
Giant Language Fashions (LLMs) have revolutionized fields from pure language understanding to reasoning and code era. Nonetheless, pushing their reasoning capacity to actually superhuman ranges has been restricted by the necessity for enormous, high-quality, human-annotated datasets. A workforce of researchers from Tencent AI Seattle Lab, Washington College, the College of Maryland, and the College of Texas have proposed R-Zero, a framework designed to coach reasoning LLMs that may self-evolve with out counting on exterior knowledge labels.
Past Human-Curated Knowledge
Most progress in LLM reasoning is tethered to datasets laboriously curated by people, an strategy that’s resource-intensive and essentially restricted by human data. Even label-free strategies utilizing LLMs’ personal outputs for reward alerts nonetheless rely on present collections of unsolved duties or issues. These dependencies bottleneck scalability and hinder the dream of open-ended AI reasoning past human capabilities.
R-Zero: Self-Evolution from Zero Knowledge
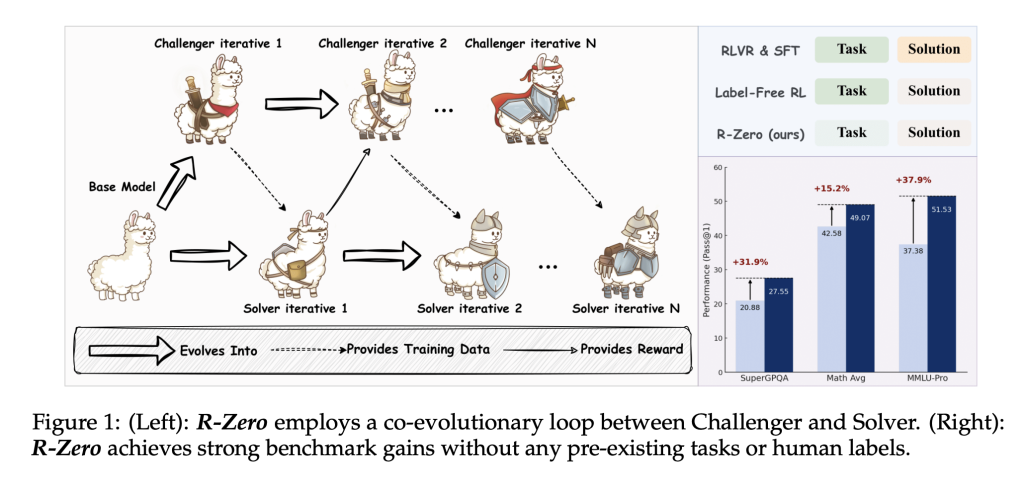
R-Zero forges a novel path by totally eradicating the reliance on exterior duties and labels. As a substitute, it introduces a co-evolutionary dynamic between two situations of a base mannequin:
- Challenger: Answerable for creating new, difficult reasoning duties close to the sting of the Solver’s functionality.
- Solver: Educated to resolve more and more tough issues posed by the Challenger, bettering iteratively.
This synergy permits the curriculum—the set of coaching knowledge—to be self-generated and tailored repeatedly to the mannequin’s evolving strengths and weaknesses. The method works as follows:
- Challenger Coaching: Educated by way of reinforcement studying (particularly Group Relative Coverage Optimization [GRPO]), it generates numerous, hard-to-solve questions. The reward sign for every query relies on the Solver’s uncertainty: highest when Solver’s solutions are maximally inconsistent (empirical accuracy approaches 50%).
- Solver Coaching: Solver is fine-tuned on the Challenger’s curated issues. Pseudo-labels (solutions) are decided by majority vote amongst Solver’s personal responses. Solely questions with solutions neither too constant nor too scattered (i.e., in an informative band) are used for coaching.
- Iterative Loop: Challenger and Solver alternate roles, co-evolving over a number of rounds, progressively bettering reasoning talents with out human intervention.
Key Technical Improvements
- Group Relative Coverage Optimization (GRPO)
GRPO is a reinforcement studying algorithm that normalizes the reward for every generated reply relative to the group of responses for a similar immediate. This methodology effectively fine-tunes coverage LLMs with out a separate worth perform. - Uncertainty-Pushed Curriculum
The Challenger is rewarded for producing issues on the Solver’s frontier—neither too straightforward nor inconceivable. The reward perform peaks for duties the place the Solver achieves 50% accuracy, maximizing studying effectivity per theoretical evaluation. - Repetition Penalty and Format Checks
To ensure numerous and well-structured coaching knowledge, a repetition penalty discourages comparable questions inside a batch, and strict format checks guarantee knowledge high quality. - Pseudo-Label High quality Management
Solely question-answer pairs with intermediate reply consistency are used for coaching, filtering out ambiguous or ill-posed issues and calibrating label accuracy.

Empirical Efficiency
Mathematical Reasoning Benchmarks
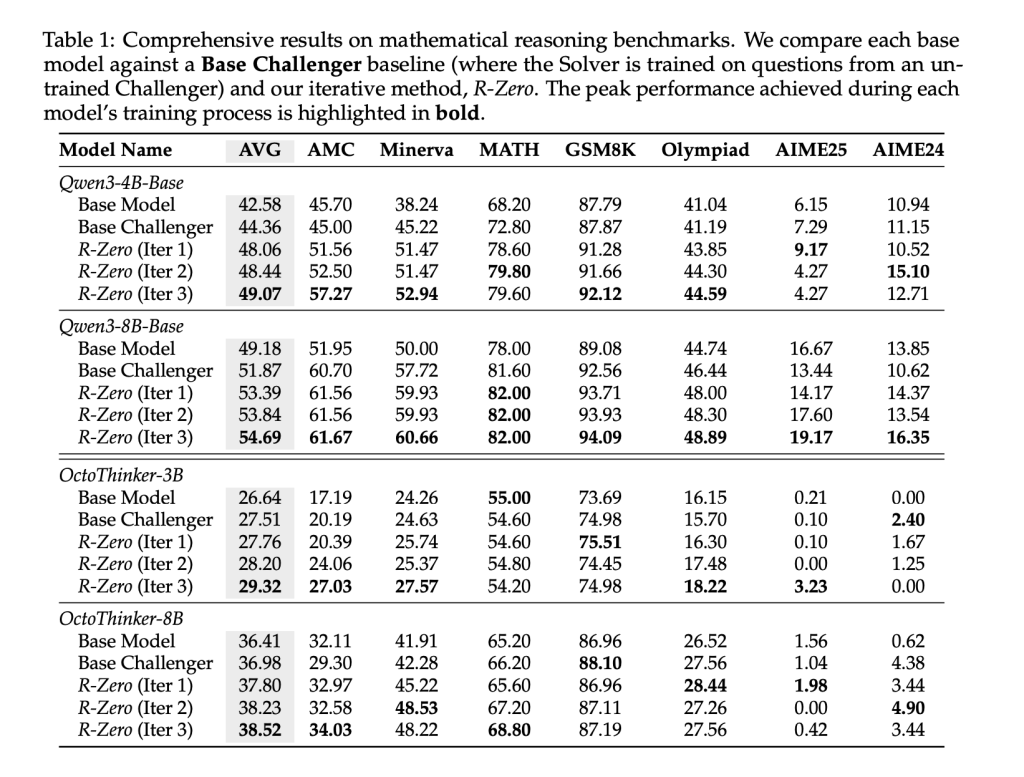
R-Zero was evaluated utilizing seven rigorous mathematical benchmarks, together with AMC, Minerva, MATH-500, GSM8K, Olympiad-Bench, and AIME competitions. In contrast with the bottom mannequin and non-trained Challenger baseline, three iterations of R-Zero led to substantial enhancements in reasoning accuracy throughout all mannequin sizes and architectures (e.g., Qwen3-8B-Base improved from 49.18 to 54.69 common rating after three iterations).
Normal Reasoning Benchmarks
Crucially, R-Zero’s enhancements generalize past math. Benchmarks together with MMLU-Professional, SuperGPQA, and BIG-Bench Additional Exhausting (BBEH) present important positive factors in general-domain reasoning accuracy (e.g., Qwen3-8B-Base’s total common jumps from 34.49 to 38.73), demonstrating robust switch results.
Conclusion
R-Zero marks a serious milestone towards self-sufficient, superhuman reasoning LLMs. Its totally autonomous co-evolutionary coaching pipeline gives not solely robust empirical positive factors in reasoning however a brand new lens by which to view scalable, data-free AI improvement. Researchers and practitioners can experiment with this framework right now, leveraging open-source instruments to pioneer the following period of reasoning-centric language fashions.
Try the Paper and GitHub Web page. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a give attention to understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.

{kind=link}