
Ever puzzled how few LLMs or some instruments course of and perceive your PDFs that encompass a number of tables and pictures? They in all probability use a standard OCR or a VLM (Imaginative and prescient Language Mannequin) beneath the hood. Although it’s price noting that conventional OCR suffers in recognizing handwritten textual content in photographs. It even has points with unusual fonts or characters, like complicated formulae in analysis papers. VLMs do a very good job on this regard, however they might battle in understanding the ordering of tabular knowledge. They could additionally fail to seize spatial relationships like photographs together with their captions.
So what’s the resolution right here? Right here, we discover a latest mannequin that’s targeted on tackling all these points. The SmolDocling mannequin that’s publicly obtainable on Hugging Face. So, with none additional ado, let’s dive in.
Background
The SmolDocling is a tiny however mighty 256M vision-language mannequin designed for doc understanding. Not like heavyweight fashions, it doesn’t want gigs and gigs of VRAM to run. It consists of a imaginative and prescient encoder and a compact decoder skilled to supply DocTags, an XML-style language that encodes format, construction, and content material. Its authors skilled it on hundreds of thousands of artificial paperwork with formulation, tables, and code snippets. Additionally price noting that this mannequin is constructed on high of Hugging Face’s SmolVLM-256M. Within the forthcoming sections, let’s dive a stage deeper and have a look at its structure and demo.
Mannequin Structure
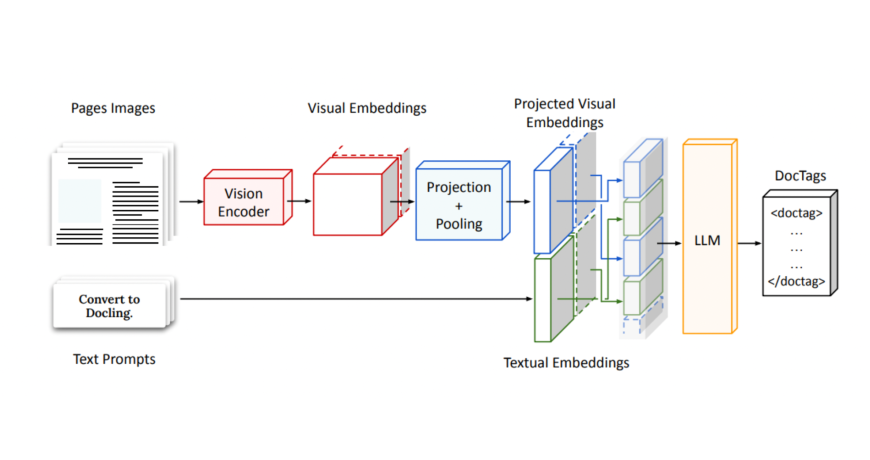
Technically, SmolDocling can be a VLM, but it has a singular structure. The SmolDocling takes in a full-page doc picture and encodes it utilizing a imaginative and prescient encoder, producing dense visible embeddings. These are then projected and pooled into a hard and fast variety of tokens to suit a small decoder’s enter measurement. In parallel, a person immediate is embedded and concatenated with the visible options. This mixed sequence then outputs a stream of structured
SmolDocling Demo
Prerequisite
Be certain to create your Hugging Face account and maintain your entry tokens useful, as we’re going to do that utilizing Hugging Face.
You possibly can get your entry tokens right here.
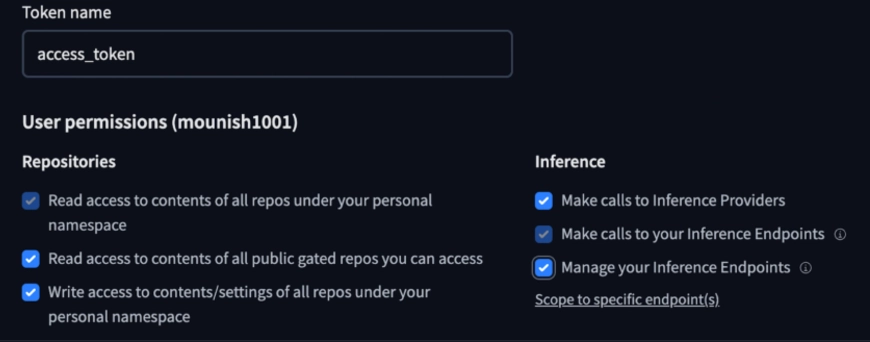
Word: Make sure you give the required permissions, like entry to public repositories, and permit it to make inference calls.
Let’s use a pipeline to load the mannequin (alternatively, you too can select to load the mannequin instantly, which will probably be explored instantly after this one).
Word: This mannequin, as talked about earlier, processes one picture of a doc without delay. You possibly can select to utilize this pipeline to make use of the mannequin a number of instances without delay to course of the entire doc.
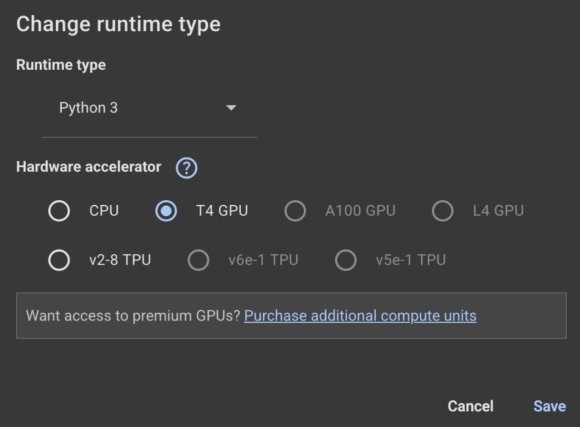
I’ll be utilizing Google Colab (Learn our full information on Google Colab right here) right here. Be certain to vary the runtime to GPU:
from transformers import pipeline
pipe = pipeline("image-text-to-text", mannequin="ds4sd/SmolDocling-256M-preview")
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://cdn.analyticsvidhya.com/wp-content/uploads/2024/05/Intro-1.jpg"},
{"type": "text", "text": "Which year was this conference held?"}
]
},
]
pipe(textual content=messages)I supplied this picture of a earlier Information Hack Summit and requested, “Which 12 months was this convention held?”

SmolDocling Response
{'sort': 'textual content', 'textual content': 'Which 12 months was this convention held?'}]},
{'function': 'assistant', 'content material': ' This convention was held in 2023.'}]}]
Is that this right? In the event you zoom in and look carefully, you will see that that it's certainly DHS 2023. This 256M parameter, with the assistance of the visible encoder, appears to be doing effectively. To see its full potential, you may go a whole doc with complicated photographs and tables as an train.Now let’s attempt to use one other technique to entry the mannequin, loading it instantly utilizing the transformers module:
Right here we are going to go a picture snippet from the SmolDocling analysis paper and get the doctags as output from the mannequin.
The picture we’ll go to the mannequin:
Set up the docking core module first earlier than continuing:
!pip set up docling_core
Loading the mannequin and giving the immediate:
from transformers import AutoProcessor, AutoModelForImageTextToText
from transformers.image_utils import load_image
picture = load_image("/content material/docling_screenshot.png")
processor = AutoProcessor.from_pretrained("ds4sd/SmolDocling-256M-preview")
mannequin = AutoModelForImageTextToText.from_pretrained("ds4sd/SmolDocling-256M-preview")
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Convert this page to docling."}
]
}
]
immediate = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(textual content=immediate, photographs=[image], return_tensors="pt")
generated_ids = mannequin.generate(**inputs, max_new_tokens=8192)
prompt_length = inputs.input_ids.form[1]
trimmed_generated_ids = generated_ids[:, prompt_length:]
doctags = processor.batch_decode(
trimmed_generated_ids,
skip_special_tokens=False,
)[0].lstrip()
print("DocTags output:n", doctags)Displaying the outcomes:
from docling_core.sorts.doc.doc import DocTagsDocument
from docling_core.sorts.doc import DoclingDocument
doctags_doc = DocTagsDocument.from_doctags_and_image_pairs([doctags], [image])
doc = DoclingDocument.load_from_doctags(doctags_doc, document_name="MyDoc")
md = doc.export_to_markdown()
print(md)SmolDocling Output:
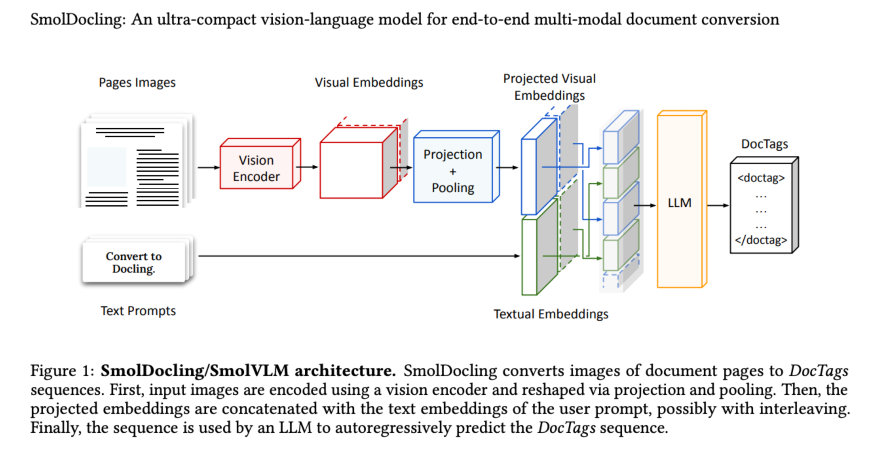
Determine 1: SmolDocling/SmolVLM structure. SmolDocling converts photographs of doc pages to DocTags sequences. First, enter photographs are encoded utilizing a imaginative and prescient encoder and reshaped by way of projection and pooling. Then, the projected embeddings are concatenated with the textual content embeddings of the person immediate, probably with interleaving. Lastly, the sequence is utilized by an LLM to autoregressively predict the DocTags sequence.
Nice to see SmolDocling speaking about SmolDocling. The textual content additionally appears correct. It’s fascinating to consider the potential makes use of of this mannequin. Let’s see a couple of examples of the identical.
Potential Use-cases of SmolDocling
As a imaginative and prescient language mannequin, SmolDocling has ample potential use, like extracting knowledge from structured paperwork e.g. Analysis Papers, Monetary Studies, and Authorized Contracts.
It may well even be used for tutorial functions, like digitizing handwritten notes and digitizing reply copies. One can even create pipelines with SmolDocling as a part in functions requiring OCR or doc processing.
Conclusion
To sum it up, SmolDocling is a tiny but helpful 256M vision-language mannequin designed for doc understanding. Conventional OCR struggles with handwritten textual content and unusual fonts, whereas VLMs usually miss spatial or tabular context. This compact mannequin does a very good job and has a number of use circumstances the place it may be used. In the event you nonetheless haven’t tried the mannequin, go strive it out and let me know in case you face any points within the course of.
Regularly Requested Questions
DocTags are particular tags that describe the format and content material of a doc. They assist the mannequin maintain monitor of issues like tables, headings, and pictures.
Pooling is a layer in neural networks that reduces the dimensions of the enter picture. It helps with sooner processing of information and sooner coaching of the mannequin.
OCR (Optical Character Recognition) is a know-how that turns photographs or scanned paperwork into editable textual content. It’s generally used to digitize printed papers, books, or kinds.
Enthusiastic about know-how and innovation, a graduate of Vellore Institute of Know-how. Presently working as a Information Science Trainee, specializing in Information Science. Deeply concerned about Deep Studying and Generative AI, desirous to discover cutting-edge methods to unravel complicated issues and create impactful options.
Login to proceed studying and revel in expert-curated content material.

{kind=link}