
Introduction
Empowering giant language fashions (LLMs) to fluidly work together with dynamic, real-world environments is a brand new frontier for AI engineering. The Mannequin Context Protocol (MCP) specification presents a standardized gateway by way of which LLMs can interface with arbitrary exterior techniques—APIs, file techniques, databases, functions, or instruments—without having customized glue code or brittle immediate hacks every time. Nonetheless, leveraging such toolsets programmatically, with sturdy reasoning throughout multi-step duties, stays a formidable problem.
That is the place the current mixture of MCP- RL (a reinforcement studying loop focusing on MCP servers) and the open-source ART (Agent Reinforcement Coach) library brings a paradigm shift: now you can have an agent probe, specialize, and self-optimize for any MCP service with minimal human design, no labeled knowledge, and SOTA reliability. This text unpacks the precise mechanics, implementation pathways, and technical intricacies—all the way down to code degree—of this method.
What Is MCP- RL?
MCP- RL is a meta-training protocol constructed to let any LLM agent study, by way of reinforcement studying (RL), to function the toolset uncovered by an MCP server. MCP-RL is a part of the Agent Reinforcement Coach (ART) venture. Given solely the server’s URL:
- The agent introspects the server, robotically discovering the accessible instruments (capabilities, APIs, endpoints) with their schemas.
- Artificial duties are designed on-the-fly to embody numerous instrument functions.
- A relative scoring system (RULER) benchmarks agent efficiency, even with out labeled gold knowledge, on every trajectory.
- The agent is iteratively fine-tuned to maximise process success.
This implies an LLM can acquire proficiency on any conformant toolbacked server—APIs for climate, databases, file search, ticketing, and many others.—simply by pointing MCP- RL on the proper endpoint.
ART: The Agent Reinforcement Coach
ART (Agent Reinforcement Coach) gives the orchestrated RL pipeline underlying MCP- RL, supporting most vLLM/HuggingFace-compatible fashions (e.g. Qwen2.5, Qwen3, Llama, Kimi) and a distributed or native compute setting. ART is architected with:
- Consumer/server separation: Inference and RL coaching decoupled; brokers may be run from any consumer whereas coaching is robotically offloaded.
- Plug-and-play integration: Minimal intrusion to present codebases; simply hook ART’s consumer into your agent’s message-passing loop.
- GRPO algorithm: An improved RL fine-tuning strategy for stability and studying effectivity, leveraging LoRA and vLLM for scalable deployment.
- No labeled knowledge required: Artificial eventualities and relative reward (RULER) system fully exchange hand-crafted datasets.
Code Walkthrough: Specializing LLMs with MCP- RL
The essence of the workflow is distilled within the following code excerpt from ART’s documentation:
from artwork.rewards import ruler_score_group
# Level to an MCP server (instance: Nationwide Climate Service)
MCP_SERVER_URL = "https://server.smithery.ai/@smithery-ai/national-weather-service/mcp"
# Generate a batch of artificial eventualities masking server instruments
eventualities = await generate_scenarios(
num_scenarios=24,
server_url=MCP_SERVER_URL
)
# Run agent rollouts in parallel, accumulating response trajectories
# Every trajectory = (system, consumer, assistant messages...)
# Assign rewards to every group utilizing RULER's relative scoring
scored_groups = []
for group in teams:
judged_group = await ruler_score_group(group)
scored_groups.append(judged_group)
# Submit grouped trajectories for RL fine-tuning (GRPO)
await mannequin.practice(scored_groups)
Rationalization:
- State of affairs Synthesis: No human-crafted duties wanted.
generate_scenariosauto-designs numerous prompts/duties based mostly on the instruments found from the MCP server. - Rollout Execution: The agent runs, invoking instrument calls through MCP, buying trajectories of step-wise instrument utilization and outputs.
- RULER Scoring: As a substitute of a static reward, RULER makes use of relative analysis inside every batch to robotically scale rewards, robustly dealing with variable problem and process novelty.
- Coaching Loop: Batches of trajectories and rewards are despatched to the ART server, the place LoRA adapters are incrementally re-trained utilizing the coverage gradient algorithm GRPO.
The loop repeats—every cycle making the agent more adept at combining the server’s instruments to unravel the artificial duties.
Below the Hood: How MCP- RL Generalizes
- Software Discovery: The MCP interface usually exposes OpenAPI-compliant schemas, which the agent parses to enumerate all callable actions and their signatures—no assumptions about area specifics.
- State of affairs Era: Templates or few-shot language mannequin prompts can be utilized to bootstrap duties that pattern consultant usages (atomic or complicated API compositions).
- Suggestions with out Gold Knowledge: RULER’s innovation is batchwise comparability, giving increased scores to extra profitable behaviors inside the present set—this self-adapts throughout new duties or noisy environments.
- Artificial → Actual Job Bridge: As soon as the agent is proficient on constructed duties, it generalizes to precise consumer calls for, for the reason that protection of instrument utilization is designed to be broad and combinatorial.
Actual-World Affect and Benchmarks
- Minimal Setup: Deployable with any MCP server—simply the endpoint, no inner code or entry required.
- Common Goal: Brokers may be educated to make use of arbitrary toolsets—climate, code evaluation, file search, and many others.
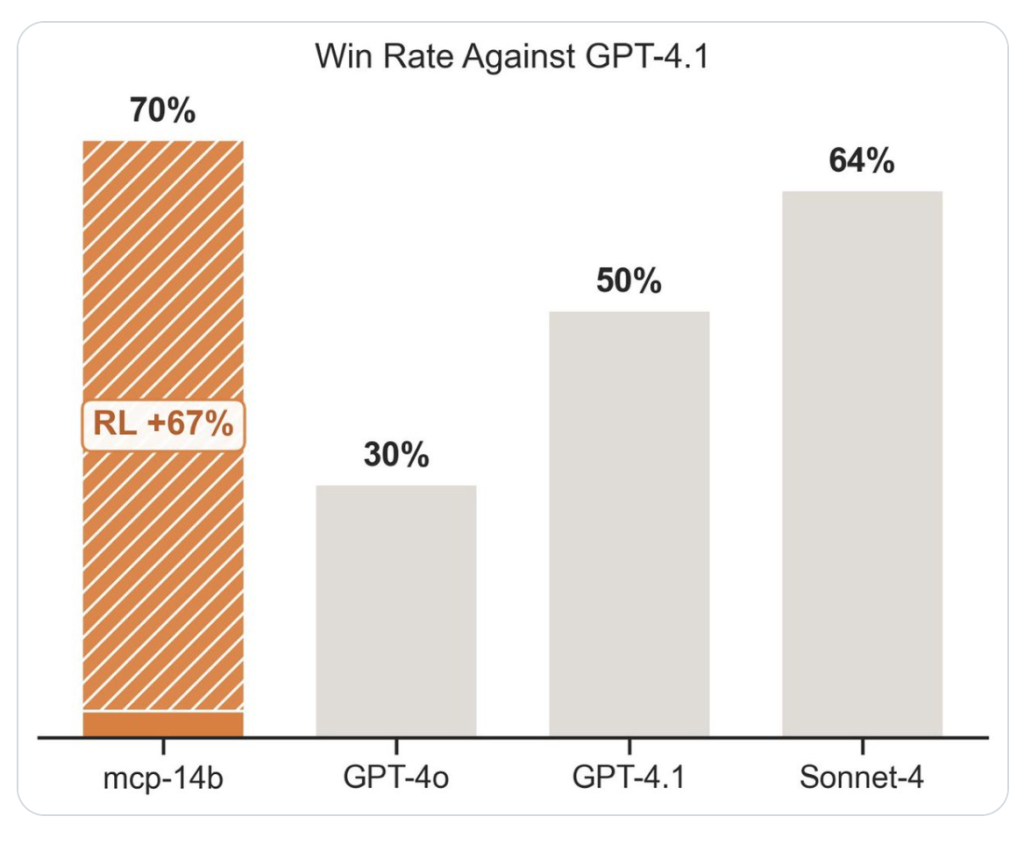
- State-of-the-Artwork Outcomes: Matched or outperformed specialist agent baselines in 2/3 public benchmarks.
- Zero Labeled Knowledge: The strategy gives a scalable path for agentic RL on-the-fly, relevant even the place professional demonstrations are unimaginable to acquire.
Architectural Overview
| Element | Description |
|---|---|
| ART Consumer | Orchestrates agent rollouts, sends/receives messages, batches rewards |
| ART Server | Handles inference and RL coaching loop, manages LoRA checkpoints |
| MCP Server | Exposes the toolset, queried by agent throughout every process |
| State of affairs Engine | Auto-generates artificial numerous process prompts |
| RULER Scorer | Relative reward project for every group of trajectories |
Sensible Integration
- Set up:
pip set up openpipe-art - Flexibility: ART works with native or cloud compute, through vLLM or suitable backends.
- Debugging Instruments: Built-in with W&B, Langfuse, OpenPipe for observability.
- Customizability: Superior customers can tune state of affairs synthesis, reward shaping, batch sizes, LoRA configs.
Abstract
The mixture of MCP- RL and ART abstracts away years of RL automation design, letting you exchange any LLM right into a tool-using, self-improving agent, domain-agnostic and with out annotated coaching knowledge. Whether or not your setting is public APIs or bespoke enterprise servers, the agent learns on-the-job and achieves scalable, sturdy efficiency.
For additional particulars, sensible instance notebooks, and up-to-date benchmarks, go to the ART repository and its [MCP- RL-specific training examples]

Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.

{kind=link}