
Clients migrating from on-premises Oracle databases to AWS face a problem: effectively relocating giant object information varieties (LOBs) to object storage whereas sustaining information integrity and efficiency. This problem originates from the normal enterprise database design the place LOBs are saved alongside structured information, resulting in storage capability constraints, backup complexity, and efficiency bottlenecks throughout information retrieval and processing. LOBs, which might embrace pictures, movies, and different giant recordsdata, typically trigger conventional information migrations to endure from gradual speeds and LOB truncation points. These points are significantly problematic for long-running migrations that may span a number of years.
On this put up, we current a scalable resolution that makes use of Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Aurora PostgreSQL-Suitable Version, and Amazon MSK Join. The info streaming permits information replication the place modifications are despatched and acquired in a steady move, permitting the goal database to entry and apply the adjustments in actual time. This resolution generates occasions for database actions akin to insert, replace, and delete, triggering AWS Lambda capabilities to obtain LOBs from the supply Oracle database and add them to Amazon Easy Storage Service (Amazon S3) buckets. Concurrently, the streaming occasions migrate the structured information from the Oracle database to the goal database whereas sustaining correct linking with their respective LOBs.
The whole implementation is out there on GitHub, together with AWS Cloud Improvement Equipment (AWS CDK) deployment code, configuration recordsdata, and setup directions.
Resolution overview
Though conventional Oracle database migrations deal with structured information successfully, they wrestle with LOBs that may embrace pictures, movies, and paperwork. These migrations typically fail attributable to measurement limitations and truncation points, creating vital enterprise dangers, together with information loss, prolonged downtime, and undertaking delays that may drive you to delay your cloud transformation initiatives. The issue turns into extra acute throughout long-running migrations spanning a number of years, the place sustaining operational continuity is important. This resolution addresses the important thing challenges of LOB migration, enabling steady, long-term operations with out compromising efficiency or reliability.
By eradicating the dimensions limitations related to conventional migration applied sciences, our resolution gives a strong framework that helps you seamlessly relocate LOBs whereas facilitating information integrity all through the method.
Our method makes use of a contemporary streaming structure to alleviate the normal constraints of Oracle LOB migration. The answer contains the next core parts:
- Amazon MSK – Offers the streaming infrastructure.
- Amazon MSK Join – Utilizing two connectors:
- Debezium Connector for Oracle as a supply connector to seize row-level adjustments that happen in Oracle database. The connector emits change occasions and publishes to a Kafka supply subject.
- Debezium Connector for JDBC as a sink connector to eat occasions from Kafka supply subject after which write these occasions to Aurora PostgreSQL-Suitable by utilizing a JDBC driver.
- Lambda operate – Triggered by an occasion supply mapping to Amazon MSK. The operate processes occasions from the Kafka supply subject, extracting the Oracle row main key from every occasion payload. It makes use of this key to obtain the corresponding BLOB information from the supply Oracle database and uploads it to Amazon S3, organizing recordsdata by main key folders to take care of easy linking with the relational database information.
- Amazon RDS for Oracle – Amazon Relational Database Service (Amazon RDS) for Oracle is used because the supply database to simulate an on-premises Oracle database.
- Aurora PostgreSQL-Suitable – Used because the goal database for migrated information.
- Amazon S3 – Used as object storage for storing the BLOB information from supply database.
The next diagram reveals the Oracle LOB information migration structure resolution.
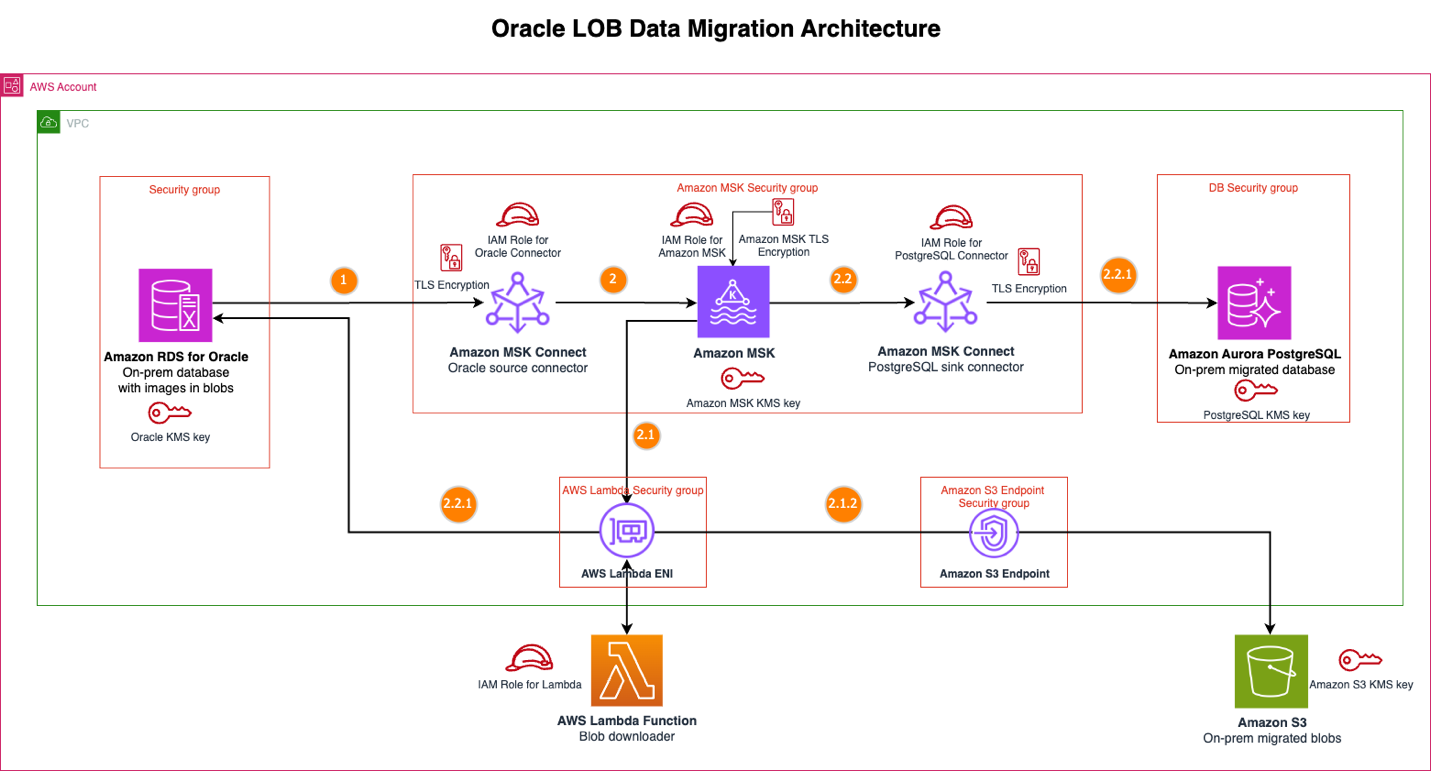
Message move
When information adjustments happen within the supply Amazon RDS for Oracle database, the answer executes the next sequence, transferring by means of occasion detection and publication, BLOB processing with Lambda, and structured information processing:
- The Oracle supply connector captures the change information seize (CDC) occasions, together with the change to BLOB information column. This connector configures the BLOB information column to exclude from the Kafka occasion to optimize the Kafka payload.
- The connector publishes this occasion to an MSK subject.
- The MSK occasion triggers the BLOB Downloader Lambda operate for the CDC occasions.
- The Lambda operate examines two key situations: the Debezium occasion code (particularly checking for create (c) or replace(u)) and the configured listing of Oracle BLOB desk names together with their column names. When a Kafka message matches each the configured desk listing and legitimate Debezium occasions, the Lambda operate initiates the BLOB information obtain from the Oracle supply utilizing the first key and desk identify; in any other case, the operate bypasses the BLOB obtain course of. This selective method makes positive the Lambda operate solely executes SQL queries when processing Kafka messages for tables containing BLOB information, optimizing database interactions.
- The Lambda operate uploads the BLOB to Amazon S3, organizing by main key folders with distinctive object names, which permits linking between structured database information and their corresponding BLOB information in Amazon S3.
- The PostgreSQL sink connector receives the occasion from the MSK subject.
- The connector applies these adjustments to the Aurora PostgreSQL database for the Oracle database adjustments besides the BLOB information column. The BLOB information column is excluded by the Oracle supply connector.
- The MSK occasion triggers the BLOB Downloader Lambda operate for the CDC occasions.
Key advantages
The answer affords the next key benefits:
- Value optimization and licensing – Our method affords vital price optimization advantages by decreasing the general measurement of your database and assuaging your want for costly licenses related to conventional databases and replication applied sciences. By decoupling LOB storage from the database and utilizing Amazon S3, you may scale back your general database footprint and scale back prices related to conventional licensing and replication applied sciences. The streaming structure additionally minimizes your infrastructure overhead throughout long-running migrations.
- Avoids measurement constraints and migration failures – Conventional migration instruments typically impose measurement limitations on LOB transfers, resulting in truncation points and failed migrations. This resolution removes these constraints fully, so you may migrate LOBs of various sizes whereas sustaining information integrity. The event-driven structure permits close to real-time information replication, permitting your supply techniques to stay operational throughout migration.
- Enterprise continuity and operational excellence – Modifications move constantly to your goal atmosphere, permitting for enterprise continuity. The answer preserves relationships between structured database information and their corresponding LOBs by means of main key-based group in Amazon S3, permitting for referential integrity whereas offering the pliability of object storage for big recordsdata.
- Architectural benefits – Storing LOBs in Amazon S3 whereas sustaining structured information in Aurora PostgreSQL-Suitable creates a transparent separation. This structure simplifies your backup and restoration operations, improves question efficiency on structured information, and gives versatile entry patterns for binary objects by means of Amazon S3.
Implementation finest practices
Take into account the next finest practices when implementing this resolution:
- Begin small and scale steadily – To implement this resolution, begin with a pilot undertaking utilizing non-production information to validate your method earlier than committing to full-scale migration. This offers you an opportunity to work out points in a managed atmosphere and refine your configuration with out impacting manufacturing techniques.
- Monitoring – Arrange complete monitoring by means of Amazon CloudWatch to trace key metrics like Kafka lag, Lambda operate errors, and replication latency. Set up alerting thresholds early so you may catch and resolve points rapidly earlier than they influence your migration timeline. Dimension your MSK cluster primarily based on anticipated CDC quantity and configure Lambda reserved concurrency to deal with peak masses throughout preliminary information synchronization.
- Safety – For safety, use encryption in transit and at relaxation for each structured information and LOBs, and observe the precept of least privilege when establishing AWS Id and Entry Administration (IAM) roles and insurance policies to your MSK cluster, Lambda capabilities, S3 buckets, and database situations. Doc your schema mappings between Oracle and Aurora PostgreSQL-Suitable, together with how database information hyperlink to their corresponding LOBs in Amazon S3.
- Testing and preparation – Earlier than you go dwell, take a look at your failover and restoration procedures completely. Validate situations like Lambda operate failures, MSK cluster points, and community connectivity issues to make sure you’re ready for potential points. Lastly, do not forget that this streaming structure maintains eventual consistency between your supply and goal techniques, so there is likely to be temporary lag occasions throughout high-volume durations. Plan your cutover technique with this in thoughts.
Limitations and concerns
Though this resolution gives a strong method for migrating Oracle databases with LOBs to AWS, there are a number of inherent constraints to grasp earlier than implementation.
This resolution requires community connectivity between your supply Oracle database and AWS atmosphere. For on-premises Oracle databases, you could set up AWS Direct Join or VPN connectivity earlier than deployment. Community bandwidth instantly impacts replication pace and general migration efficiency, so your connection should be capable of deal with the anticipated quantity of CDC occasions and LOB transfers.
The answer makes use of Debezium Connector for Oracle because the supply connector and Debezium Connector for JDBC because the sink connector. This structure is particularly designed to your Oracle-to-PostgreSQL migrations. Different database combos require completely different connector configurations or may not be supported by the present implementation. Migration throughput can also be constrained by your MSK cluster capability and Lambda concurrency limits. You too can exceed AWS service quotas for large-scale migrations and also you may must request quota will increase by means of AWS Enterprise Help.
Conclusion
On this put up, we introduced an answer that addresses the important problem of migrating your giant binary objects from Oracle to AWS by utilizing a streaming structure that separates LOB storage from structured information. This method avoids measurement constraints, reduces Oracle licensing prices, and preserves information integrity all through prolonged migration durations.
Prepared to rework your Oracle migration technique? Go to the GitHub repository, the place you can see the entire AWS CDK deployment code, configuration recordsdata, and step-by-step directions to get began.
Concerning the authors

{kind=link}