
Introduction
Tencent’s Hunyuan group has launched Hunyuan-MT-7B (a translation mannequin) and Hunyuan-MT-Chimera-7B (an ensemble mannequin). Each fashions are designed particularly for multilingual machine translation and had been launched along with Tencent’s participation within the WMT2025 Common Machine Translation shared activity, the place Hunyuan-MT-7B ranked first in 30 out of 31 language pairs.
Mannequin Overview
Hunyuan-MT-7B
- A 7B parameter translation mannequin.
- Helps mutual translation throughout 33 languages, together with Chinese language ethnic minority languages comparable to Tibetan, Mongolian, Uyghur, and Kazakh.
- Optimized for each high-resource and low-resource translation duties, attaining state-of-the-art outcomes amongst fashions of comparable measurement.
Hunyuan-MT-Chimera-7B
- An built-in weak-to-strong fusion mannequin.
- Combines a number of translation outputs at inference time and produces a refined translation utilizing reinforcement studying and aggregation methods.
- Represents the first open-source translation mannequin of this kind, enhancing translation high quality past single-system outputs.
Coaching Framework
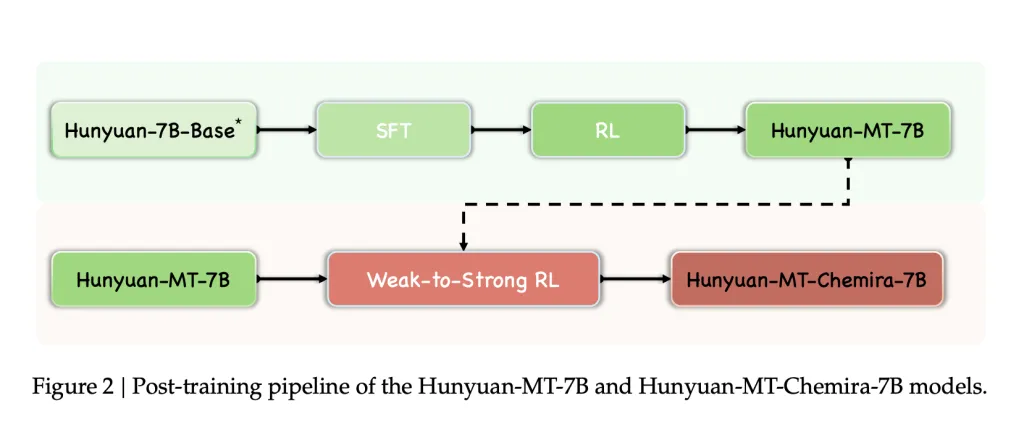
The fashions had been educated utilizing a five-stage framework designed for translation duties:
- Common Pre-training
- 1.3 trillion tokens masking 112 languages and dialects.
- Multilingual corpora assessed for data worth, authenticity, and writing fashion.
- Range maintained via disciplinary, trade, and thematic tagging methods.
- MT-Oriented Pre-training
- Monolingual corpora from mC4 and OSCAR, filtered utilizing fastText (language ID), minLSH (deduplication), and KenLM (perplexity filtering).
- Parallel corpora from OPUS and ParaCrawl, filtered with CometKiwi.
- Replay of normal pre-training knowledge (20%) to keep away from catastrophic forgetting.
- Supervised Nice-Tuning (SFT)
- Stage I: ~3M parallel pairs (Flores-200, WMT check units, curated Mandarin–minority knowledge, artificial pairs, instruction-tuning knowledge).
- Stage II: ~268k high-quality pairs chosen via automated scoring (CometKiwi, GEMBA) and guide verification.
- Reinforcement Studying (RL)
- Algorithm: GRPO.
- Reward capabilities:
- XCOMET-XXL and DeepSeek-V3-0324 scoring for high quality.
- Terminology-aware rewards (TAT-R1).
- Repetition penalties to keep away from degenerate outputs.
- Weak-to-Sturdy RL
- A number of candidate outputs generated and aggregated via reward-based output
- Utilized in Hunyuan-MT-Chimera-7B, enhancing translation robustness and decreasing repetitive errors.
Benchmark Outcomes
Computerized Analysis
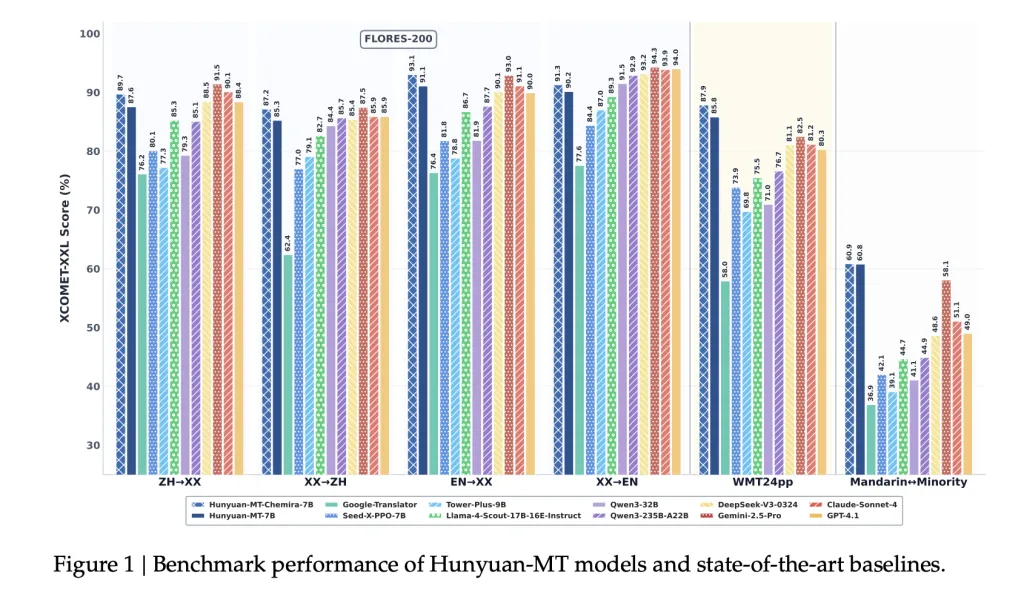
- WMT24pp (English⇔XX): Hunyuan-MT-7B achieved 0.8585 (XCOMET-XXL), surpassing bigger fashions like Gemini-2.5-Professional (0.8250) and Claude-Sonnet-4 (0.8120).
- FLORES-200 (33 languages, 1056 pairs): Hunyuan-MT-7B scored 0.8758 (XCOMET-XXL), outperforming open-source baselines together with Qwen3-32B (0.7933).
- Mandarin⇔Minority Languages: Scored 0.6082 (XCOMET-XXL), increased than Gemini-2.5-Professional (0.5811), displaying vital enhancements in low-resource settings.
Comparative Outcomes
- Outperforms Google Translator by 15–65% throughout analysis classes.
- Outperforms specialised translation fashions comparable to Tower-Plus-9B and Seed-X-PPO-7B regardless of having fewer parameters.
- Chimera-7B provides ~2.3% enchancment on FLORES-200, notably in Chinese language⇔Different and non-English⇔non-Chinese language translations.
Human Analysis
A customized analysis set (masking social, medical, authorized, and web domains) in contrast Hunyuan-MT-7B with state-of-the-art fashions:
- Hunyuan-MT-7B: Avg. 3.189
- Gemini-2.5-Professional: Avg. 3.223
- DeepSeek-V3: Avg. 3.219
- Google Translate: Avg. 2.344
This reveals that Hunyuan-MT-7B, regardless of being smaller at 7B parameters, approaches the standard of a lot bigger proprietary fashions.
Case Research
The report highlights a number of real-world circumstances:
- Cultural References: Accurately interprets “小红薯” because the platform “REDnote,” in contrast to Google Translate’s “candy potatoes.”
- Idioms: Interprets “You’re killing me” as “你真要把我笑死了” (expressing amusement), avoiding literal misinterpretation.
- Medical Phrases: Interprets “uric acid kidney stones” exactly, whereas baselines generate malformed outputs.
- Minority Languages: For Kazakh and Tibetan, Hunyuan-MT-7B produces coherent translations, the place baselines fail or output nonsensical textual content.
- Chimera Enhancements: Provides enhancements in gaming jargon, intensifiers, and sports activities terminology.
Conclusion
Tencent’s launch of Hunyuan-MT-7B and Hunyuan-MT-Chimera-7B establishes a brand new customary for open-source translation. By combining a fastidiously designed coaching framework with specialised give attention to low-resource and minority language translation, the fashions obtain high quality on par with or exceeding bigger closed-source methods. The launch of those 2 fashions offers the AI analysis group with accessible, high-performance instruments for multilingual translation analysis and deployment.
Take a look at the Paper, GitHub Web page, and Mannequin on Hugging Face. All credit score for this analysis goes to the researchers of this undertaking. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}