in any other case: alignment made them too well mannered, not damaged. By prompting in a different way, we will get well creativity with out touching the mannequin weights.
That has penalties far past inventive writing—from extra life like social simulations to richer artificial knowledge for mannequin coaching. It hints at a brand new form of AI system: one that may introspect by itself uncertainty and supply a number of believable solutions as an alternative of pretending there’s just one.
The Caveats
Not everybody’s shopping for the hype. Critics level out that some fashions might hallucinate likelihood scores as an alternative of reflecting true likelihoods. Others argue this doesn’t repair the underlying human bias, it merely sidesteps it.
And whereas the outcomes look sturdy in managed checks, real-world deployment entails value, latency, and interpretability trade-offs. As one researcher dryly put it on X: “If it labored completely, OpenAI would already be doing it.”
Nonetheless, it’s onerous to not admire the magnificence. No retraining, no new knowledge, only one revised instruction:
Generate 5 responses with their chances.
Conclusion
The lesson from Stanford’s work is greater than any single method. The fashions we’ve constructed have been by no means unimaginative; they have been over-aligned, educated to suppress the variety that made them highly effective.
Verbalized Sampling doesn’t rewrite them; it simply fingers them the keys again.
If pretraining constructed an enormous inner library, alignment locked most of its doorways. VS is how we begin asking to see all 5 variations of the reality.
Immediate engineering isn’t useless. It’s lastly changing into a science.
Regularly Requested Questions
A. Verbalized Sampling is a prompting technique that asks AI fashions to generate a number of responses with their chances, revealing their inner variety with out retraining or parameter tweaks.
A. Due to typicality bias in human suggestions knowledge, fashions study to favor protected, acquainted responses, resulting in mode collapse and lack of inventive selection.
A. No. It redefines it. The brand new ability lies in crafting meta-prompts that expose distributions and management creativity, reasonably than fine-tuning single-shot phrasing.
I concentrate on reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, knowledge evaluation, and knowledge retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and revel in expert-curated content material.

{kind=link}