
The Rising Want for Scalable Reasoning Fashions in Machine Intelligence
Superior reasoning fashions are on the frontier of machine intelligence, particularly in domains like math problem-solving and symbolic reasoning. These fashions are designed to carry out multi-step calculations and logical deductions, typically producing options that mirror human reasoning processes. Reinforcement studying methods are used to enhance accuracy after pretraining; nevertheless, scaling these strategies whereas retaining effectivity stays a fancy problem. As demand will increase for smaller, extra resource-efficient fashions that also exhibit excessive reasoning functionality, researchers at the moment are turning to methods that handle knowledge high quality, exploration strategies, and long-context generalization.
Challenges in Reinforcement Studying for Giant Reasoning Architectures
A persistent downside with reinforcement studying for large-scale reasoning fashions is the mismatch between the mannequin’s functionality and the problem of the coaching knowledge. When a mannequin is uncovered to duties which are too easy, its studying curve stagnates. Conversely, overly troublesome knowledge can overwhelm the mannequin and yield no studying sign. This problem imbalance is very pronounced when making use of recipes that work effectively for small fashions to bigger ones. One other concern is the dearth of strategies to effectively adapt rollout range and output size throughout each coaching and inference, which additional constrains a mannequin’s reasoning talents on advanced benchmarks.
Limitations of Current Put up-Coaching Approaches on Superior Fashions
Earlier approaches, comparable to DeepScaleR and GRPO, have demonstrated that reinforcement studying can enhance the efficiency of small-scale reasoning fashions with as few as 1.5 billion parameters. Nevertheless, making use of these similar recipes to extra succesful fashions, comparable to Qwen3-4B or Deepseek-R1-Distill-Qwen-7B, ends in solely marginal positive factors and even efficiency drops. One key limitation is the static nature of information distribution and the restricted range of sampling. Most of those approaches don’t filter knowledge based mostly on mannequin functionality, nor do they modify sampling temperature or response size over time. Consequently, they typically fail to scale successfully when used on extra superior architectures.
Introducing Polaris: A Tailor-made Recipe for Scalable RL in Reasoning Duties
Researchers from the College of Hong Kong, Bytedance Seed, and Fudan College launched Polaris, a post-training recipe designed particularly to scale reinforcement studying for superior reasoning duties. Polaris consists of two preview fashions: Polaris-4B-Preview and Polaris-7B-Preview. Polaris-4B-Preview is fine-tuned from Qwen3-4B, whereas Polaris-7B-Preview relies on Deepseek-R1-Distill-Qwen-7B. The researchers targeted on constructing a model-agnostic framework that modifies knowledge problem, encourages various exploration via managed sampling temperatures, and extends inference capabilities via size extrapolation. These methods had been developed utilizing open-source datasets and coaching pipelines, and each fashions are optimized to run on consumer-grade graphics processing models (GPUs).
Polaris Improvements: Problem Balancing, Managed Sampling, and Lengthy-Context Inference
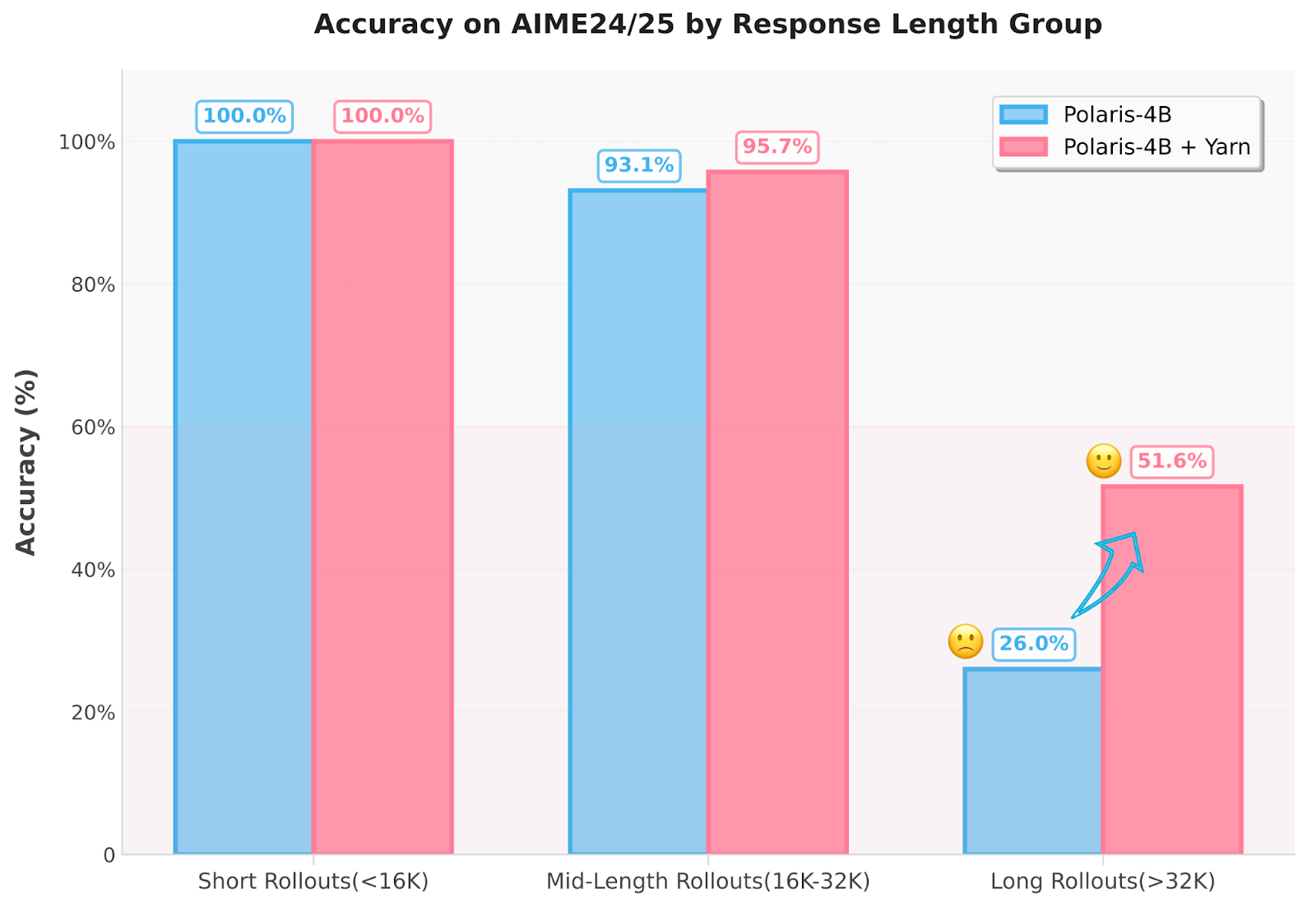
Polaris implements a number of improvements. First, the coaching knowledge is curated by eradicating issues which are both too simple or unsolvable, making a mirrored J-shape distribution of problem. This ensures that the coaching knowledge evolves with the mannequin’s rising capabilities. Second, the researchers dynamically modify the sampling temperature throughout coaching levels—utilizing 1.4, 1.45, and 1.5 for Polaris-4B and 0.7, 1.0, and 1.1 for Polaris-7B—to take care of rollout range. Moreover, the tactic employs a Yarn-based extrapolation approach to increase the inference context size to 96K tokens with out requiring further coaching. This addresses the inefficiency of long-sequence coaching by enabling a “train-short, test-long” method. The mannequin additionally employs methods such because the Rollout Rescue Mechanism and Intra-Batch Informative Substitution to stop zero-reward batches and be certain that helpful coaching indicators are preserved, even when the rollout measurement is saved small at 8.
Benchmark Outcomes: Polaris Outperforms Bigger Business Fashions
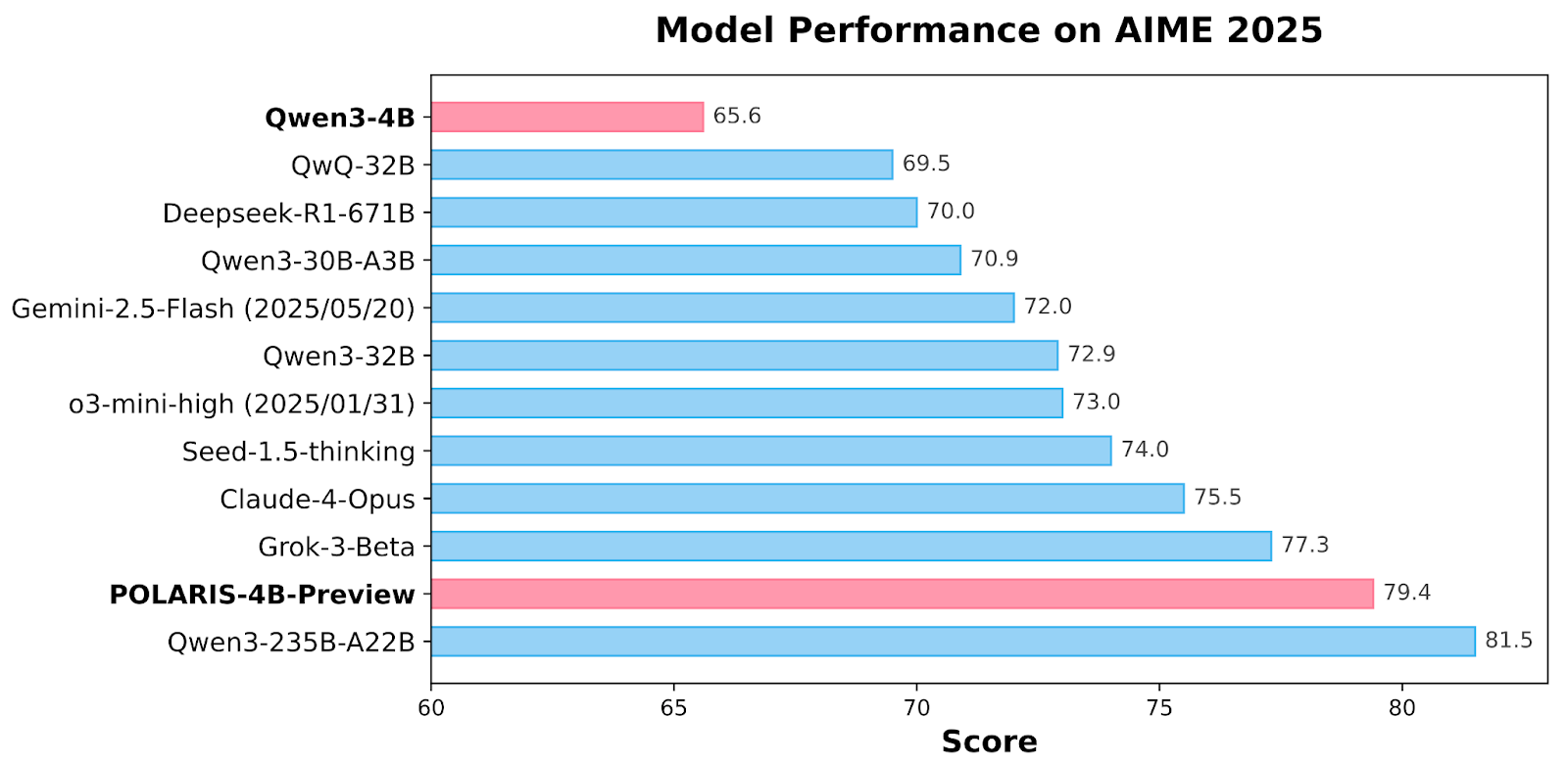
Polaris fashions obtain state-of-the-art outcomes throughout a number of math benchmarks. Polaris-4B-Preview data 81.2% accuracy on AIME24 and 79.4% on AIME25, outperforming even Qwen3-32B on the identical duties whereas utilizing lower than 2% of its parameters. It scores 44.0% on Minerva Math, 69.1% on Olympiad Bench, and 94.8% on AMC23. Polaris-7B-Preview additionally performs strongly, scoring 72.6% on AIME24 and 52.6% on AIME25. These outcomes show constant enchancment over fashions comparable to Claude-4-Opus and Grok-3-Beta, establishing Polaris as a aggressive, light-weight mannequin that bridges the efficiency hole between small open fashions and business 30B+ fashions.
Conclusion: Environment friendly Reinforcement Studying By Good Put up-Coaching Methods
The researchers demonstrated that the important thing to scaling reasoning fashions isn’t just bigger mannequin measurement however clever management over coaching knowledge problem, sampling range, and inference size. Polaris affords a reproducible recipe that successfully tunes these parts, permitting smaller fashions to rival the reasoning skill of huge business methods.
Try the Mannequin and Code. All credit score for this analysis goes to the researchers of this venture. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


{kind=link}