

TL;DR
- Retrieval-augmented era (RAG) is an AI structure that enhances LLM accuracy by dynamically retrieving related, up-to-date data from exterior data sources
- RAG considerably reduces hallucinations and improves response accuracy in crucial domains like healthcare (96% diagnostic accuracy) and authorized (38-115% productiveness features)
- RAG implementation requires strategic setup, comparable to a curated data base or information storage, optimized chunking methods, and steady monitoring to make sure peak efficiency
Giant language fashions (LLMs) could make harmful errors. And once they do, the results mix monetary penalties and lasting reputational harm.
Within the Mata v. Avianca case, legal professionals relied on ChatGPT’s fabricated citations, triggering judicial sanctions and profession implosions. In one other unlucky occasion, Air Canada misplaced a landmark tribunal case when its chatbot promised refunds the airline by no means approved, proving that “the AI stated it” isn’t a authorized protection.
These disasters share one root trigger – unchecked LLM hallucinations. Normal LLMs function with fastened data cutoffs and no mechanism to confirm information towards authoritative sources. That’s why main enterprises are turning to generative AI corporations to implement retrieval-augmented era (RAG).
So, what’s retrieval-augmented era? And the way does RAG enhance the accuracy of LLM responses?
What’s RAG in LLM, and the way does it work?
Think about asking your sharpest crew member a crucial query once they can solely reply based mostly on what they keep in mind from previous conferences and outdated reviews. They could provide you with an honest reply, nevertheless it’s restricted by what they already know.
Now, assume that the identical particular person has safe, prompt entry to your organization’s data base, documentation, and trusted exterior sources. Their response turns into sooner, sharper, and rooted in information. That’s primarily what RAG does for LLMs.
So, what’s RAG in giant language fashions?
RAG is an AI structure that enhances LLMs by integrating exterior information retrieval into the response course of. As an alternative of relying solely on what the mannequin was educated on, RAG fetches related, up-to-date data from designated sources in actual time. This results in extra correct, context-aware, and reliable outputs.
RAG LLM structure
RAG follows a two-stage pipeline designed to counterpoint LLMs’ responses.
The complete course of begins with the person question. However as a substitute of sending the question straight to the language mannequin, a RAG system first searches for related context. It contacts an exterior data base, which could embody firm paperwork, structured information storages, or reside information from APIs.
To allow quick and significant search, this content material is pre-processed; it’s damaged into smaller, manageable items known as chunks. Every chunk is remodeled right into a numerical format often called an embedding. These embeddings are saved in, for instance, a vector database designed for semantic search.
When the person submits a question, it too is transformed into an embedding and in contrast towards the database. The retriever then returns essentially the most related chunks not simply based mostly on matching phrases, however based mostly on that means, context, and person intent.
As soon as the related chunks are retrieved, they’re paired with the unique question and handed to the LLM. This mixed enter provides the language mannequin each the query and the supporting information it must generate an up-to-date, context-aware response.
In brief, RAG lets LLMs do what they do finest – generate pure language – whereas ensuring they converse from a spot of actual understanding. Right here is how this whole course of appears, from submitting the question to producing a response.
How does RAG enhance the accuracy of LLM responses?
Though LLMs can generate fluent, human-like solutions, they usually battle with staying grounded in actuality. Their outputs could also be outdated or factually incorrect, particularly when utilized to domain-specific or time-sensitive duties. Right here’s how RAG advantages LLMs:
- Hallucination discount. LLMs generally make issues up. This may be innocent in informal use however turns into a severe legal responsibility in high-stakes environments like authorized, healthcare, or finance, the place factual errors can’t be tolerated. So, the right way to scale back hallucination in giant language fashions utilizing RAG?
- RAG grounds the mannequin’s output in actual, verifiable information by feeding it solely related data retrieved from trusted sources. This drastically reduces the chance of fabricated content material. In a current examine, a crew of researchers demonstrated how incorporating RAG into an LLM pipeline decreased the fashions’ tendency to hallucinate tables from 21% to only 4.5%.
- Actual-time information integration. Conventional LLMs are educated on static datasets. As soon as the coaching is over, they haven’t any consciousness of occasions or developments that occur afterward. This data cutoff limits their usefulness in fast-moving industries.
- By retrieving information from reside sources like up-to-date databases, paperwork, or APIs, RAG permits the mannequin to include present data throughout inference. That is just like giving the mannequin a reside feed as a substitute of a frozen snapshot.
- Area adaptation. Basic-purpose LLMs usually underperform when utilized to specialised domains. They might lack the precise vocabulary, context, or nuance wanted to deal with technical queries or industry-specific workflows.
- As an alternative of retraining the mannequin from scratch, RAG permits prompt area adaptation by connecting it to your organization’s proprietary data – technical manuals, buyer assist logs, compliance docs, or {industry} information storage.
Some can argue that corporations can obtain the identical impact by fine-tuning LLMs. However are these methods the identical?
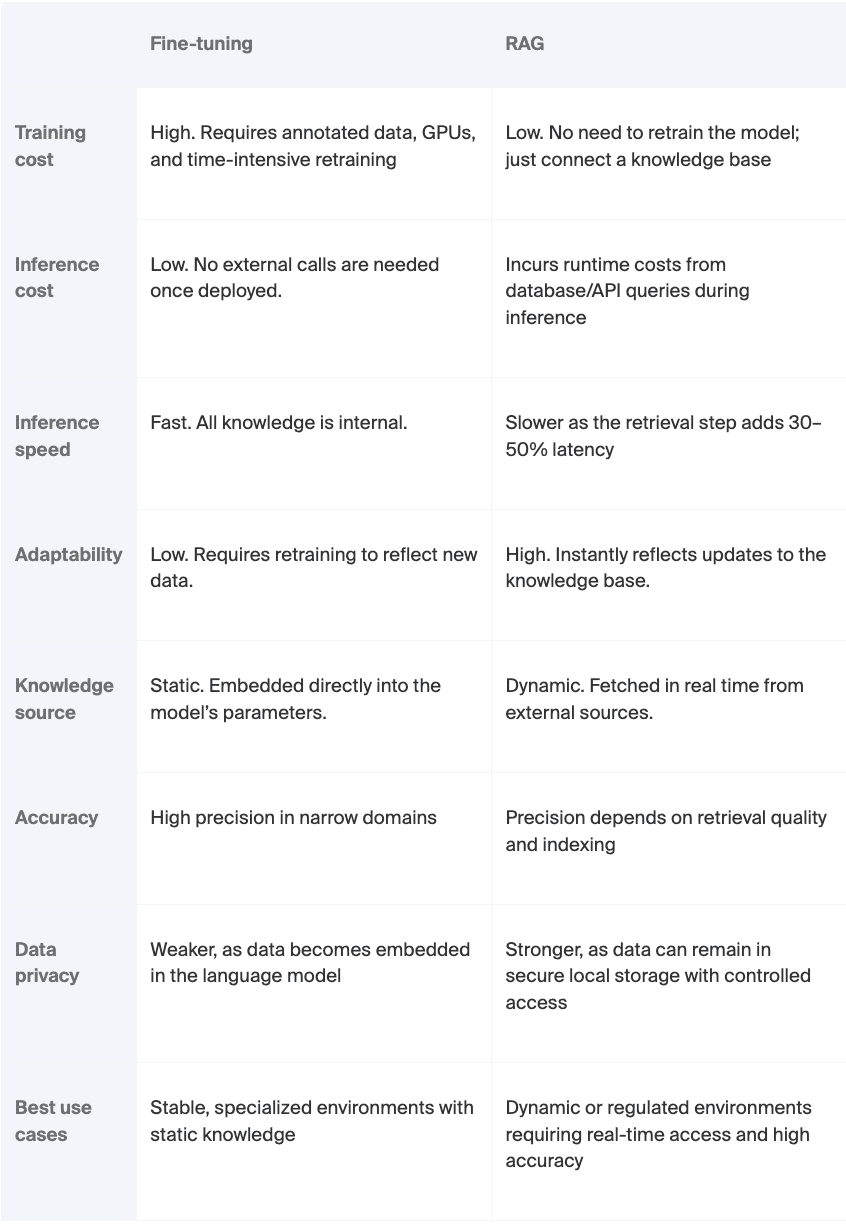
RAG vs. fine-tuning for enhancing LLM precision
Whereas each RAG and LLM fine-tuning purpose to enhance accuracy and relevance, they achieve this in numerous methods – and every comes with trade-offs.
Advantageous-tuning includes modifying the mannequin itself by retraining it on domain-specific information. It could actually produce robust outcomes however is resource-intensive and rigid. And after retraining, fashions but once more develop into static. RAG, however, retains the mannequin structure intact and augments it with exterior data, enabling dynamic updates and simpler scalability.
Press enter or click on to view picture in full dimension
Press enter or click on to view picture in full dimension
Moderately than viewing these approaches as mutually unique, corporations could acknowledge that the simplest resolution usually combines each methods. For companies coping with a fancy language like authorized or medical and fast-changing information, comparable to regulatory updates or monetary information, a hybrid method can ship the perfect of each worlds.
And when ought to an organization think about using RAG?
Use RAG when your software will depend on up-to-date, variable, or delicate data (suppose buyer assist methods pulling from ever-changing data bases, monetary dashboards that should mirror present market information, or inner instruments that depend on proprietary paperwork.) RAG shines in dynamic environments the place information change usually and the place retraining a mannequin each time one thing updates is neither sensible nor cost-effective.
Influence of RAG on LLM response efficiency in real-world purposes
The implementation of RAG in LLM methods is delivering constant, measurable enhancements throughout various sectors. Listed here are real-life examples from three completely different industries that attest to the know-how’s transformative affect.
RAG LLM examples in healthcare
Within the medical subject, misinformation can have severe penalties. RAG in LLMs supplies evidence-based solutions by accessing the newest medical analysis, medical tips, or affected person information.
- In diagnosing gastrointestinal circumstances from pictures, a RAG-boosted GPT-4 mannequin achieved 78% accuracy – a whopping 24-point bounce over the bottom GPT-4 mannequin – and delivered at the very least one right differential prognosis 98% of the time in comparison with 92% for the bottom mannequin.
- To enhance human experience in most cancers prognosis and medical analysis, IBM Watson makes use of RAG that retrieves data from medical literature and affected person information to ship therapy options. When examined, this technique matched knowledgeable suggestions in 96% of the instances.
- In medical trials, the RAG-powered RECTIFIER system outperformed human employees in screening sufferers for the COPILOT-HF trial, attaining 93.6% general accuracy vs. 85.9% for human consultants.
RAG LLM examples within the authorized analysis
Authorized professionals spend numerous hours sifting by case information, statutes, and precedents. RAG supercharges authorized analysis by providing prompt entry to related instances and guaranteeing compliance and accuracy whereas enhancing employee productiveness. Listed here are some examples:
- Vincent AI, a RAG-enabled authorized instrument, was examined by legislation college students throughout six authorized assignments. It improved productiveness by 38%-115% in 5 out of six duties.
- LexisNexis, an information analytics firm for authorized and regulatory providers, makes use of RAG structure to continuously combine new authorized priority into its LLM instruments. This permits authorized researchers to retrieve the newest data when engaged on a case.
RAG LLM examples within the monetary sector
Monetary establishments depend on real-time, correct information. But, conventional LLMs danger outdated or generic responses. RAG transforms finance by together with current market intelligence, enhancing buyer assist, and extra. Think about these examples:
- Wells Fargo deploys Reminiscence RAG to facilitate analyzing monetary paperwork for advanced duties. The corporate examined this method through the earnings calls, and it displayed an accuracy degree of 91% with a mean response time of 5.76 seconds.
- Bloomberg depends on RAG-driven LLMs to generate summaries of related information and monetary reviews to maintain its analysts and buyers knowledgeable.
What are the challenges and limitations of RAG in LLMs?
Regardless of all the advantages, when implementing RAG in LLMs, corporations can encounter the next challenges:
- Incomplete or irrelevant retrieval. Companies can face points the place important data is lacking from the data base or solely loosely associated content material is retrieved. This will result in hallucinations or overconfident however incorrect responses, particularly in delicate domains. Guaranteeing high-quality, domain-relevant information and enhancing retriever accuracy is essential.
- Ineffective context utilization. Even with profitable retrieval, related data is probably not correctly built-in into the LLM’s context window because of poor chunking or data overload. Consequently, crucial information will be ignored or misunderstood. Superior chunking, semantic grouping, and context consolidation methods assist deal with this.
- Unreliable or deceptive output. With ambiguous queries and poor immediate design, RAG for LLMs can nonetheless produce incorrect or incomplete solutions, even when the fitting data is current. Refining prompts, filtering noise, and utilizing reasoning-enhanced era strategies can enhance output constancy.
- Excessive operational overhead and scalability limits. Deploying RAG in LLM provides system complexity, ongoing upkeep burdens, and latency. With out cautious design, it may be expensive, biased, and exhausting to scale. To proactively deal with this, corporations must plan for infrastructure funding, bias mitigation, and value administration methods.
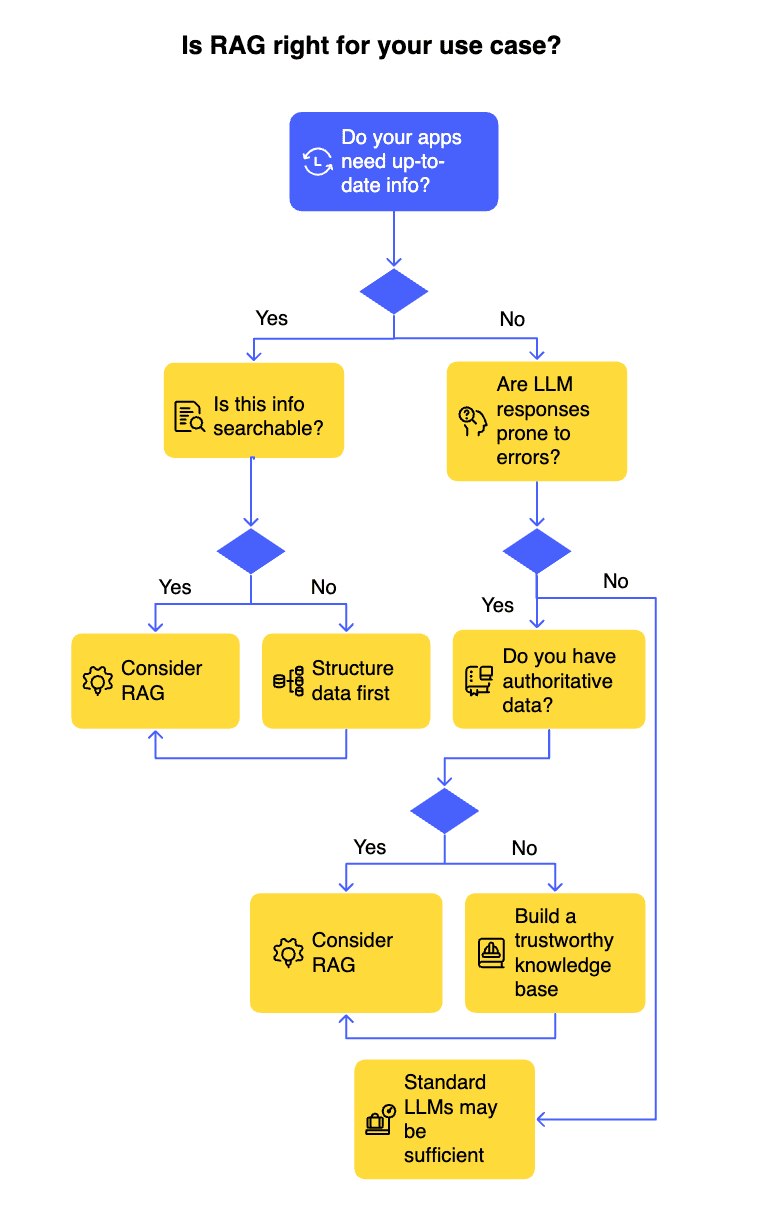
Finest practices for implementing RAG in enterprise LLM options
Nonetheless uncertain if RAG is best for you? This straightforward chart will assist decide whether or not normal LLMs meet your wants or if RAG’s enhanced capabilities are the higher match.
Press enter or click on to view picture in full dimension
Through the years of working with AI, ITRex consultants collected a listing of useful suggestions. Listed here are our greatest practices for optimizing RAG efficiency in LLM deployment:
Curate and clear your data base/information storage
If the underlying information is messy, redundant, not distinctive, or outdated, even essentially the most superior RAG pipeline will retrieve irrelevant or contradictory data. This undermines person belief and can lead to hallucinations that stem not from the mannequin, however from poor supply materials. In high-stakes environments, like finance and healthcare, misinformation can carry regulatory or reputational dangers.
To keep away from this, make investments time in curating your information storage and data base. Take away out of date content material, resolve contradictions, and standardize codecs the place attainable. Add metadata to tag doc sources and dates. Automating periodic critiques of content material freshness will maintain your data base clear and dependable.
Use sensible chunking methods
Poorly chunked paperwork – whether or not too lengthy, too quick, or arbitrarily segmented – can fragment that means, strip crucial context, or embody irrelevant content material. This will increase the chance of hallucinations and degrades response high quality.
The optimum chunking method varies based mostly on doc kind and use case. For structured information like authorized briefs or manuals, layout-aware chunking preserves logical move and improves interpretability. For unstructured or advanced codecs, semantic chunking – based mostly on that means quite than format – produces higher outcomes. As enterprise information more and more contains charts, tables, and multi-format paperwork, chunking should evolve to account for each construction and content material.
Advantageous-tune your embedding mannequin
Out-of-the-box embedding fashions are educated on normal language, which can not seize domain-specific terminology, acronyms, or relationships. In specialised industries like authorized or biotech, this results in mismatches, the place semantically right phrases get ignored and vital domain-specific ideas are ignored.
To unravel this, fine-tune the embedding mannequin utilizing your inner paperwork. This enhances the mannequin’s “understanding” of your area, enhancing the relevance of retrieved chunks. You may also use hybrid search strategies – combining semantic and keyword-based retrieval – to additional enhance precision.
Monitor retrieval high quality and set up suggestions loops
A RAG pipeline is just not “set-and-forget.” If the retrieval part frequently surfaces irrelevant or low-quality content material, customers will lose belief and efficiency will degrade. With out oversight, even strong methods can drift, particularly as your organization’s paperwork evolve or person queries shift in intent.
Set up monitoring instruments that monitor which chunks are retrieved for which queries and the way these affect ultimate responses. Accumulate person suggestions or run inner audits on accuracy and relevance. Then, shut the loop by refining chunking, retraining embeddings, or adjusting search parameters. RAG methods enhance considerably with steady tuning.
What’s subsequent for RAG in LLMs, and the way ITRex might help
The evolution of RAG know-how is way from over. We’re now seeing thrilling advances that can make these methods smarter, extra versatile, and lightning-fast. Listed here are three game-changing developments main the cost:
- Multimodal RAG (MRAG). This method can deal with a number of information varieties – pictures, video, and audio – in each retrieval and era, permitting LLMs to function on advanced, real-world content material codecs, comparable to internet pages or multimedia paperwork, the place content material is distributed throughout modalities. MRAG mirrors the way in which people synthesize visible, auditory, and textual cues in context-rich environments.
- Self-correcting RAG loops. Typically, an LLM’s reply can diverge from information, even when RAG retrieves correct information. Self-correcting RAG loops can resolve this difficulty, as they dynamically confirm and alter reasoning throughout inference. This transforms RAG from a one-way information move into an iterative course of, the place every generated response informs and improves the following retrieval.
- Combining RAG with small language fashions (SLM). This pattern is a response to the rising demand for personal, responsive AI on units like smartphones, wearables, and IoT sensors. SLMs are compact fashions, usually beneath 1 billion parameters, which might be well-suited for edge AI environments the place computational assets are restricted. By pairing SLMs with RAG, organizations can deploy clever methods that course of data domestically.
Prepared to begin exploring RAG?
Go from AI exploration to AI experience with ITRex
At ITRex, we keep carefully tuned to the newest developments in AI and apply them the place they take advantage of affect. With hands-on expertise in generative AI, RAG, and edge deployments, our crew creates AI methods which might be as sensible as they’re progressive. Whether or not you’re beginning small or scaling huge, we’re right here to make AI be just right for you.
FAQs
- What are the primary advantages of utilizing RAG in LLMs?
RAG enhances LLMs by grounding their responses in exterior, up-to-date data. This leads to extra correct, context-aware, and domain-specific solutions. It reduces the reliance on static coaching information and permits dynamic adaptation to new data. RAG additionally will increase transparency, as it may possibly cite its sources.
- Can RAG assist scale back hallucination in AI-generated content material?
Sure, RAG reduces LLM hallucination by tying the mannequin’s responses to verified content material. When solutions are generated based mostly on exterior paperwork, there’s a decrease probability the mannequin will “make issues up.” That stated, hallucinations can nonetheless happen if the LLM misinterprets or misuses the retrieved content material.
- Is RAG efficient for real-time or continuously altering data?
Completely. RAG shines in dynamic environments as a result of it may possibly retrieve the newest information from exterior sources on the time of question. This makes it very best to be used instances like information summarization, monetary insights, or buyer assist. Its skill to adapt in real-time provides it a serious edge over static LLMs.
- How can RAG be carried out in current AI workflows?
RAG will be built-in as a modular part alongside current LLMs. Sometimes, this integration includes establishing a retrieval system, like a vector database, connecting it with the LLM, and designing prompts that incorporate retrieved content material. With the fitting infrastructure, groups can progressively layer RAG onto present pipelines with out a full overhaul.
Initially revealed at https://itrexgroup.com on June 24, 2025.
;

{kind=link}