
If you’re updated with the latest developments of AI and LLMs, you most likely have realized {that a} main a part of the progress remains to be by way of constructing bigger fashions or higher computation routing. Effectively, what if there’s another alternate route? Alongside got here Engram! A revolutionary methodology of DeepSeek AI that’s altering our perspective on the scaling of language fashions.
What Downside Does Engram Remedy?
Take into account a state of affairs: You kind “Alexander the Nice” right into a language mannequin. Now, it spends beneficial computational sources reconstructing this widespread phrase from scratch, each single time. It’s like having an excellent mathematician who has to recount all the ten digits, earlier than fixing any advanced equation.
Present transformer fashions don’t have a devoted technique to merely “search for” widespread patterns. They simulate reminiscence retrieval by way of computation, which is inefficient. Engram introduces what researchers name conditional reminiscence, a complement to the conditional computation we see in Combination-of-Consultants (MoE) fashions.
The outcomes converse for themselves. In benchmark checks, Engram-27B confirmed exceptional enhancements over comparable MoE fashions:
- 5.0-point acquire on BBH reasoning duties
- 3.4-point enchancment on MMLU information checks
- 3.0-point enhance on HumanEval code era
- 97.0 vs 84.2 accuracy on multi-query needle-in-haystack checks
Key Options of Engram:
The important thing options of Engram are:
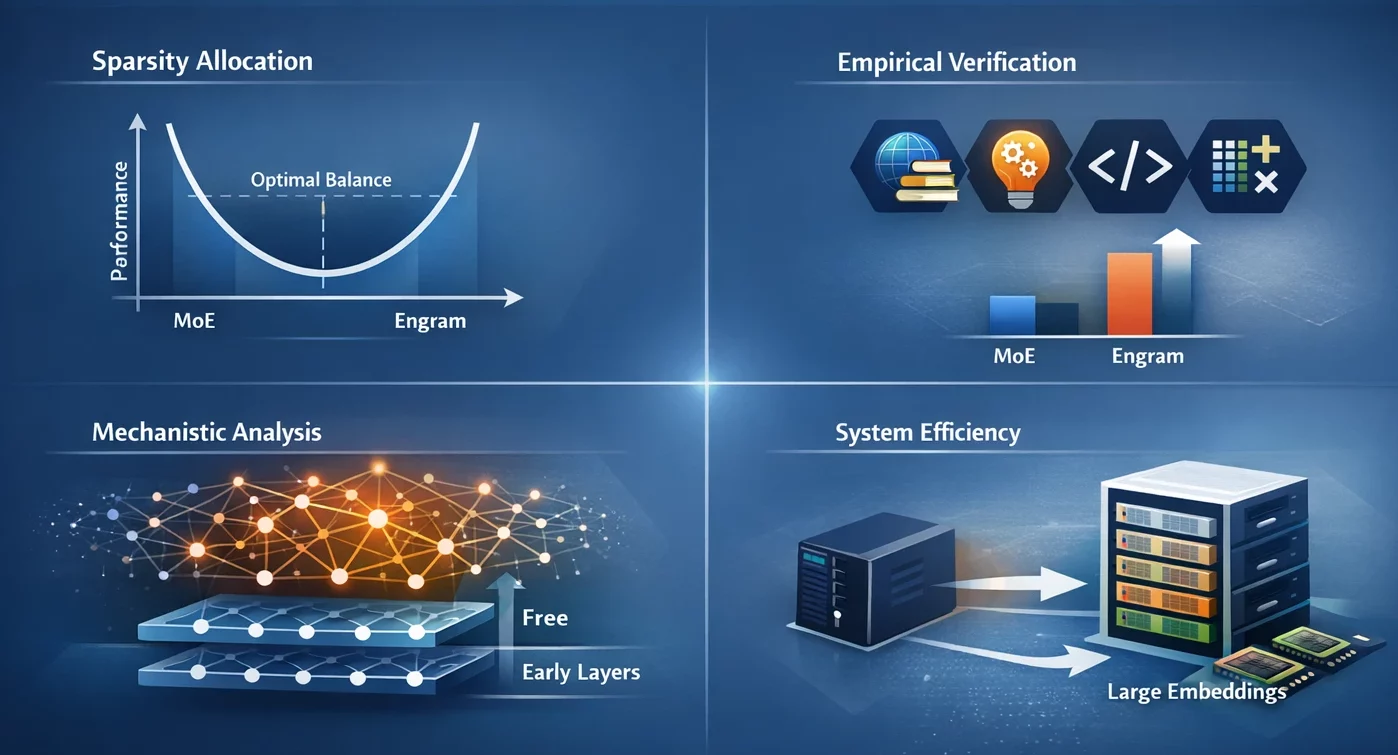
- Sparsity Allocation: We recognized a U-shaped scaling regulation that directs optimum capability allocation, presenting the trade-off of neural computation (MoE) versus static reminiscence (Engram) as a dilemma.
- Empirical Verification: The Engram-27B mannequin supplies a constant acquire over MoE baselines within the domains of data, reasoning, code and math below situations of strict iso-parameter and iso-FLOPs constraints.
- Mechanistic Evaluation: The outcomes of our evaluation point out that Engram permits the early layers to be free from static sample reconstruction, which could lead to sustaining the efficient depth for advanced reasoning.
- System Effectivity: The module makes use of deterministic addressing which permits embedding tables of giant dimension to be moved to host reminiscence with solely a slight improve within the inference time.
How Engram Really Works?
Engram has been in comparison with a high-speed lookup desk within the case of language fashions that may simply entry frequent patterns.
The Core Structure
Engram’s method is predicated on a quite simple but in addition very highly effective concept: it’s based mostly on N-gram embeddings (sequences of N consecutive tokens) that may be seemed up in fixed time O(1). Reasonably than preserving each doable phrase mixture saved, it employs hash features to map patterns to embeddings in an environment friendly method.
There are three fundamental components to this structure:
- Tokenizer Compression: Previous to trying up patterns, Engram standardizes tokens, so “Apple” and “apple” seek advice from the identical idea. This ends in a 23% discount of efficient vocabulary dimension, resulting in the system being extra environment friendly.
- Multi-Head Hashing: To forestall collisions (i.e., totally different patterns mapping to the identical location), Engram employs a number of hash features. For instance, consider it as having a number of totally different telephone books – if one offers you the flawed quantity, the others could have your again.
- Context-Conscious Gating: That is the clever half. Not each reminiscence that’s retrieved is pertinent, so Engram employs attention-like mechanisms to find out how a lot to belief every lookup in accordance with the current context. If a sample is misplaced, the gate worth will drop in direction of zero, and the sample will likely be successfully disregarded.
The Scaling Regulation Discovery
Among the many quite a few fascinating discoveries, the U-shaped scaling regulation stands out. Researchers had been in a position to establish the optimum efficiency when about 75-80% of the capability was allotted to MoE and solely 20-25% to Engram reminiscence.
Full MoE (100%) signifies no devoted reminiscence for the mannequin, and subsequently, no correct use of computation reconstructing the widespread patterns. No MoE (0%) means the mannequin couldn’t do subtle reasoning because of having little or no computational capability. The right level is the place each are balanced.
Getting Began with Engram
- Set up Python with model 3.8 and better.
- Set up
numpyutilizing the next command:
pip set up numpy Fingers-On: Understanding N-gram Hashing
Let’s observe how Engram’s core hashing mechanism works with a sensible job.
Implementing Fundamental N-gram Hash Lookup
On this job, we’ll see how Engram makes use of deterministic hashing to maps token sequences to embeddings, utterly avoiding the requirement to retailer each doable N-gram individually.
1: Establishing the setting
import numpy as np
from typing import Record
# Configuration
MAX_NGRAM = 3
VOCAB_SIZE = 1000
NUM_HEADS = 4
EMBEDDING_DIM = 128 2: Create a easy tokenizer compression simulator
def compress_token(token_id: int) -> int:
# Simulate normalization by mapping related tokens
# In actual Engram, this makes use of NFKC normalization
return token_id % (VOCAB_SIZE // 2)
def compress_sequence(token_ids: Record[int]) -> np.ndarray:
return np.array([compress_token(tid) for tid in token_ids])3: Implement the hash operate
def hash_ngram(tokens: Record[int],
ngram_size: int,
head_idx: int,
table_size: int) -> int:
# Multiplicative-XOR hash as utilized in Engram
multipliers = [2 * i + 1 for i in range(ngram_size)]
combine = 0
for i, token in enumerate(tokens[-ngram_size:]):
combine ^= token * multipliers[i]
# Add head-specific variation
combine ^= head_idx * 10007
return combine % table_size
# Take a look at it
sample_tokens = [42, 108, 256, 512]
compressed = compress_sequence(sample_tokens)
hash_value = hash_ngram(
compressed.tolist(),
ngram_size=2,
head_idx=0,
table_size=5003
)
print(f"Hash worth for 2-gram: {hash_value}")4: Construct a multi-head embedding lookup
def multi_head_lookup(token_sequence: Record[int],
embedding_tables: Record[np.ndarray]) -> np.ndarray:
compressed = compress_sequence(token_sequence)
embeddings = []
for ngram_size in vary(2, MAX_NGRAM + 1):
for head_idx in vary(NUM_HEADS):
desk = embedding_tables[ngram_size - 2][head_idx]
table_size = desk.form[0]
hash_idx = hash_ngram(
compressed.tolist(),
ngram_size,
head_idx,
table_size
)
embeddings.append(desk[hash_idx])
return np.concatenate(embeddings)
# Initialize random embedding tables
tables = [
[
np.random.randn(5003, EMBEDDING_DIM // NUM_HEADS)
for _ in range(NUM_HEADS)
]
for _ in vary(MAX_NGRAM - 1)
]
consequence = multi_head_lookup([42, 108, 256], tables)
print(f"Retrieved embedding form: {consequence.form}")Output:

Understanding Your Outcomes:
Hash worth 292: Your 2-gram sample is situated at this index within the embedding desk. The worth modifications alongside along with your enter tokens, thus exhibiting the deterministic mapping.
Form (256,): A complete of 8 embeddings had been retrieved (2 N-gram sizes × 4 heads every), the place every embedding has a dimension of 32 (EMBEDDING_DIM=128 / NUM_HEADS=4). Concatenated: 8 × 32 = 256 dimensions.
Word: You can even see the implementation of Engram through core logic of Engram module.
Actual-World Efficiency Positive factors
The truth that Engram may also help with information duties is a good plus, nevertheless it truly makes reasoning and code era considerably higher simply the identical.
Engram shifts native sample recognition to reminiscence lookups and, subsequently, the eye mechanisms are enabled to work on international context as nicely. The advance in efficiency on this case may be very important. Through the RULER benchmark take a look at with 32k context home windows, Engram was in a position to attain:
- Multi-query NIAH: 97.0 (vs 84.2 baseline)
- Variable Monitoring: 89.0 (vs 77.0 baseline)
- Frequent Phrases Extraction: 99.6 (vs 73.0 baseline)
Conclusion
Engram reveals very fascinating analysis paths. Is it doable to exchange the mounted features with realized hashing? What if the reminiscence is dynamic and will get up to date in real-time throughout inference? What would be the response by way of processing bigger contexts?
DeepSeek-AI’s Engram repository has the whole technical particulars and code, and the strategy is already being adopted in real-life techniques. The primary takeaway is that AI improvement isn’t solely a matter of larger fashions or higher routing. Typically, it’s a quest for the suitable instruments for the fashions and generally, that sure software is solely a really environment friendly reminiscence system.
Steadily Requested Questions
A. Engram is a reminiscence module for language fashions that lets them instantly search for widespread token patterns as an alternative of recomputing them each time. Consider it as giving an LLM a quick, dependable reminiscence alongside its reasoning capacity.
A. Conventional transformers simulate reminiscence by way of computation. Even for quite common phrases, the mannequin recomputes patterns repeatedly. Engram removes this inefficiency by introducing conditional reminiscence, releasing computation for reasoning as an alternative of recall.
A. MoE focuses on routing computation selectively. Engram enhances this by routing reminiscence selectively. MoE decides which consultants ought to assume; Engram decides which patterns must be remembered and retrieved immediately.
Information Science Trainee at Analytics Vidhya
I’m at present working as a Information Science Trainee at Analytics Vidhya, the place I give attention to constructing data-driven options and making use of AI/ML strategies to unravel real-world enterprise issues. My work permits me to discover superior analytics, machine studying, and AI functions that empower organizations to make smarter, evidence-based choices.
With a robust basis in pc science, software program improvement, and information analytics, I’m captivated with leveraging AI to create impactful, scalable options that bridge the hole between expertise and enterprise.
📩 You can even attain out to me at [email protected]
Login to proceed studying and revel in expert-curated content material.

{kind=link}