
Reinforcement Studying RL post-training is now a serious lever for reasoning-centric LLMs, however in contrast to pre-training, it hasn’t had predictive scaling guidelines. Groups pour tens of 1000’s of GPU-hours into runs with out a principled approach to estimate whether or not a recipe will preserve enhancing with extra compute. A brand new analysis from Meta, UT Austin, UCL, Berkeley, Harvard, and Periodic Labs gives a compute-performance framework—validated over >400,000 GPU-hours—that fashions RL progress with a sigmoidal curve and provides a examined recipe, ScaleRL, that follows these predicted curves as much as 100,000 GPU-hours.
Match a sigmoid, not an influence legislation
Pre-training usually matches energy legal guidelines (loss vs compute). RL fine-tuning targets bounded metrics (e.g., cross charge/imply reward). The analysis staff present sigmoidal matches to cross charge vs coaching compute are empirically extra strong and steady than power-law matches, particularly while you need to extrapolate from smaller runs to bigger budgets. They exclude the very early, noisy regime (~first 1.5k GPU-hours) and match the predictable portion that follows. The sigmoidal parameters have intuitive roles: one units the asymptotic efficiency (ceiling), one other the effectivity/exponent, and one other the midpoint the place positive factors are quickest.
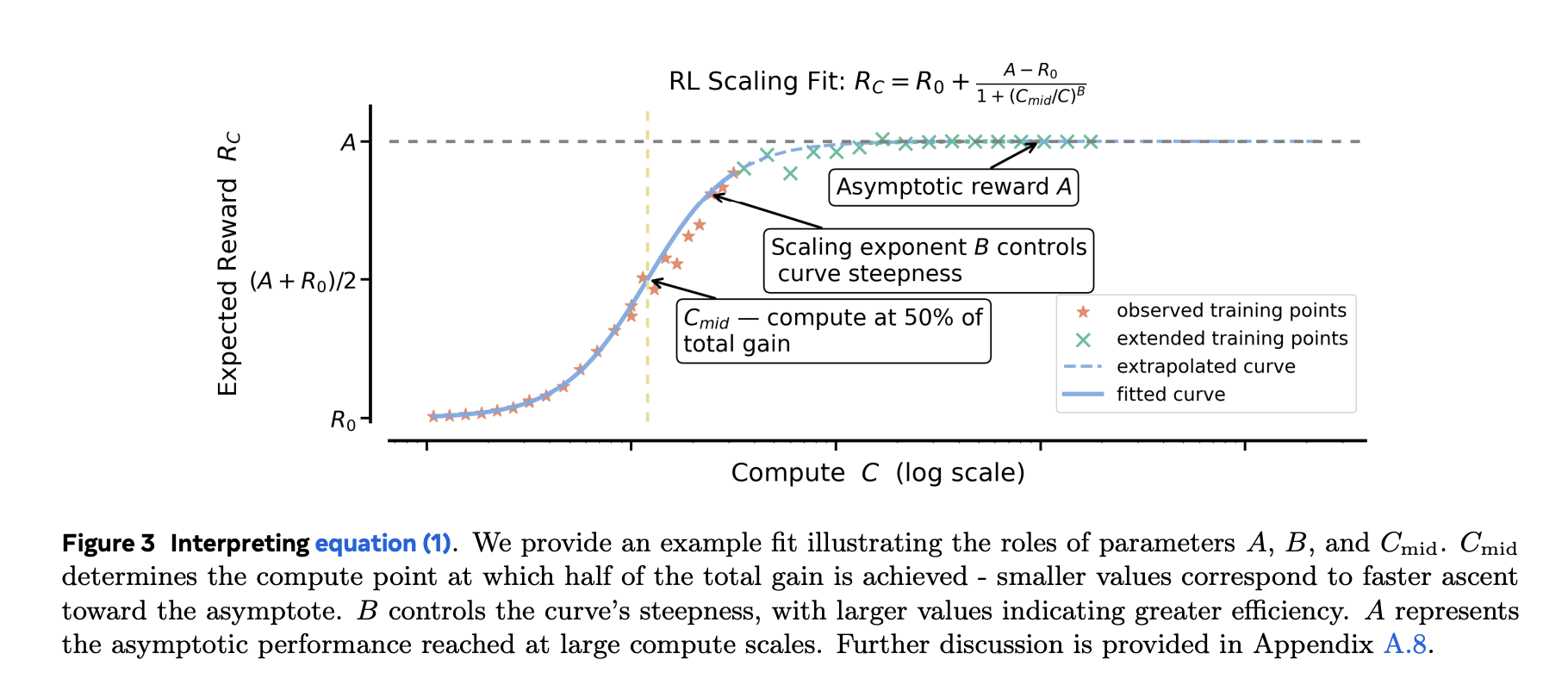
Why that issues: After ~1–2k GPU-hours, you may match the curve and forecast whether or not pushing to 10k–100k GPU-hours is value it—earlier than you burn the price range. The analysis additionally exhibits power-law matches can produce deceptive ceilings except you solely match at very excessive compute, which defeats the aim of early forecasting.
ScaleRL: a recipe that scales predictably
ScaleRL isn’t just new algorithm; it’s a composition of decisions that produced steady, extrapolatable scaling within the examine:
- Asynchronous Pipeline RL (generator–coach break up throughout GPUs) for off-policy throughput.
- CISPO (truncated importance-sampling REINFORCE) because the RL loss.
- FP32 precision on the logits to keep away from numeric mismatch between generator and coach.
- Immediate-level loss averaging and batch-level benefit normalization.
- Compelled size interruptions to cap runaway traces.
- Zero-variance filtering (drop prompts that present no gradient sign).
- No-Constructive-Resampling (take away high-pass-rate prompts ≥0.9 from later epochs).
The analysis staff validated every element with leave-one-out (LOO) ablations at 16k GPU-hours and present that ScaleRL’s fitted curves reliably extrapolate from 8k → 16k, then maintain at a lot bigger scales—together with a single run prolonged to 100k GPU-hours.
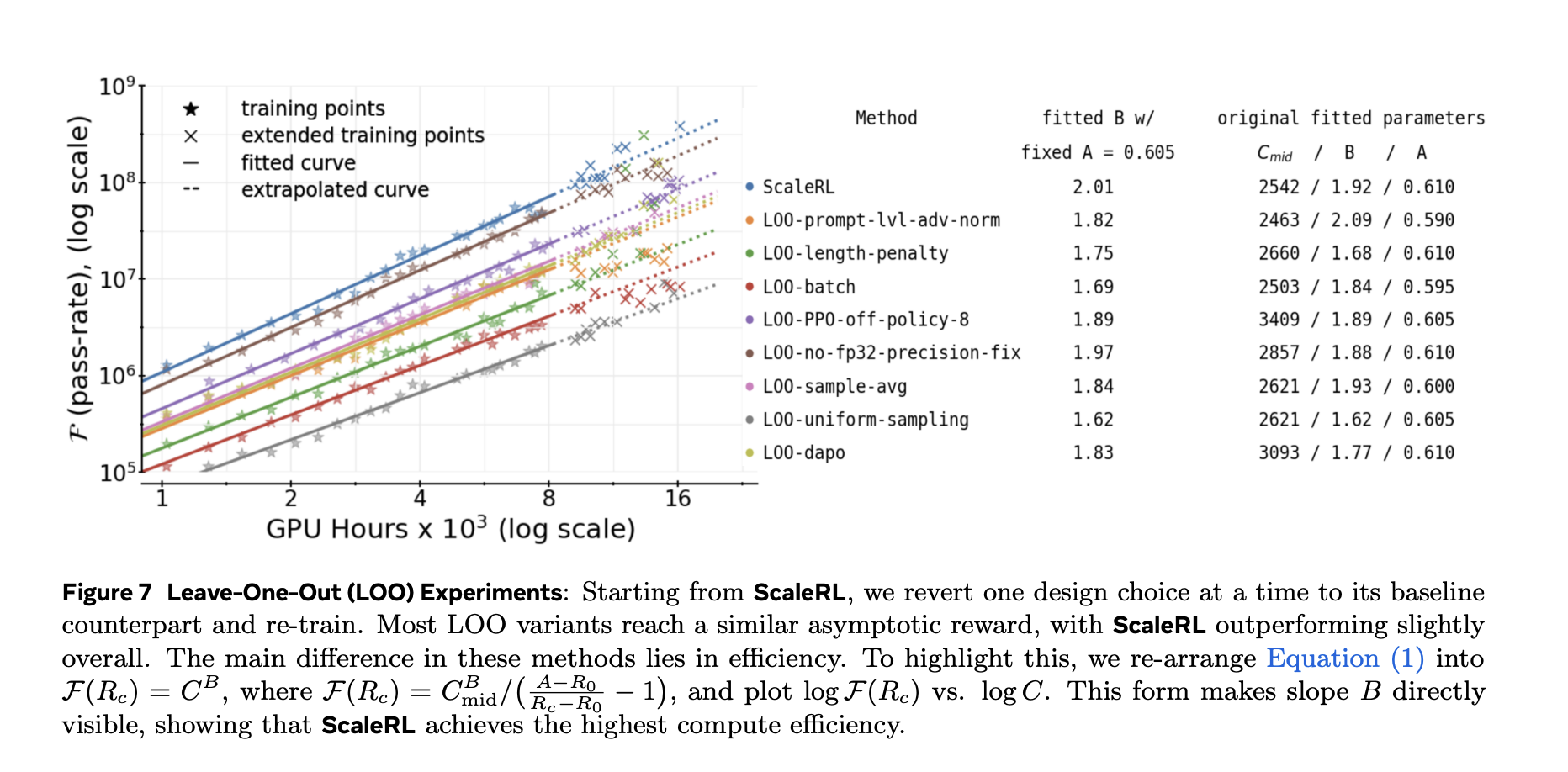
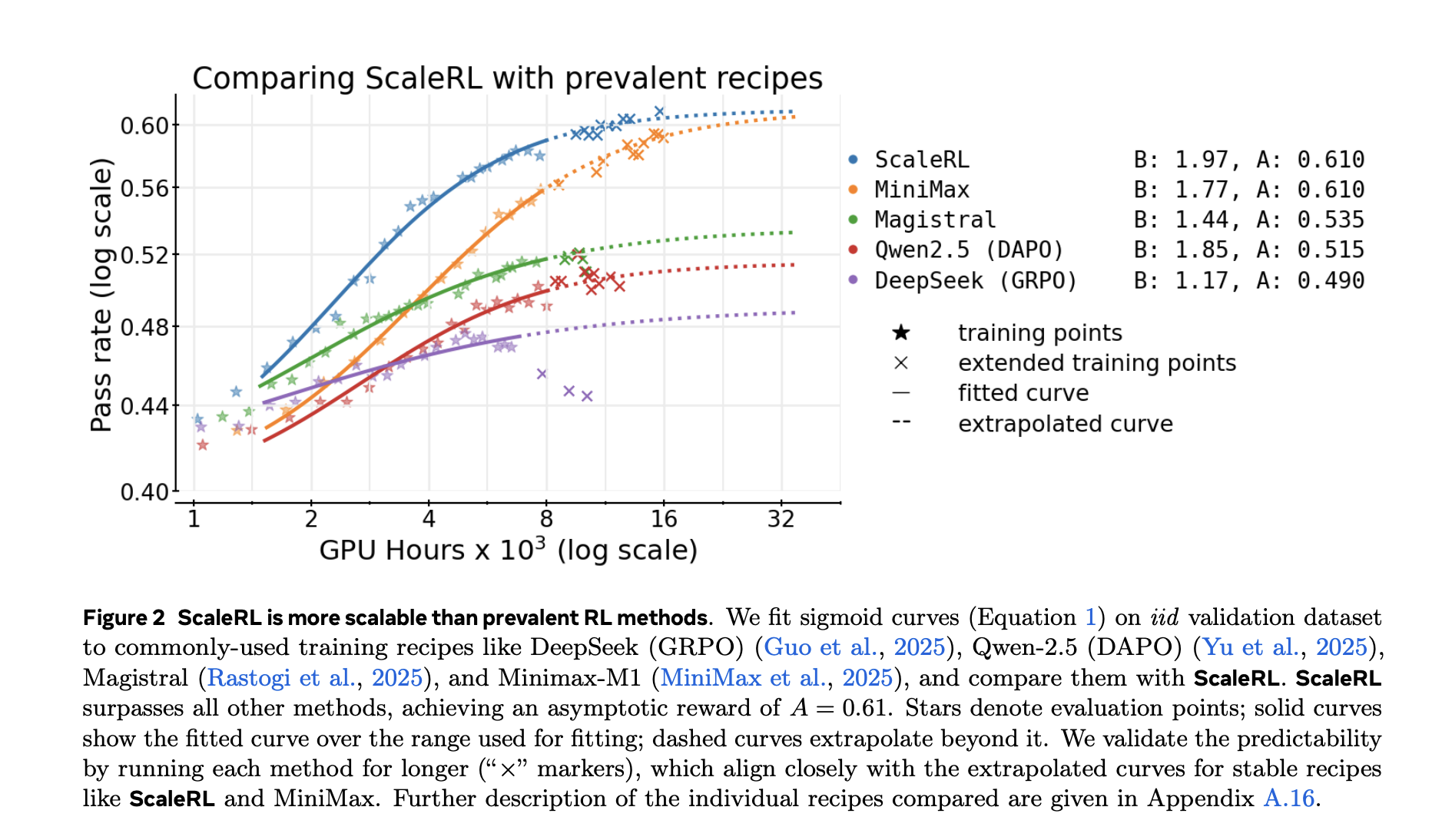
Outcomes and generalization
Two key demonstrations:
- Predictability at scale: For an 8B dense mannequin and a Llama-4 17B×16 MoE (“Scout”), the prolonged coaching carefully adopted the sigmoid extrapolations derived from smaller-compute segments.
- Downstream switch: Go-rate enhancements on an iid validation set monitor downstream analysis (e.g., AIME-24), suggesting the compute-performance curve isn’t a dataset artifact.
The analysis additionally compares fitted curves for prevalent recipes (e.g., DeepSeek (GRPO), Qwen-2.5 (DAPO), Magistral, MiniMax-M1) and experiences greater asymptotic efficiency and higher compute effectivity for ScaleRL of their setup.
Which knobs transfer the ceiling vs the effectivity?
The framework permits you to classify design decisions:
- Ceiling movers (asymptote): scaling mannequin dimension (e.g., MoE) and longer technology lengths (as much as 32,768 tokens) elevate the asymptotic efficiency however might gradual early progress. Bigger world batch dimension also can elevate the ultimate asymptote and stabilize coaching.
- Effectivity shapers: loss aggregation, benefit normalization, knowledge curriculum, and the off-policy pipeline primarily change how briskly you strategy the ceiling, not the ceiling itself.
Operationally, the analysis staff advises becoming curves early and prioritizing interventions that elevate the ceiling, then tune the effectivity knobs to achieve it quicker at fastened compute.
Key Takeaways
- The analysis staff fashions RL post-training progress with sigmoidal compute-performance curves (pass-rate vs. log compute), enabling dependable extrapolation—in contrast to power-law matches on bounded metrics.
- A best-practice recipe, ScaleRL, combines PipelineRL-k (asynchronous generator–coach), CISPO loss, FP32 logits, prompt-level aggregation, benefit normalization, interruption-based size management, zero-variance filtering, and no-positive-resampling.
- Utilizing these matches, the analysis staff predicted and matched prolonged runs as much as 100k GPU-hours (8B dense) and ~50k GPU-hours (17B×16 MoE “Scout”) on validation curves.
- Ablations present some decisions transfer the asymptotic ceiling (A) (e.g., mannequin scale, longer technology lengths, bigger world batch), whereas others primarily enhance compute effectivity (B) (e.g., aggregation/normalization, curriculum, off-policy pipeline).
- The framework gives early forecasting to determine whether or not to scale a run, and enhancements on the in-distribution validation monitor downstream metrics (e.g., AIME-24), supporting exterior validity.
This work turns RL post-training from trial-and-error into forecastable engineering. It matches sigmoidal compute-performance curves (pass-rate vs. log compute) to foretell returns and determine when to cease or scale. It additionally gives a concrete recipe, ScaleRL, that makes use of PipelineRL-style asynchronous technology/coaching, the CISPO loss, and FP32 logits for stability. The examine experiences >400,000 GPU-hours of experiments and a single-run extension to 100,000 GPU-hours. Outcomes assist a clear break up: some decisions elevate the asymptote; others primarily enhance compute effectivity. That separation helps groups prioritize ceiling-moving adjustments earlier than tuning throughput knobs.
Take a look at the PAPER. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}