Snowflake as we speak introduced the general public preview of Snowpark Join for Apache Spark, a brand new providing that enables prospects to run their present Apache Spark code instantly on the Snowflake cloud. The transfer brings Snowflake nearer to what’s supplied by its primary rival, Databricks.
Snowpark Join for Apache Spark lets prospects run their DataFrame, Spark SQL, and Spark consumer outlined perform (UDF) code on Snowflake’s vectorized question engine. This code could possibly be related to a spread of present Spark purposes, together with ETL jobs, information science packages written utilizing Jupyter notebooks, or OLAP jobs that use Spark SQL.
With Snowpark Join for Apache Spark, Snowflake says it handles all of the efficiency tuning and scaling of the Spark code robotically, thereby liberating prospects to concentrate on creating purposes fairly than managing the technically advanced distributed framework beneath them.
“Snowpark Join for Spark delivers the most effective of each worlds: the facility of Snowflake’s engine and the familiarity of Spark code, all whereas decreasing prices and accelerating growth,” write Snowflake product managers Nimesh Bhagat and Shruti Anand in a weblog submit as we speak.
Snowpark Join for Spark relies on Spark Join, an Apache Spark mission that debuted in 2022 and went GA with Spark model 3.4. Spark Join launched a brand new protocol, based mostly on gRPC and Apache Arrow, that enables distant connectivity to Spark clusters utilizing the DataFrame API. Basically, it permits Spark purposes to be damaged up into consumer and server parts, ending the monolithic structured that Spark had used up till then.
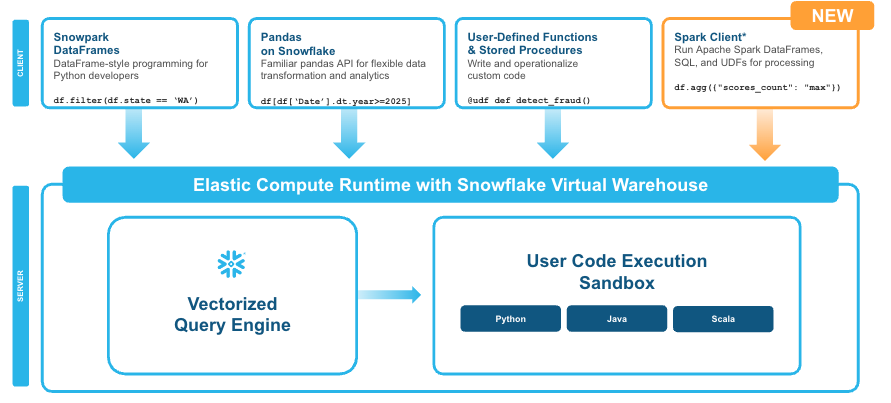
Snowpark Join for Apache Spark lets Snowflake prospects run Spark workloads with out modification (Picture courtesy Snowflake)
This isn’t the primary time Snowflake has enabled prospects to run Spark code on its cloud. It has supplied the Spark Connector, which lets prospects use Spark code to course of Snowflake information. “[B]ut this launched information motion, leading to further prices, latency and governance complexity,” Bhagat and Anand write.
Whereas efficiency improved with transferring Spark to Snowflake, it nonetheless typically meant rewriting code, together with to Snowpark DataFrames, Snowflake says. With the rollout of Snowpark Join for Apache Spark, prospects can now use their Spark code however with out changing code or transferring information, the product managers write.
Prospects can entry information saved in Apache Iceberg tables with their Snowpark Join for Apache Spark purposes, together with externally managed Iceberg tables and catalog-linked tables, the corporate says. The providing runs on Spark 3.5.x solely; Spark RDD, Spark ML, MLlib, Streaming and Delta APIs should not presently a part of Snowpark Join’s supported options, the corporate says.
The launch exhibits Snowflake is keen to tackle Databricks and its substantial base of Spark workloads. Databricks was based by the creators of Apache Spark, and constructed its cloud to be the most effective place to run Spark workloads. Snowflake, however, initially marketed itself because the easy-to-use cloud for purchasers who have been pissed off with the technical complexity of Hadoop-era platforms.
Whereas Databricks acquired its begin with Spark, it has widened its choices significantly over time, and now it’s gearing as much as be a spot to run AI workloads. Snowflake can also be eyeing AI workloads, along with Spark large information jobs.
Associated Objects:
It’s Snowflake Vs. Databricks in Dueling Large Information Conferences
From Monolith to Microservices: The Way forward for Apache Spark
Databricks Versus Snowflake: Evaluating Information Giants

{kind=link}