
The Hidden Value of AI: The GPU Invoice
AI mannequin coaching sometimes consumes tens of millions of {dollars} in GPU compute—a burden that shapes budgets, limits experimentation, and slows progress. The established order: coaching a contemporary language mannequin or imaginative and prescient transformer on ImageNet-1K can burn by means of hundreds of GPU-hours. It’s not sustainable for startups, labs, and even giant tech corporations.
However what in case you might lower your GPU invoice by 87%—just by altering the optimizer?
That’s the promise of Fisher-Orthogonal Projection (FOP), a contemporary analysis from the College of Oxford staff. This text will stroll you thru why gradients aren’t noise, how FOP thinks like a terrain map, and what this implies for your enterprise, your mannequin, and the way forward for AI.
The Flaw in How We Prepare Fashions
Fashionable deep studying depends on gradient descent: the optimizer nudges mannequin parameters in a path that ought to cut back the loss. However with large-scale coaching, the optimizer works with mini-batches—subsets of the coaching information—and averages their gradients to get a single replace path.
Right here’s the catch: The gradient from every component within the batch is at all times totally different. The usual method dismisses these variations as random noise and smooths them out for stability. However in actuality, this “noise” is an important directional sign in regards to the true form of the loss panorama.
FOP: The Terrain-Conscious Navigator
FOP treats the variance between gradients inside a batch not as noise, however as a terrain map. It takes the common gradient (the primary path) and initiatives out the variations, developing a geometry-aware, curvature-sensitive element that steers the optimizer away from partitions and alongside the canyon flooring—even when the primary path is straight forward.
The way it works:
- Common gradient factors the way in which.
- Distinction gradient acts as a terrain sensor, revealing whether or not the panorama is flat (protected to maneuver quick) or has steep partitions (decelerate, keep within the canyon).
- FOP combines each alerts: It provides a “curvature-aware” step orthogonal to the primary path, guaranteeing it by no means fights itself or oversteps.
- Consequence: Quicker, extra steady convergence, even at excessive batch sizes—the regime the place SGD, AdamW, and even state-of-the-art KFAC fail.
In deep studying phrases: FOP applies a Fisher-orthogonal correction on prime of normal pure gradient descent (NGD). By preserving this intra-batch variance, FOP maintains details about the native curvature of the loss panorama, a sign that was beforehand misplaced in averaging.
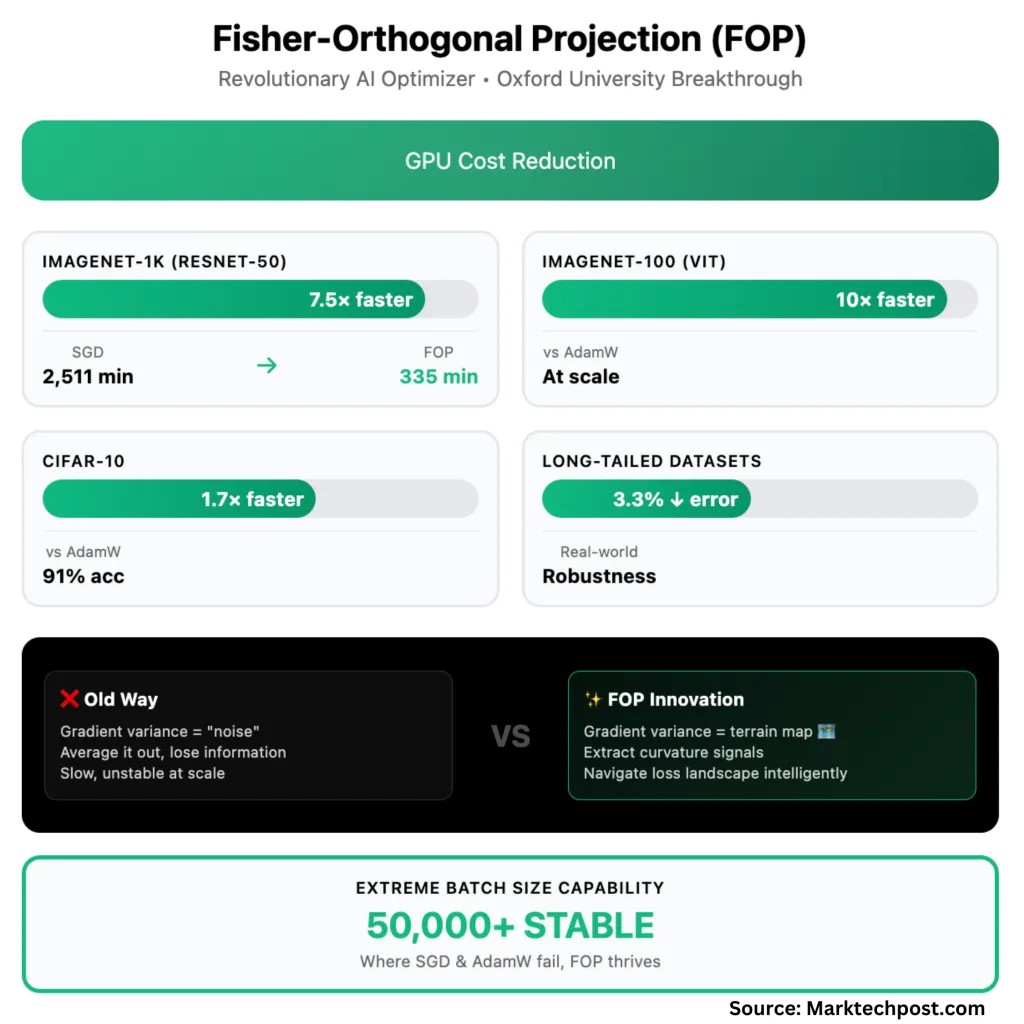
FOP in Follow: 7.5x Quicker on ImageNet-1K
The outcomes are dramatic:
- ImageNet-1K (ResNet-50): To achieve normal validation accuracy (75.9%), SGD takes 71 epochs and a pair of,511 minutes. FOP reaches the identical accuracy in simply 40 epochs and 335 minutes—a 7.5x wall-clock speedup.
- CIFAR-10: FOP is 1.7x sooner than AdamW, 1.3x sooner than KFAC. On the largest batch dimension (50,000), solely FOP reaches 91% accuracy; others fail solely.
- ImageNet-100 (Imaginative and prescient Transformer): FOP is as much as 10x sooner than AdamW, 2x sooner than KFAC, on the largest batch sizes.
- Lengthy-tailed (imbalanced) datasets: FOP reduces High-1 error by 2.3–3.3% over sturdy baselines—a significant achieve for real-world, messy information.
Reminiscence use: FOP’s peak GPU reminiscence footprint is increased for small-scale jobs, however when distributed throughout many gadgets, it matches KFAC—and the time financial savings far outweigh the fee.
Scalability: FOP sustains convergence even when batch sizes climb into the tens of hundreds—one thing no different optimizer examined might do. With extra GPUs, coaching time drops virtually linearly—not like current strategies, which frequently degrade in parallel effectivity.
Why This Issues for Enterprise, Follow, and Analysis
- Enterprise: An 87% discount in coaching price transforms the economics of AI growth. This isn’t incremental. Groups can re-invest financial savings into bigger, extra bold fashions, or construct a moat with sooner, cheaper experimentation.
- Practitioners: FOP is plug-and-play: The paper’s open-source code could be dropped into current PyTorch workflows with a single line change and no additional tuning. For those who use KFAC, you’re already midway there.
- Researchers: FOP redefines what “noise” is in gradient descent. Intra-batch variance isn’t solely helpful—it’s important. Robustness on imbalanced information is a bonus for real-world deployment.
How FOP Adjustments the Panorama
Historically, massive batches have been a curse: They made SGD and AdamW unstable, and even KFAC (with its pure gradient curvature) fell aside. FOP turns this on its head. By preserving and leveraging intra-batch gradient variation, it unlocks steady, quick, scalable coaching at unprecedented batch sizes.
FOP isn’t a tweak—it’s a basic rethinking of what alerts are useful in optimization. The “noise” you common out at the moment is your terrain map tomorrow.
Abstract Desk: FOP vs. Standing Quo
| Metric | SGD/AdamW | KFAC | FOP (this work) |
|---|---|---|---|
| Wall-clock speedup | Baseline | 1.5–2x sooner | As much as 7.5x sooner |
| Giant-batch stability | Fails | Stalls, wants damping | Works at excessive scale |
| Robustness (imbalance) | Poor | Modest | Finest at school |
| Plug-and-play | Sure | Sure | Sure (pip installable) |
| GPU reminiscence (distributed) | Low | Reasonable | Reasonable |
Abstract
Fisher-Orthogonal Projection (FOP) is a leap ahead for large-scale AI coaching, delivering as much as 7.5× sooner convergence on datasets like ImageNet-1K at extraordinarily giant batch sizes, whereas additionally bettering generalization—decreasing error charges by 2.3–3.3% on difficult, imbalanced benchmarks. In contrast to standard optimizers, FOP extracts and leverages gradient variance to navigate the true curvature of the loss panorama, making use of data that was beforehand discarded as “noise.” This not solely slashes GPU compute prices—probably by 87%—but in addition allows researchers and corporations to coach larger fashions, iterate sooner, and keep strong efficiency even on real-world, uneven information. With a plug-and-play PyTorch implementation and minimal tuning, FOP gives a sensible, scalable path for the following era of machine studying at scale.
Take a look at the Paper. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}