
DeepSeek V3.1 didn’t arrive with flashy press releases or an enormous marketing campaign. It simply confirmed up on Hugging Face, and inside hours, folks observed. With 685 billion parameters and a context window that may stretch to 128k tokens, it’s not simply an incremental replace. It looks like a serious second for open-source AI. This text will go over DeepSeek V3.1 key options, capabilities, and a hands-on to get you began.
What precisely is DeepSeek V3.1?
DeepSeek V3.1 is the most recent member of the V3 household. In comparison with the sooner 671B model, V3.1 is barely bigger, however extra importantly, it’s extra versatile. The mannequin helps a number of precision codecs—BF16, FP8, F32—so you’ll be able to adapt it to no matter compute you have got readily available.
It isn’t nearly uncooked dimension, although. V3.1 blends conversational potential, reasoning, and code technology into one unified mannequin or a Hybrid mannequin. That’s an enormous deal! Earlier generations typically felt like they had been good at one factor however common at others. Right here, every thing is built-in.
Easy methods to Entry DeepSeek V3.1

There are just a few other ways to entry DeepSeek V3.1:
- Official Net App: Head to deepseek.com and use the browser chat. V3.1 is already the default there, so that you don’t must configure something.
- API Entry: Builders can name the deepseek-chat (basic use) or deepseek-reasoner (reasoning mode) endpoints by way of the official API. The interface is OpenAI-compatible, so for those who’ve used OpenAI’s SDKs, the workflow feels the identical.
- Hugging Face: The uncooked weights for V3.1 are printed below an open license. You may obtain them from the DeepSeek Hugging Face web page and run them domestically in case you have the {hardware}.
If you happen to simply wish to chat with it, the web site is the quickest route. If you wish to fine-tune, benchmark, or combine into your instruments, seize the API or Hugging Face weights. The hands-on of this text is completed on the Net App.
How is it totally different from DeepSeek V3?
DeepSeek V3.1 brings a set of vital upgrades in comparison with earlier releases:
- Hybrid mannequin with considering mode: Provides a toggleable reasoning layer that strengthens problem-solving whereas aiming to keep away from the standard efficiency drop of hybrids.
- Native search token assist: Improves retrieval and search duties, although group exams present the characteristic prompts very often. A correct toggle continues to be anticipated within the official documentation.
- Stronger programming capabilities: Benchmarks place V3.1 on the high of open-weight coding fashions, confirming its edge in software-related duties.
- Unchanged context size: The 128k-token window stays the identical as in V3-Base, so you continue to get novel-length context capability.
Taken collectively, these updates make V3.1 not only a scale-up, however a refinement.
Why persons are paying consideration
Listed below are a number of the standout options of DeepSeek V3.1:
- Context window: 128k tokens. That’s the size of a full-length novel or a whole analysis report in a single shot.
- Precision flexibility: Runs in BF16, FP8, or F32 relying in your {hardware} and efficiency wants.
- Hybrid design: One mannequin that may chat, purpose, and code with out breaking context.
- Benchmark outcomes: Scored 71.6% on the Aider coding benchmark, edging previous Claude Opus 4.
- Effectivity: Performs at a degree the place some rivals would value 60–70 instances extra to run the identical exams.
- Open-Supply: Most likely the one open supply mannequin that’s maintaining with the closed supply releases.
Attempting it out
Now we’d be testing DeepSeek V3.1 capabilities, utilizing the net interface:
1. Lengthy doc summarization
A Room with a View by E.M. Forster was used because the enter for the next immediate. The e book is over 60k phrases in size. You’ll find the contents of the e book at Gutenberg.
Immediate: “Summarize the important thing factors in a structured define.”
Response:
2. Step-by-step reasoning
Immediate: “Step-by-step reasoning
Work by way of this puzzle step-by-step. Present all calculations and intermediate instances right here. Preserve items constant. Don’t skip steps. Double-check outcomes with a fast test on the finish of the suppose block.
A practice leaves Station A at 08:00 towards Station B. The space between A and B is 410 km.
Prepare A:
- Cruising velocity: 80 km/h
- Scheduled cease: 10 minutes at Station C, situated 150 km from A
- Observe work zone: from the 220 km marker to the 240 km marker measured from A, velocity restricted to 40 km/h in that 20 km section
- Exterior the work zone, run on the cruising velocity
.
. (Some elements omitted for brevity; Full model may be seen within the following video)
.
Reply format (outdoors the suppose block solely):
- Meet: [HH:MM], [distance from A in km, one decimal]
- Movement till meet: Prepare A [minutes], Prepare B [minutes]
- Closing arrivals: Prepare A at [HH:MM], Prepare B at [HH:MM], First to reach: [A or B]
Solely embrace the ultimate outcomes and a one-sentence justification outdoors the suppose block. All detailed reasoning stays inside.”
Response:
3. Code technology
Immediate: “Write a Python script that reads a CSV and outputs JSON, with feedback explaining every half.”
Response:
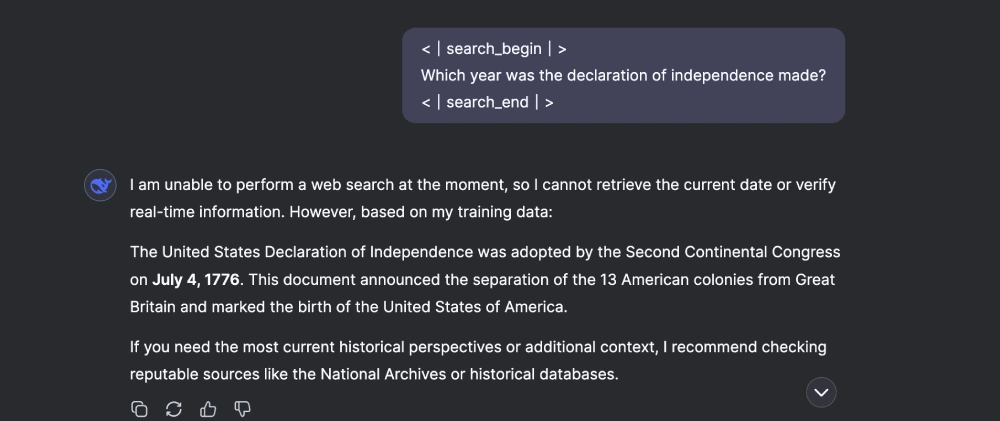
4. Search-style querying
Immediate: “
Which yr was the declaration of independence made?
”
Response:
5. Hybrid search querying
Immediate: “Summarize the principle plot of *And Then There Have been None* briefly.
Now, Present me a hyperlink from the place I should buy that e book. . Lastly,
Response:
Statement
Listed below are a number of the issues that stood out to me whereas testing the mannequin:
- If the enter size exceeds the restrict, the a part of the enter could be used as an enter (like within the first activity).
- If duties are primary, then the mannequin goes overboard with overtly lengthy responses (like within the second activity).
- The tokens used to probe the search and reasoning capabilities aren’t dependable. Typically the mannequin gained’t invoke them, or else proceed with its default immediate processing routine.
- The tokens
andare a part of the mannequin’s vocabulary. - They act as hints or triggers to information how the mannequin ought to course of the immediate. However since they’re tokens within the textual content house, the mannequin typically echoes them again actually in its output.
- Not like an API “swap” that disappears behind the scenes, these tags are extra like management directions baked into the textual content stream. That’s why you’ll generally see them present up within the remaining reply.
Benchmarks: DeepSeek V3.1 vs Rivals
Group exams are already displaying V3.1 close to the highest of open-source leaderboards for programming duties. It doesn’t simply rating nicely—it does so at a fraction of the price of fashions like Claude or GPT-4.
Right here’s the benchmark comparability:
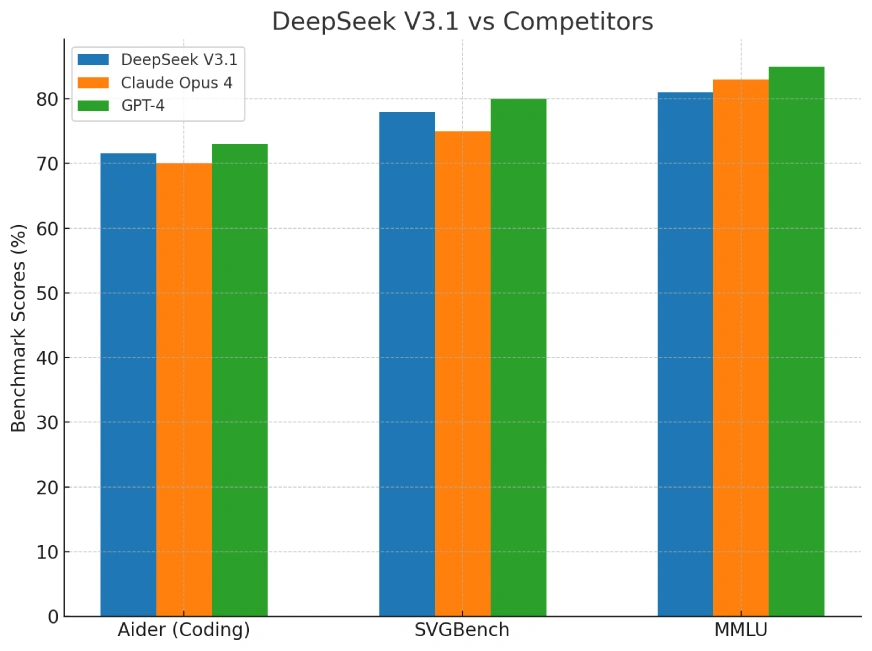
The benchmark chart in contrast DeepSeek V3.1, Claude Opus 4, and GPT-4 on three key metrics:
- Aider (coding benchmark)
- SVGBench (programming duties)
- MMLU (broad data and reasoning)
These cowl sensible coding potential, structured reasoning, and basic tutorial data.
Wrapping up
DeepSeek V3.1 is the form of launch that shifts conversations. It’s open, it’s huge, and it doesn’t lock folks behind a paywall. You may obtain it, run it, and experiment with it right this moment.
For builders, it’s an opportunity to push the bounds of long-context summarization, reasoning chains, and code technology with out relying solely on closed APIs. For the broader AI ecosystem, it’s proof that high-end functionality is not restricted to only a handful of proprietary labs. We’re not restricted to choosing the proper instrument for our use case. The mannequin now does it for you, or might be advised utilizing outlined syntax. This considerably will increase the scope for various capabilities of a mannequin being put into use for fixing a fancy question.
This launch isn’t simply one other model bump. It’s a sign of the place open fashions are headed: larger, smarter, and surprisingly reasonably priced.
Ceaselessly Requested Questions
A. DeepSeek V3.1 introduces a hybrid reasoning mode, native search token assist, and improved coding benchmarks. Whereas its parameter depend is barely increased than V3, the actual distinction lies in its flexibility and refined efficiency. It blends chat, reasoning, and coding seamlessly whereas preserving the 128k context window.
A. You may strive DeepSeek V3.1 within the browser by way of the official DeepSeek web site, by way of the API (deepseek-chat or deepseek-reasoner), or by downloading the open weights from Hugging Face. The online app is best for informal testing, whereas the API and Hugging Face enable superior use circumstances.
A. DeepSeek V3.1 helps an enormous 128,000-token context window, equal to tons of of pages of textual content. This makes it appropriate for complete book-length paperwork or massive datasets. The size is unchanged from V3, nevertheless it stays one of the crucial sensible benefits for summarization and reasoning duties.
A. These tokens act as triggers that information the mannequin’s conduct. and activate search-like retrieval. They typically seem in outputs as a result of they’re a part of the mannequin’s vocabulary, however you’ll be able to instruct the mannequin to not show them.
A. Group exams present V3.1 among the many high performers in open-source coding benchmarks, surpassing Claude Opus 4 and approaching GPT-4’s degree of reasoning. Its key benefit is effectivity—delivering comparable or higher outcomes at a fraction of the price, making it extremely engaging for builders and researchers.
I concentrate on reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, information evaluation, and knowledge retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and revel in expert-curated content material.

{kind=link}