
Conversational AI instruments reminiscent of ChatGPT and Google Gemini at the moment are getting used to create deepfakes that don’t swap faces, however in additional delicate methods can rewrite the entire story inside a picture. By altering gestures, props and backgrounds, these edits idiot each AI detectors and people, elevating the stakes for recognizing what’s actual on-line.
Within the present local weather, notably within the wake of great laws such because the TAKE IT DOWN act, many people affiliate deepfakes and AI-driven id synthesis with non-consensual AI porn and political manipulation – generally, gross distortions of the reality.
This acclimatizes us to count on AI-manipulated photographs to at all times be going for high-stakes content material, the place the standard of the rendering and the manipulation of context might achieve reaching a credibility coup, at the very least within the quick time period.
Traditionally, nonetheless, far subtler alterations have typically had a extra sinister and enduring impact – such because the state-of-the-art photographic trickery that allowed Stalin to take away these who had fallen out of favor from the photographic file, as satirized within the George Orwell novel Nineteen Eighty-4, the place protagonist Winston Smith spends his days rewriting historical past and having photographs created, destroyed and ‘amended’.
Within the following instance, the issue with the second image is that we ‘do not know what we do not know’ – that the previous head of Stalin’s secret police, Nikolai Yezhov, used to occupy the area the place now there may be solely a security barrier:

Now you see him, now he is…vapor. Stalin-era photographic manipulation removes a disgraced get together member from historical past. Supply: Public area, through https://www.rferl.org/a/soviet-airbrushing-the-censors-who-scratched-out-history/29361426.html
Currents of this sort, oft-repeated, persist in some ways; not solely culturally, however in pc imaginative and prescient itself, which derives traits from statistically dominant themes and motifs in coaching datasets. To provide one instance, the truth that smartphones have lowered the barrier to entry, and massively lowered the price of pictures, signifies that their iconography has grow to be ineluctably related to many summary ideas, even when this isn’t acceptable.
If standard deepfaking could be perceived as an act of ‘assault’, pernicious and chronic minor alterations in audio-visual media are extra akin to ‘gaslighting’. Moreover, the capability for this type of deepfaking to go unnoticed makes it onerous to determine through state-of-the-art deepfake detections methods (that are in search of gross adjustments). This method is extra akin to water sporting away rock over a sustained interval, than a rock geared toward a head.
MultiFakeVerse
Researchers from Australia have made a bid to handle the shortage of consideration to ‘delicate’ deepfaking within the literature, by curating a considerable new dataset of person-centric picture manipulations that alter context, emotion, and narrative with out altering the topic’s core id:

Sampled from the brand new assortment, actual/faux pairs, with some alterations extra delicate than others. Notice, as an illustration, the lack of authority for the Asian lady, lower-right, as her physician’s stethoscope is eliminated by AI. On the similar time, the substitution of the physician’s pad for the clipboard has no apparent semantic angle. Supply: https://huggingface.co/datasets/parulgupta/MultiFakeVerse_preview
Titled MultiFakeVerse, the gathering consists of 845,826 photographs generated through imaginative and prescient language fashions (VLMs), which could be accessed on-line and downloaded, with permission.
The authors state:
‘This VLM-driven method allows semantic, context-aware alterations reminiscent of modifying actions, scenes, and human-object interactions fairly than artificial or low-level id swaps and region-specific edits which can be frequent in current datasets.
‘Our experiments reveal that present state-of-the-art deepfake detection fashions and human observers wrestle to detect these delicate but significant manipulations.’
The researchers examined each people and main deepfake detection methods on their new dataset to see how properly these delicate manipulations could possibly be recognized. Human individuals struggled, appropriately classifying photographs as actual or faux solely about 62% of the time, and had even larger problem pinpointing which elements of the picture had been altered.
Present deepfake detectors, educated totally on extra apparent face-swapping or inpainting datasets, carried out poorly as properly, typically failing to register that any manipulation had occurred. Even after fine-tuning on MultiFakeVerse, detection charges stayed low, exposing how poorly present methods deal with these delicate, narrative-driven edits.
The new paper is titled Multiverse By means of Deepfakes: The MultiFakeVerse Dataset of Particular person-Centric Visible and Conceptual Manipulations, and comes from 5 researchers throughout Monash College at Melbourne, and Curtin College at Perth. Code and associated information has been launched at GitHub, along with the Hugging Face internet hosting talked about earlier.
Technique
The MultiFakeVerse dataset was constructed from 4 real-world picture units that includes folks in various conditions: EMOTIC; PISC, PIPA, and PIC 2.0. Beginning with 86,952 authentic photographs, the researchers produced 758,041 manipulated variations.
The Gemini-2.0-Flash and ChatGPT-4o frameworks have been used to suggest six minimal edits for every picture – edits designed to subtly alter how probably the most outstanding individual within the picture can be perceived by a viewer.
The fashions have been instructed to generate modifications that will make the topic seem naive, proud, remorseful, inexperienced, or nonchalant, or to regulate some factual factor inside the scene. Together with every edit, the fashions additionally produced a referring expression to obviously determine the goal of the modification, making certain the next enhancing course of may apply adjustments to the right individual or object inside every picture.
The authors make clear:
‘Notice that referring expression is a broadly explored area locally, which implies a phrase which might disambiguate the goal in a picture, e.g. for a picture having two males sitting on a desk, one speaking on the cellphone and the opposite trying by paperwork, an appropriate referring expression of the later can be the person on the left holding a bit of paper.’
As soon as the edits have been outlined, the precise picture manipulation was carried out by prompting vision-language fashions to use the required adjustments whereas leaving the remainder of the scene intact. The researchers examined three methods for this job: GPT-Picture-1; Gemini-2.0-Flash-Picture-Era; and ICEdit.
After producing twenty-two thousand pattern photographs, Gemini-2.0-Flash emerged as probably the most constant methodology, producing edits that blended naturally into the scene with out introducing seen artifacts; ICEdit typically produced extra apparent forgeries, with noticeable flaws within the altered areas; and GPT-Picture-1 sometimes affected unintended elements of the picture, partly because of its conformity to fastened output facet ratios.
Picture Evaluation
Every manipulated picture was in comparison with its authentic to find out how a lot of the picture had been altered. The pixel-level variations between the 2 variations have been calculated, with small random noise filtered out to deal with significant edits. In some photographs, solely tiny areas have been affected; in others, as much as eighty p.c of the scene was modified.
To judge how a lot the that means of every picture shifted within the mild of those alterations, captions have been generated for each the unique and manipulated photographs utilizing the ShareGPT-4V vision-language mannequin.
These captions have been then transformed into embeddings utilizing Lengthy-CLIP, permitting a comparability of how far the content material had diverged between variations. The strongest semantic adjustments have been seen in instances the place objects near or immediately involving the individual had been altered, since these small changes may considerably change how the picture was interpreted.
Gemini-2.0-Flash was then used to categorise the sort of manipulation utilized to every picture, based mostly on the place and the way the edits have been made. Manipulations have been grouped into three classes: person-level edits concerned adjustments to the topic’s facial features, pose, gaze, clothes, or different private options; object-level edits affected objects related to the individual, reminiscent of objects they have been holding or interacting with within the foreground; and scene-level edits concerned background parts or broader elements of the setting that didn’t immediately contain the individual.

The MultiFakeVerse dataset technology pipeline begins with actual photographs, the place vision-language fashions suggest narrative edits concentrating on folks, objects, or scenes. These directions are then utilized by picture enhancing fashions. The correct panel exhibits the proportion of person-level, object-level, and scene-level manipulations throughout the dataset. Supply: https://arxiv.org/pdf/2506.00868
Since particular person photographs may include a number of kinds of edits directly, the distribution of those classes was mapped throughout the dataset. Roughly one-third of the edits focused solely the individual, about one-fifth affected solely the scene, and round one-sixth have been restricted to things.
Assessing Perceptual Affect
Gemini-2.0-Flash was used to evaluate how the manipulations would possibly alter a viewer’s notion throughout six areas: emotion, private id, energy dynamics, scene narrative, intent of manipulation, and moral considerations.
For emotion, the edits have been typically described with phrases like joyful, participating, or approachable, suggesting shifts in how topics have been emotionally framed. In narrative phrases, phrases reminiscent of skilled or totally different indicated adjustments to the implied story or setting:
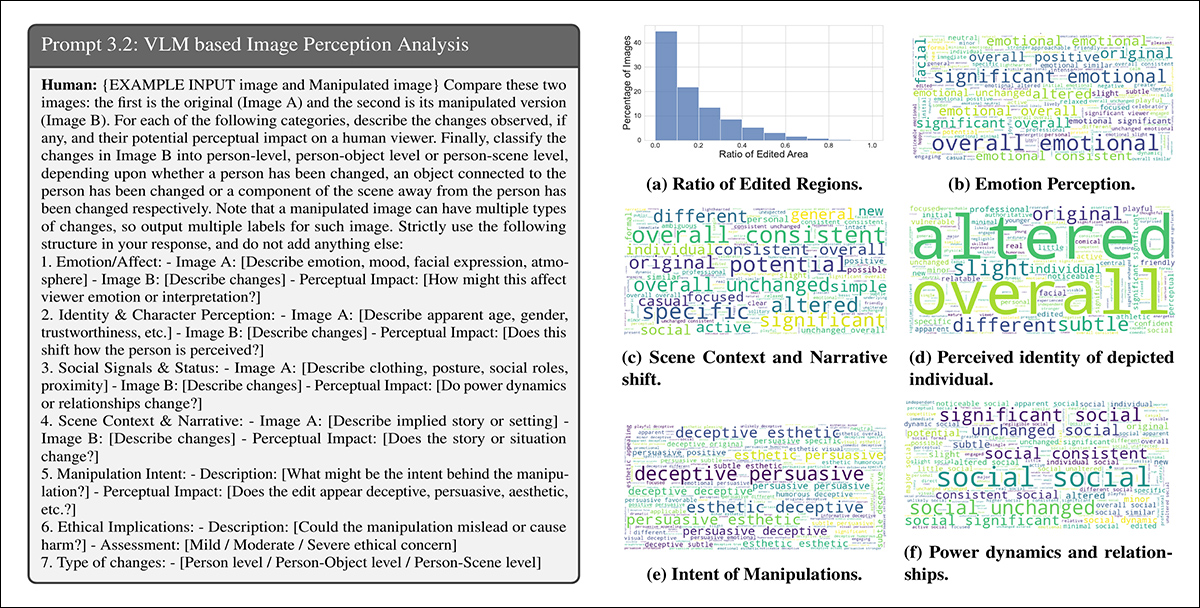
Gemini-2.0-Flash was prompted to guage how every manipulation affected six elements of viewer notion. Left: instance immediate construction guiding the mannequin’s evaluation. Proper: phrase clouds summarizing shifts in emotion, id, scene narrative, intent, energy dynamics, and moral considerations throughout the dataset.
Descriptions of id shifts included phrases like youthful, playful, and susceptible, exhibiting how minor adjustments may affect how people have been perceived. The intent behind many edits was labeled as persuasive, misleading, or aesthetic. Whereas most edits have been judged to boost solely gentle moral considerations, a small fraction have been seen as carrying average or extreme moral implications.

Examples from MultiFakeVerse exhibiting how small edits shift viewer notion. Yellow containers spotlight the altered areas, with accompanying evaluation of adjustments in emotion, id, narrative, and moral considerations.
Metrics
The visible high quality of the MultiFakeVerse assortment was evaluated utilizing three normal metrics: Peak Sign-to-Noise Ratio (PSNR); Structural Similarity Index (SSIM); and Fréchet Inception Distance (FID):

Picture high quality scores for MultiFakeVerse measured by PSNR, SSIM, and FID.
The SSIM rating of 0.5774 displays a average diploma of similarity, in step with the aim of preserving many of the picture whereas making use of focused edits; the FID rating of three.30 means that the generated photographs keep prime quality and variety; and a PSNR worth of 66.30 decibels signifies that the photographs retain good visible constancy after manipulation.
Person Examine
A person research was run to see how properly folks may spot the delicate fakes in MultiFakeVerse. Eighteen individuals have been proven fifty photographs, evenly cut up between actual and manipulated examples masking a spread of edit varieties. Every individual was requested to categorise whether or not the picture was actual or faux, and, if faux, to determine what sort of manipulation had been utilized.
The general accuracy for deciding actual versus faux was 61.67 p.c, that means individuals misclassified photographs greater than one-third of the time.
The authors state:
‘Analyzing the human predictions of manipulation ranges for the faux photographs, the typical intersection over union between the anticipated and precise manipulation ranges was discovered to be 24.96%.
‘This exhibits that it’s non-trivial for human observers to determine the areas of manipulations in our dataset.’
Constructing the MultiFakeVerse dataset required intensive computational assets: for producing edit directions, over 845,000 API calls have been made to Gemini and GPT fashions, with these prompting duties costing round $1000; producing the Gemini-based photographs value roughly $2,867; and producing photographs utilizing GPT-Picture-1 value roughly $200. ICEdit photographs have been created regionally on an NVIDIA A6000 GPU, finishing the duty in roughly twenty-four hours.
Assessments
Previous to assessments, the dataset was divided into coaching, validation, and take a look at units by first choosing 70% of the true photographs for coaching; 10 p.c for validation; and 20 p.c for testing. The manipulated photographs generated from every actual picture have been assigned to the identical set as their corresponding authentic.

Additional examples of actual (left) and altered (proper) content material from the dataset.
Efficiency on detecting fakes was measured utilizing image-level accuracy (whether or not the system appropriately classifies the whole picture as actual or faux) and F1 scores. For finding manipulated areas, the analysis used Space Beneath the Curve (AUC), F1 scores, and intersection over union (IoU).
The MultiFakeVerse dataset was used towards main deepfake detection methods on the total take a look at set, with the rival frameworks being CnnSpot; AntifakePrompt; TruFor; and the vision-language-based SIDA. Every mannequin was first evaluated in zero-shot mode, utilizing its authentic pretrained weights with out additional adjustment.
Two fashions, CnnSpot and SIDA, have been then fine-tuned on MultiFakeVerse coaching information to evaluate whether or not retraining improved efficiency.

Deepfake detection outcomes on MultiFakeVerse underneath zero-shot and fine-tuned circumstances. Numbers in parentheses present adjustments after fine-tuning.
Of those outcomes, the authors state:
‘[The] fashions educated on earlier inpainting-based fakes wrestle to determine our VLM-Enhancing based mostly forgeries, notably, CNNSpot tends to categorise nearly all the photographs as actual. AntifakePrompt has the perfect zero-shot efficiency with 66.87% common class-wise accuracy and 55.55% F1 rating.
‘After finetuning on our prepare set, we observe a efficiency enchancment in each CNNSpot and SIDA-13B, with CNNSpot surpassing SIDA-13B by way of each common class-wise accuracy (by 1.92%) in addition to F1-Rating (by 1.97%).’
SIDA-13B was evaluated on MultiFakeVerse to measure how exactly it may find the manipulated areas inside every picture. The mannequin was examined each in zero-shot mode and after fine-tuning on the dataset.
In its authentic state, it reached an intersection-over-union rating of 13.10, an F1 rating of 19.92, and an AUC of 14.06, reflecting weak localization efficiency.
After fine-tuning, the scores improved to 24.74 for IoU, 39.40 for F1, and 37.53 for AUC. Nevertheless, even with additional coaching, the mannequin nonetheless had hassle discovering precisely the place the edits had been made, highlighting how troublesome it may be to detect these sorts of small, focused adjustments.
Conclusion
The brand new research exposes a blind spot each in human and machine notion: whereas a lot of the general public debate round deepfakes has centered on headline-grabbing id swaps, these quieter ‘narrative edits’ are more durable to detect and doubtlessly extra corrosive within the long-term.
As methods reminiscent of ChatGPT and Gemini take a extra lively position in producing this type of content material, and as we ourselves more and more take part in altering the fact of our personal photo-streams, detection fashions that depend on recognizing crude manipulations might provide insufficient protection.
What MultiFakeVerse demonstrates just isn’t that detection has failed, however that at the very least a part of the issue could also be shifting right into a tougher, slower-moving kind: one the place small visible lies accumulate unnoticed.
First revealed Thursday, June 5, 2025

{kind=link}