")
AI brokers are altering how we use know-how. Powered by giant language fashions, they’ll reply questions, full duties, and join with information or APIs. However they nonetheless make errors, particularly with advanced, multi-step work, and fixing that manually takes effort and time.
Microsoft’s new Agent Lightning framework makes this simpler. It separates how an agent runs from the way it learns, so it may possibly enhance by means of its personal real-world interactions. You possibly can take any current chat or automation setup and apply reinforcement studying, serving to your agent get smarter simply by doing its job.
What’s Microsoft Agent Lightning?
Agent Lightning is an open-source framework developed by Microsoft. It’s used to coach and enhance AI brokers by means of reinforcement studying (RL). The energy of agent lightning is that it may be wrapped round any brokers which can be already developed utilizing any framework (resembling LangChain, OpenAI Brokers SDK, AutoGen, CrewAI, LangGraph, or customized Python) with virtually zero code modifications.
To be extra technical, it permits reinforcement-learning coaching of the LLM’s hosted inside brokers, with out altering the agent’s core logic. The fundamental thought is to think about the agent’s execution as a Markov Resolution Course of. Which states “At each step the agent is in a state, takes an motion (LLM output), and receives some reward when these actions lead to profitable process completion.”
The framework consists of a Python SDK and a coaching server. Merely wrap the logic of your agent right into a LitAgent class or related interface, outline how you can rating its output (the reward), and you might be prepared to coach. Agent Lightning does the work of accumulating these experiences, stimulates the agent into your hierarchical RL algorithm (LightningRL) for credit score task, and updates the mannequin or immediate template of your agent. After coaching you now have an agent that has improved its efficiency.
Why Agent Lightning Issues?
Typical agent frameworks (resembling LangChain, LangGraph, CrewAI or AutoGen) enable for the creation of AI brokers that may cause in a step-by-step method or make the most of instruments, however they don’t have a coaching element. These brokers merely run the mannequin on static mannequin parameters or prompts, that means they can’t study from their encounters. Actual-world challenges have a point of complexity, requiring some degree of adaptability. Agent Lightning addresses this, bringing studying into the agent pipeline.
Agent Lightning addresses this anticipated hole by implementing an automatic optimizing pipeline for brokers. It does this by the facility of reinforcement studying to replace the brokers coverage based mostly on suggestions alerts. Merely, your brokers will now study out of your agent’s success and failure doubtlessly yielding extra dependable and reliable outcomes.
How Agent Lightning Works?
Inside the server-client, Agent Lightning makes use of an RL algorithm, which is designed to generate duties and tuning proposals; this contains both the brand new prompts or mannequin weights. Now duties are executed by a Runner, which collects the agent’s actions and last rewards and returns that information to the Algorithm. This suggestions loop permits the agent to additional fine-tune its prompts or weights over time, using a characteristic referred to as ‘Computerized Intermediate Rewarding’ that permits for smaller, instantaneous rewards for profitable intermediate actions to speed up the training course of.
Agent Lightning primarily treats agent operation as a cycle: The state is its present context; the motion is its subsequent transfer, and the reward is the indicator of process success. By designing state-action-reward transitions, Agent Lightning can finally facilitate coaching for any form of agent.
Agent Lightning makes use of an Agent Disaggregation design; this separate studying from execution. The Server is chargeable for updating and optimization, and the Shopper is chargeable for using actual duties and reporting outcomes. The division of duties permits the agent to meet its process effectively, whereas additionally bettering efficiency by way of RL.
Notice: Agent Lightning makes use of LightningRL. It’s a hierarchical RL system that breaks down advanced multi-step agent conduct’s for coaching. LightningRL may assist a number of brokers, advanced software utilization, and delayed suggestions.
Step-by-Step Information: Coaching an Agent Utilizing Microsoft Agent Lightning
On this part, we’ll cowl a walkthrough of coaching a SQL agent with Agent-lightning and demonstrates the combination of the first parts of the system: a LangGraph-based SQL agent, the VERL RL framework, and the Coach for controlling coaching and debugging.
The command-line instance (examples/spider/train_sql_agent.py) offers an entire runnable instance, however this doc is about understanding the structure and workflow so builders can really feel comfy freezing of their use case.
Agent Structure
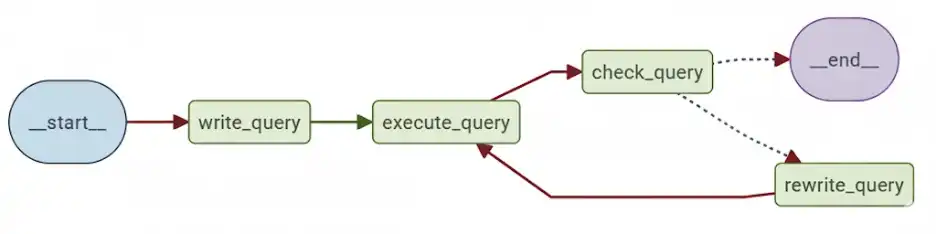
Agent-Lightning works seamlessly with frameworks like AutoGen, CrewAI, LangGraph, OpenAI Brokers SDK, and different customized Python logic. On this instance, the LangGraph defines a cyclic workflow that fashions how an information analyst iteratively writes and fixes SQL queries:
There are 4 levels of perform:
- write_query: Takes the person’s query, generates an preliminary SQL question from the textual content query.
- execute_query: Executes the generated question within the goal database.
- check_query: Makes use of a validation immediate (CHECK_QUERY_PROMPT) to validate the consequence.
- rewrite_query: If there are issues, rewrite the question.
The loop continues till both the question validates or a max iteration depend (max_turns) is reached. Reinforcement studying optimizes the write_query and rewrite_query levels.
Constructing the LangGraph Agent
For maintaining the code modular and maintainable, outline your LangGraph logic with a builder perform individually, as proven:
from langgraph import StateGraph
def build_langgraph_sql_agent(
database_path: str,
openai_base_url: str,
mannequin: str,
sampling_parameters: dict,
max_turns: int,
truncate_length: int
):
# Step 1: Outline the LangGraph workflow
builder = StateGraph()
# Step 2: Add agent nodes for every step
builder.add_node("write_query")
builder.add_node("execute_query")
builder.add_node("check_query")
builder.add_node("rewrite_query")
# Step 3: Join the workflow edges
builder.add_edge("__start__", "write_query")
builder.add_edge("write_query", "execute_query")
builder.add_edge("execute_query", "check_query")
builder.add_edge("check_query", "rewrite_query")
builder.add_edge("rewrite_query", "__end__")
# Step 4: Compile the graph
return builder.compile().graph()Doing so will separate your LangGraph logic from potential future updates to Agent-Lightning, thus selling readability and maintainability.
Bridging LangGraph and Agent-Lightning
The LitSQLAgent class serves as a conduit between LangGraph and Agent-Lightning. It extends agl.LitAgent, so the Runner can handle shared sources (like LLMs) for every rollout.
import agentlightning as agl
class LitSQLAgent(agl.LitAgent[dict]):
def __init__(self, max_turns: int, truncate_length: int):
tremendous().__init__()
self.max_turns = max_turns
self.truncate_length = truncate_length
def rollout(self, process: dict, sources: agl.NamedResources, rollout: agl.Rollout) -> float:
# Step 1: Load shared LLM useful resource
llm: agl.LLM = sources["main_llm"]
# Step 2: Construct LangGraph agent dynamically
agent = build_langgraph_sql_agent(
database_path="sqlite:///" + process["db_id"],
openai_base_url=llm.get_base_url(rollout.rollout_id, rollout.try.attempt_id),
mannequin=llm.mannequin,
sampling_parameters=llm.sampling_parameters,
max_turns=self.max_turns,
truncate_length=self.truncate_length,
)
# Step 3: Invoke agent
consequence = agent.invoke({"query": process["question"]}, {
"callbacks": [self.tracer.get_langchain_handler()],
"recursion_limit": 100,
})
# Step 4: Consider question to generate reward
reward = evaluate_query(
consequence["query"], process["ground_truth"], process["db_path"], raise_on_error=False
)
return rewardNotice: The “main_llm” useful resource secret is a cooperative conference that exists between the agent and VERL, to offer entry to the right endpoint for each rollout, within the context of the service.
Reward Sign and Analysis
The evaluate_query perform will outline your reward mechanism for RL coaching. Every process on the Spider dataset incorporates a pure language query, a database schema, and a ground-truth SQL question. The reward mechanism compares the SQL question that the mannequin produced towards the reference SQL question:
def evaluate_query(predicted_query, ground_truth_query, db_path, raise_on_error=False):
result_pred = run_sql(predicted_query, db_path)
result_true = run_sql(ground_truth_query, db_path)
return 1.0 if result_pred == result_true else 0.0Notice: The agent must not ever see ground-truth queries throughout coaching, in any other case this can leak info.
Configuring VERL for Reinforcement Studying
VERL is the agent’s RL backend. The configuration is outlined identical to a Python dictionary can be, the place you enter the algorithm, fashions, rollout parameters, and coaching choices. Right here is an easy configuration:
verl_config = {
"algorithm": {"adv_estimator": "grpo", "use_kl_in_reward": False},
"information": {
"train_batch_size": 32,
"max_prompt_length": 4096,
"max_response_length": 2048,
},
"actor_rollout_ref": {
"rollout": {"title": "vllm", "n": 4, "multi_turn": {"format": "hermes"}},
"actor": {"ppo_mini_batch_size": 32, "optim": {"lr": 1e-6}},
"mannequin": {"path": "Qwen/Qwen2.5-Coder-1.5B-Instruct"},
},
"coach": {
"n_gpus_per_node": 1,
"val_before_train": True,
"test_freq": 32,
"save_freq": 64,
"total_epochs": 2,
},
}That is analogous to the command you could possibly have run within the CLI:
python3 -m verl.coach.main_ppo
algorithm.adv_estimator=grpo
information.train_batch_size=32
actor_rollout_ref.mannequin.path=Qwen/Qwen2.5-Coder-1.5B-InstructOrchestrating Coaching with Coach
The Coach is the high-level coordinator who connects each half agent, RL algorithm, dataset, and distributed runners.
import pandas as pd
import agentlightning as agl
# Step 1: Initialize agent and algorithm
agent = LitSQLAgent(max_turns=3, truncate_length=1024)
algorithm = agl.VERL(verl_config)
# Step 2: Initialize Coach
coach = agl.Coach(
n_runners=10,
algorithm=algorithm,
adapter=rewrite" # Optimize each question levels
)
# Step 3: Load dataset
train_data = pd.read_parquet("information/train_spider.parquet").to_dict("data")
val_data = pd.read_parquet("information/test_dev_500.parquet").to_dict("data")
# Step 4: Practice
coach.match(agent, train_dataset=train_data, val_dataset=val_data)That is what is occurring behind the sences:
- VERL launches an OpenAI-compatible proxy, so work might be distributed with out implementing OpenAI’s request.
- The Coach creates 10 runners to execute concurrently.
- Every runner calls the
rolloutmethodology, collects traces and sends rewards again to replace the coverage.
Debugging the Agent with coach.dev()
Earlier than beginning full RL coaching, it is suggested to dry-run the total pipeline with a view to examine connections and traces.
coach = agl.Coach(
n_workers=1,
initial_resources={
"main_llm": agl.LLM(
endpoint=os.environ["OPENAI_API_BASE"],
mannequin="gpt-4.1-nano",
sampling_parameters={"temperature": 0.7},
)
},
)
# Load a small subset for dry-run
import pandas as pd
dev_data = pd.read_parquet("information/test_dev_500.parquet").to_dict("data")[:10]
# Run dry-run mode
coach.dev(agent, dev_dataset=dev_data)This confirms your entire LangGraph management move, database connections, and logic of the reward earlier than you progress to coaching on lengthy GPU hours.
Working the Full Instance
To arrange the atmosphere, set up dependencies (i.e; utilizing pip set up -r necessities.txt), and run the total coaching script:
# Step 1: Set up dependencies
pip set up "agentlightning[verl]" langchain pandas gdown
# Step 2: Obtain Spider dataset
cd examples/spider
gdown --fuzzy https://drive.google.com/file/d/1oi9J1jZP9TyM35L85CL3qeGWl2jqlnL6/view
unzip -q spider-data.zip -d information && rm spider-data.zip
# Step 3: Launch coaching
python train_sql_agent.py qwen # Qwen-2.5-Coder-1.5B
# or
python train_sql_agent.py llama # LLaMA 3.2 1BIn case you are utilizing fashions hosted on hugging face, remember to export your token:
export HF_TOKEN="your_huggingface_token" Debugging With out VERL
If you wish to validate the agent logic with out reinforcement studying, you need to use the built-in debug helper:
export OPENAI_API_BASE="https://api.openai.com/v1"
export OPENAI_API_KEY="your_api_key_here"
cd examples/spider
python sql_agent.pyIt will assist you to run the SQL agent along with your present LLM endpoint to substantiate the question was executed and the management move labored as you anticipate.
Analysis Outcomes
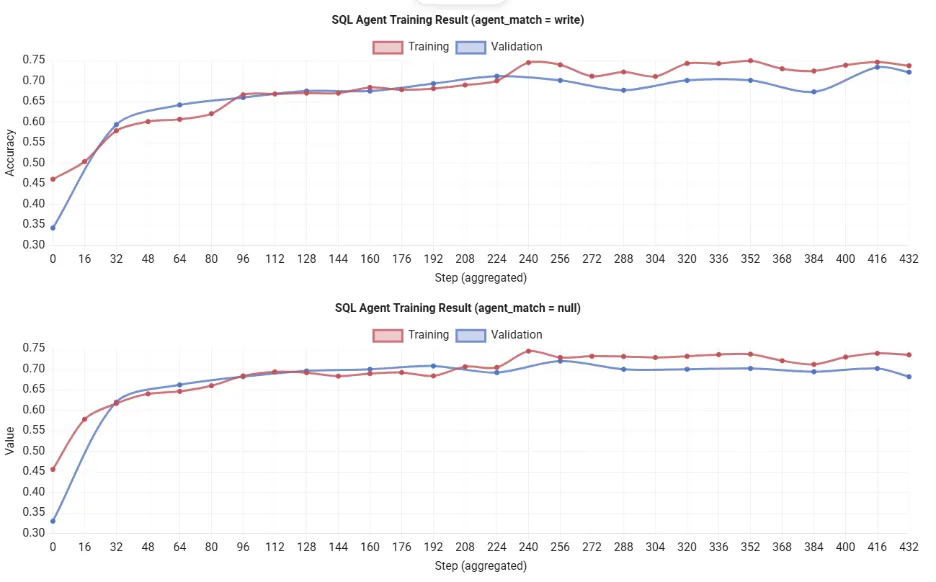
Notice: Working python train_sql_agent.py qwen on a single 80 GB GPU normally finishes after ~12 hours. You’ll see the rewards of coaching enhance persistently, indicating that the agent is bettering its SQL technology course of over time. Due to this fact, as a result of useful resource constraints, I’ve used the outcomes proven over the official documentation.
When and The place to Use Agent Lightning
In sensible conditions, let’s say you might have an LLM-based agent that performs an essential position in an utility (buyer assist chatbot, automated coding assistant, and so on.) and you plan to why you’d refine it, Agent Lightning is a robust candidate. The framework has already been proven to work in different duties, resembling SQL question technology. In these and different related conditions, Agent Lightning took an agent that already existed and additional optimized them by means of RL or immediate optimization, leading to extra correct solutions.
- In order for you an AI agent to study by means of trial-and-error, you need to use Agent Lightning. It’s designed for multi-step logical conditions with clear alerts that decide success or failure.
- As an illustration, Agent Lightning can enhance a bot that generates database queries by utilizing the noticed suggestions from execution to study. The educational mannequin can also be helpful for chatbots, digital assistants, game-playing brokers, and general-purpose brokers using instruments or APIs.
- The Agent Lightning framework is agent-agnostic. It runs as wanted on a typical PC or server, so that you practice fashions by yourself laptop computer or on the cloud when vital.
Conclusion
Microsoft Agent Lightning is a powerful new mechanism for bettering the smartness of AI brokers. Relatively than pondering of an agent as a set object or piece of code, Agent Lightning permits a coaching loop so your agent can study from expertise. By decoupling coaching from execution, it may possibly optimize any agent workflow with none code modifications.
What this implies is, you’ll be able to simply improve an agent workflow, whether or not it’s a customized agent, a LangChain bot, CrewAI, LangGraph, AutoGen or a extra particular OpenAI SDK agent, by toggling reinforcement studying Mechanism with Agent Lightning. In apply, you might be enabling your agent(s) to get smarter from their very own information.
Often Requested Questions
A. It’s an open-source framework from Microsoft that trains AI brokers utilizing reinforcement studying with out altering their core logic or workflows.
A. It lets brokers study from actual process suggestions utilizing reinforcement studying, constantly refining prompts or mannequin weights for higher efficiency.
A. Sure, it integrates simply with LangChain, AutoGen, CrewAI, LangGraph, and customized Python brokers with minimal code modifications.
Good day! I am Vipin, a passionate information science and machine studying fanatic with a robust basis in information evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy information, and fixing real-world issues. My objective is to use data-driven insights to create sensible options that drive outcomes. I am wanting to contribute my abilities in a collaborative atmosphere whereas persevering with to study and develop within the fields of Information Science, Machine Studying, and NLP.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}