
Fashionable streaming workloads are extremely dynamic—visitors volumes fluctuate based mostly on time of day, enterprise cycles, or event-driven bursts. Prospects must dynamically scale Apache Kafka clusters up and down to keep up constant throughput and efficiency with out incurring pointless price. For instance, ecommerce platforms see sharp visitors will increase throughout seasonal gross sales, and monetary methods expertise load spikes throughout market hours. Scaling clusters helps groups align cluster capability with elevated ingress throughput in response to those variations, resulting in extra environment friendly utilization and a greater cost-to-performance ratio.
Amazon Managed Streaming for Apache Kafka (Amazon MSK) Specific brokers are a key part to dynamically scaling clusters to fulfill demand. Specific based mostly clusters ship 3 occasions increased throughput, 20 occasions sooner scaling capabilities, and 90% sooner dealer restoration in comparison with Amazon MSK Provisioned clusters. As well as, Specific brokers assist clever rebalancing for 180 occasions sooner operation efficiency, so partitions are mechanically and constantly nicely distributed throughout brokers. This characteristic is enabled by default for all new Specific based mostly clusters and comes at no further price to prospects. This functionality alleviates the necessity for handbook partition administration when modifying cluster capability. Clever rebalancing mechanically tracks cluster well being and triggers partition redistribution when useful resource imbalances are detected, sustaining efficiency throughout brokers.
This publish demonstrates use the clever rebalancing characteristic and construct a customized answer that scales Specific based mostly clusters horizontally (including and eradicating brokers) dynamically based mostly on Amazon CloudWatch metrics and predefined schedules. The answer gives capability administration whereas sustaining cluster efficiency and minimizing overhead.
Overview of Kafka scaling
Scaling Kafka clusters includes including or eradicating brokers to the cluster whereas offering balanced information distribution and uninterrupted service. When new brokers are added, partition reassignment is required to evenly distribute load throughout the cluster. This course of is usually carried out manually—both by way of the Kafka command line instruments (kafka-reassign-partitions.sh) or through the use of automation frameworks similar to Cruise Management, which intelligently calculates and executes reassignment plans. Throughout scale-in operations, partitions hosted on the brokers marked for elimination should first be migrated to different brokers, leaving the goal brokers empty earlier than decommissioning.
Challenges of scaling Kafka dynamically
The complexity of scaling relies upon closely on the underlying storage mannequin. In deployments the place dealer information resides totally on native storage, scaling includes bodily information motion between brokers, which may take appreciable time relying on partition measurement and replication issue. In distinction, environments that use tiered storage shift many of the information to distant object storage similar to Amazon Easy Storage Service (Amazon S3), making scaling a largely metadata-driven operation. This considerably reduces information switch overhead and accelerates each dealer addition and elimination, enabling extra elastic and operationally environment friendly Kafka clusters.
Nevertheless, scaling Kafka stays a non-trivial operation as a result of interaction between storage, information motion, and dealer useful resource utilization. When partitions are reassigned throughout brokers, giant volumes of information have to be copied over the community, usually resulting in community bandwidth saturation, storage bandwidth exhaustion, and elevated CPU utilization. Relying on information quantity and replication issue, partition rebalancing can take a number of hours, throughout which period cluster efficiency and throughput may briefly degrade and infrequently require further configuration to throttle the information motion. Though instruments like Cruise Management automate this course of, they introduce one other layer of complexity: choosing the best mixture of rebalancing targets (similar to disk capability, community load, or duplicate distribution) requires a deep understanding of Kafka internals and trade-offs between pace, stability, and stability. Because of this, environment friendly scaling is an optimization downside, demanding cautious orchestration of storage, compute, and community assets.
How Specific brokers simplify scaling
Specific brokers handle Kafka scaling by way of their decoupled compute and storage structure. This revolutionary design allows limitless storage with out pre-provisioning, considerably simplifying cluster sizing and administration. The separation of compute and storage assets permits Specific brokers to scale sooner than customary MSK brokers, enabling fast cluster enlargement inside minutes. With Specific brokers, directors can alter capability each vertically and horizontally as wanted, assuaging the necessity for over-provisioning. The structure gives sustained dealer throughput throughout scaling operations, with Specific brokers able to dealing with 500 MBps ingress and 1000 MBps egress on m7g.16xl cases. For extra details about how the scaling course of works in Specific based mostly clusters, see Specific brokers for Amazon MSK: Turbo-charged Kafka scaling with as much as 20 occasions sooner efficiency.
Added to this sooner scaling functionality, if you add or take away brokers out of your Specific based mostly clusters, clever rebalancing mechanically redistributes partitions to stability useful resource utilization throughout the brokers. This makes positive the cluster continues to function at peak efficiency, making scaling out and in doable with a single replace operation. Clever rebalancing is enabled by default on new Specific dealer clusters and constantly displays cluster well being for useful resource imbalances or hotspots. For instance, if sure brokers change into overloaded resulting from uneven distribution of partitions or skewed visitors patterns, clever rebalancing will mechanically transfer partitions to much less utilized brokers to revive stability.
Lastly, Specific based mostly clusters automate shopper configuration of dealer bootstrap connection strings to permit shoppers to hook up with clusters seamlessly as brokers are added and eliminated. Specific based mostly clusters present three connection strings, one per Availability Zone, that are unbiased of the brokers within the cluster. This implies shoppers solely must configure these connection strings to keep up constant connections as brokers are added or eliminated. These key capabilities of Specific based mostly clusters—fast scaling, clever rebalancing, and dynamic dealer bootstrapping—are vital to enabling dynamic scaling in Kafka clusters. Within the following part, we discover how we use these capabilities to automate the scaling technique of Specific based mostly clusters.
On-demand and scheduled scaling
Leveraging quick scaling capabilities of Specific brokers along with clever rebalancing, you may construct a versatile and dynamic scaling answer to optimize your Kafka cluster assets. There are two main approaches for automated scaling that stability efficiency wants with price effectivity: on-demand and scheduled scaling.
On-demand scaling
On-demand scaling tracks cluster efficiency and responds to capability calls for. This method addresses eventualities the place workload patterns expertise visitors spikes. On-demand scaling tracks Amazon MSK efficiency indicators as CPU utilization and community ingress and egress throughput per dealer. Past these infrastructure metrics, the answer additionally helps utilizing CloudWatch metrics to allow business-logic-driven scaling choices.
The answer evaluates the efficiency metrics constantly in opposition to configurable thresholds to find out when scaling actions are essential. When brokers function above capability thresholds constantly over a time frame, it invokes an Amazon MSK API to extend the dealer rely of the cluster. The answer on this publish at present helps horizontal scaling (including and eradicating brokers) solely. Clever rebalancing will then mechanically redistribute the partitions to unfold the load throughout the brand new brokers which are added. Equally, when utilization drops under thresholds, the answer invokes an Amazon MSK API to take away brokers. The rebalancing course of mechanically strikes partitions from the dealer marked for elimination to different brokers within the cluster. This answer requires subjects to have enough partitions to assist rebalancing to new brokers as brokers are added.
The next diagram illustrates the on-demand scaling workflow.

Scheduled scaling
Scheduled scaling adjusts cluster capability utilizing time-based triggers. This method is helpful for purposes with visitors patterns that correlate with enterprise hours or schedules. For instance, ecommerce platforms profit from scheduled scaling throughout peak sale durations when buyer exercise peaks. Scheduled scaling can also be helpful for purchasers who wish to keep away from cluster modification operations throughout enterprise hours. This answer makes use of a configurable schedule to scale out the cluster capability earlier than enterprise hours to deal with the anticipated visitors and scale in after enterprise hours to cut back prices. This explicit answer at present helps horizontal scaling (including/eradicating brokers) solely. With scheduled scaling, you may deal with particular eventualities similar to weekday enterprise hours, weekend upkeep home windows, or particular dates. You may also specify the specified variety of brokers at scale-out and scale-in.
The next diagram illustrates the scheduled scaling workflow.

Resolution overview
This answer gives scaling automation for Specific brokers by way of two approaches:
- On-demand scaling – Tracks built-in cluster efficiency metrics or customized CloudWatch metrics and adjusts dealer capability when thresholds are crossed
- Scheduled scaling – Scales clusters based mostly on particular schedules
Within the following sections, we offer the implementation particulars for each scaling strategies.
Stipulations
Full the next steps as stipulations:
- Create an Specific cluster with clever rebalancing enabled. The clever rebalancing characteristic is required for this answer to work. Notice the Amazon Useful resource Title (ARN) of the cluster.
- Set up Python 3.11 or increased on Amazon Elastic Compute Cloud (Amazon EC2).
- Set up the AWS Command Line Interface (AWS CLI) and configure it along with your AWS credentials.
- Set up the AWS CDK CLI.
On-demand scaling answer
The answer makes use of an AWS Lambda perform that’s triggered by an Amazon EventBridge scheduler periodically. The Lambda perform checks the cluster state and time for the reason that final dealer addition or elimination was executed. That is executed to find out if the cluster is able to scale. If the cluster is prepared for scaling, the perform collects the CloudWatch metrics that have to be evaluated to make the scaling choice. Primarily based on the scaling configuration and utilizing the metrics in CloudWatch, the perform evaluates the scaling logic and executes the scaling choice. The scaling choice can result in addition or elimination of brokers to the cluster. In each instances, clever rebalancing handles partition distribution throughout brokers with out handbook intervention. Yow will discover extra particulars of the scaling logic within the GitHub repo.
The next diagram illustrates the structure of the on-demand scaling answer.
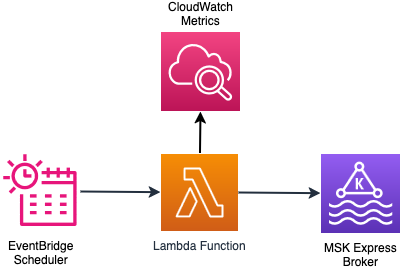
Deploy on-demand scaling answer
Comply with these steps to deploy the on-demand scaling infrastructure. For this publish, we exhibit the on-demand scale-out performance.
- Run the next instructions to set the challenge up:
- Modify the thresholds to match your MSK dealer occasion measurement and enterprise necessities by enhancing
src/config/on_demand_scaling_config.json. Consult with the configuration documentation for extra particulars of the configuration choices accessible.
By default,on_demand_scaling_config.jsonconsiders the categorical.m7g.giant dealer occasion measurement. Subsequently the scale-in/scale-out ingress/egress thresholds are configured at 70% of the really useful sustained throughput for the occasion measurement. - Bootstrap your setting to be used with the AWS CDK.
- Deploy the on-demand scaling AWS CDK utility:
The monitoring_frequency_minutes parameter controls how usually the EventBridge scheduler invokes the scaling logic Lambda perform to guage cluster metrics.
The deployment creates the AWS assets required to run the on-demand scaling answer. The small print of the assets created are proven within the output of the command.
Check and monitor the on-demand scaling answer
Configure the bootstrap server to your MSK cluster. You may get the bootstrap server from the AWS Administration console or utilizing the AWS CLI.
Create a Kafka matter within the cluster. Replace the next command for the particular authentication technique in Amazon MSK. Consult with the Amazon MSK Labs workshop for extra particulars.
Matters ought to have a enough variety of partitions that may be distributed throughout a bigger set of brokers.
Generate load on the MSK cluster to set off and confirm the scaling operations. You should use an current utility that drives load to your cluster. You may also use the kafka-producer-perf-test.sh utility that’s bundled as a part of the Kafka distribution to generate load:
Monitor the scaling operations by tailing the Lambda perform logs:
Within the logs, search for the next messages to determine the precise occasions when scaling operations occurred. The log statements above these messages present the rationale behind the scaling choice:
The answer additionally creates a CloudWatch dashboard that gives visibility into scaling operations and lots of different dealer metrics. The hyperlink to the dashboard is proven within the output of the cdk deploy command.
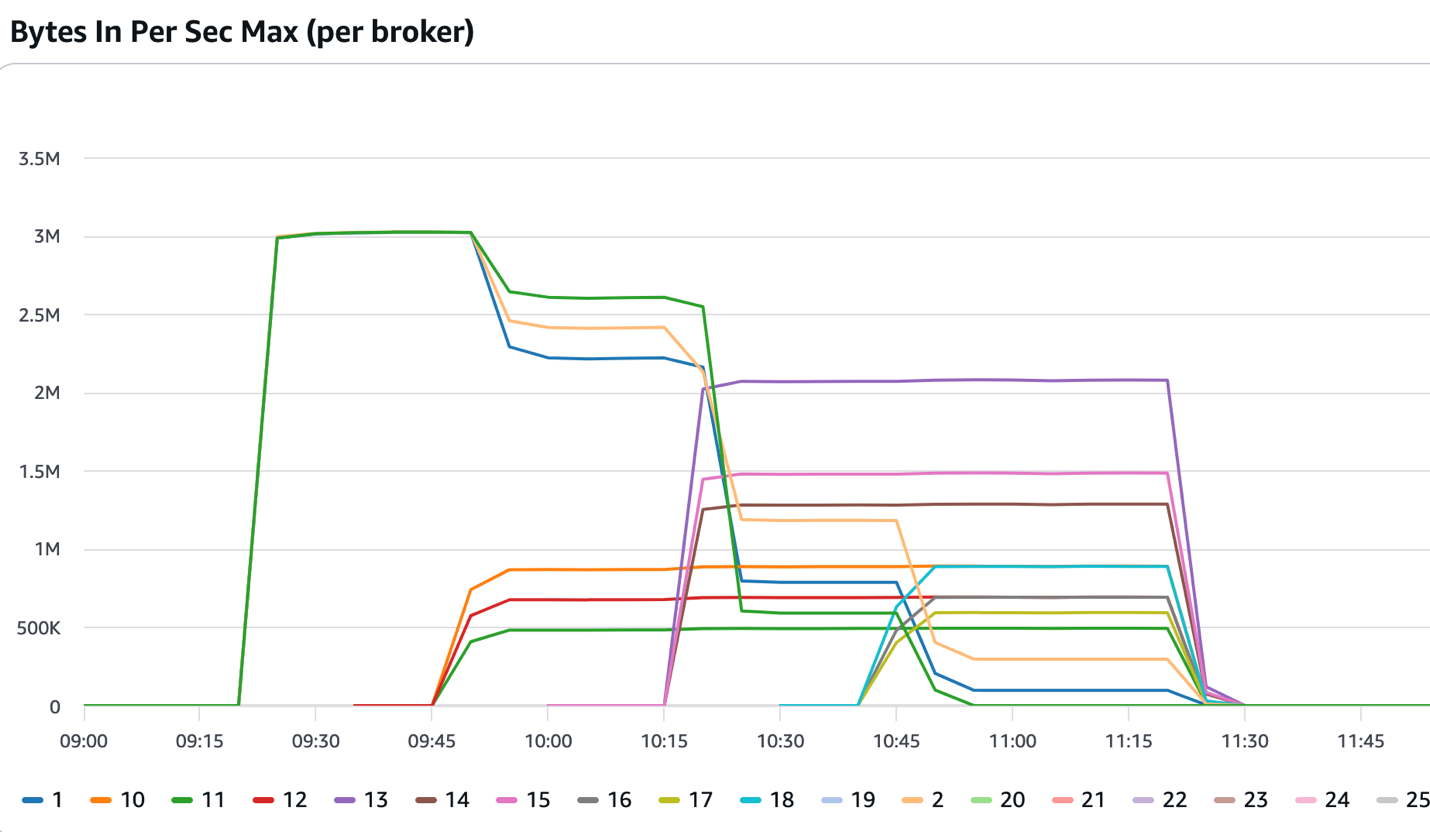
The next determine reveals a cluster that began with three brokers. After the 09:15 mark, it acquired constant inbound visitors, which exceeded the thresholds set within the answer. The answer added three extra brokers that got here into service at across the 09:45 mark. Clever rebalancing reassigned a few of the partitions to the newly added brokers and the incoming visitors was break up throughout six brokers. The answer continued including extra brokers till the cluster had 12 brokers and the clever rebalancing characteristic continued distributing the partitions throughout the newly added brokers.
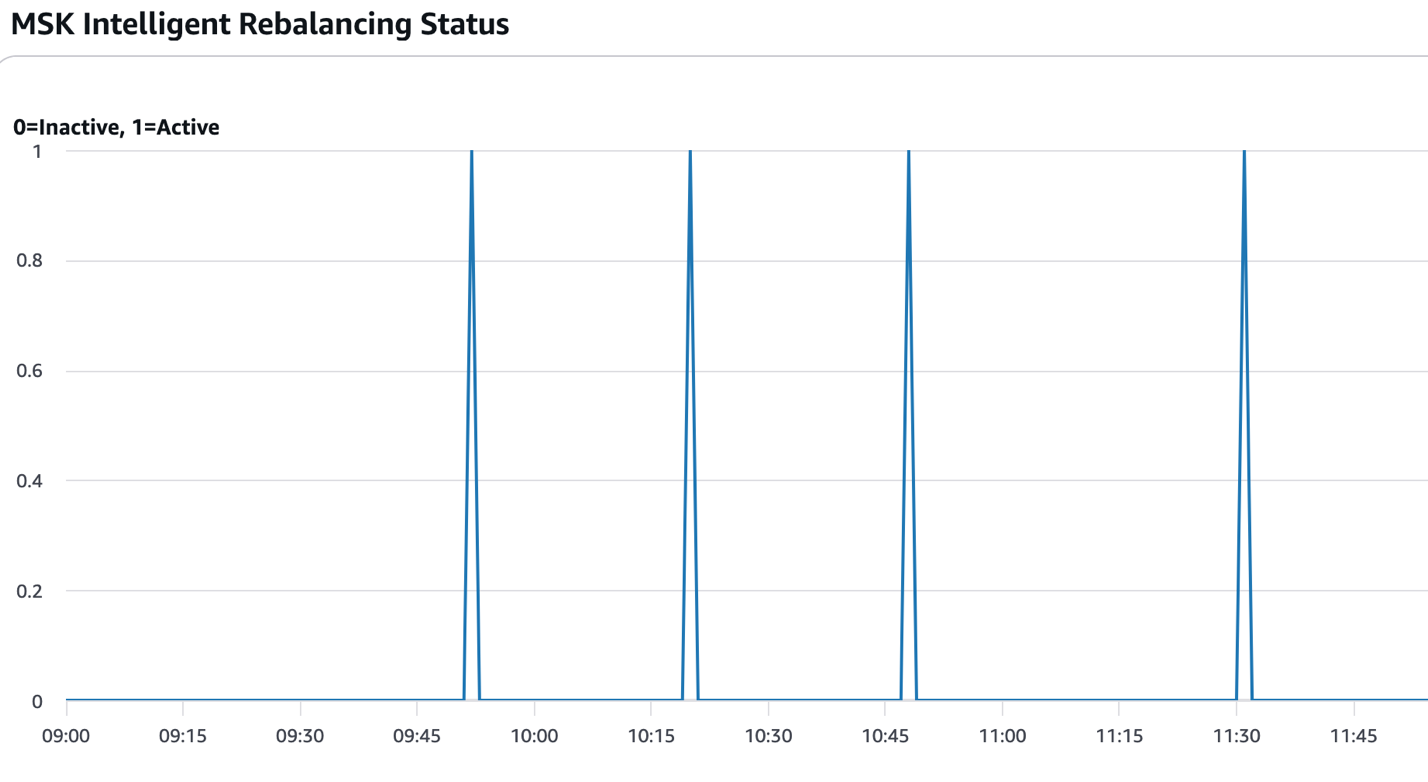
The next determine reveals the occasions when partition rebalancing was energetic (worth=1). Within the context of this answer, that sometimes happens after new brokers are added or eliminated and the scaling operations are full.
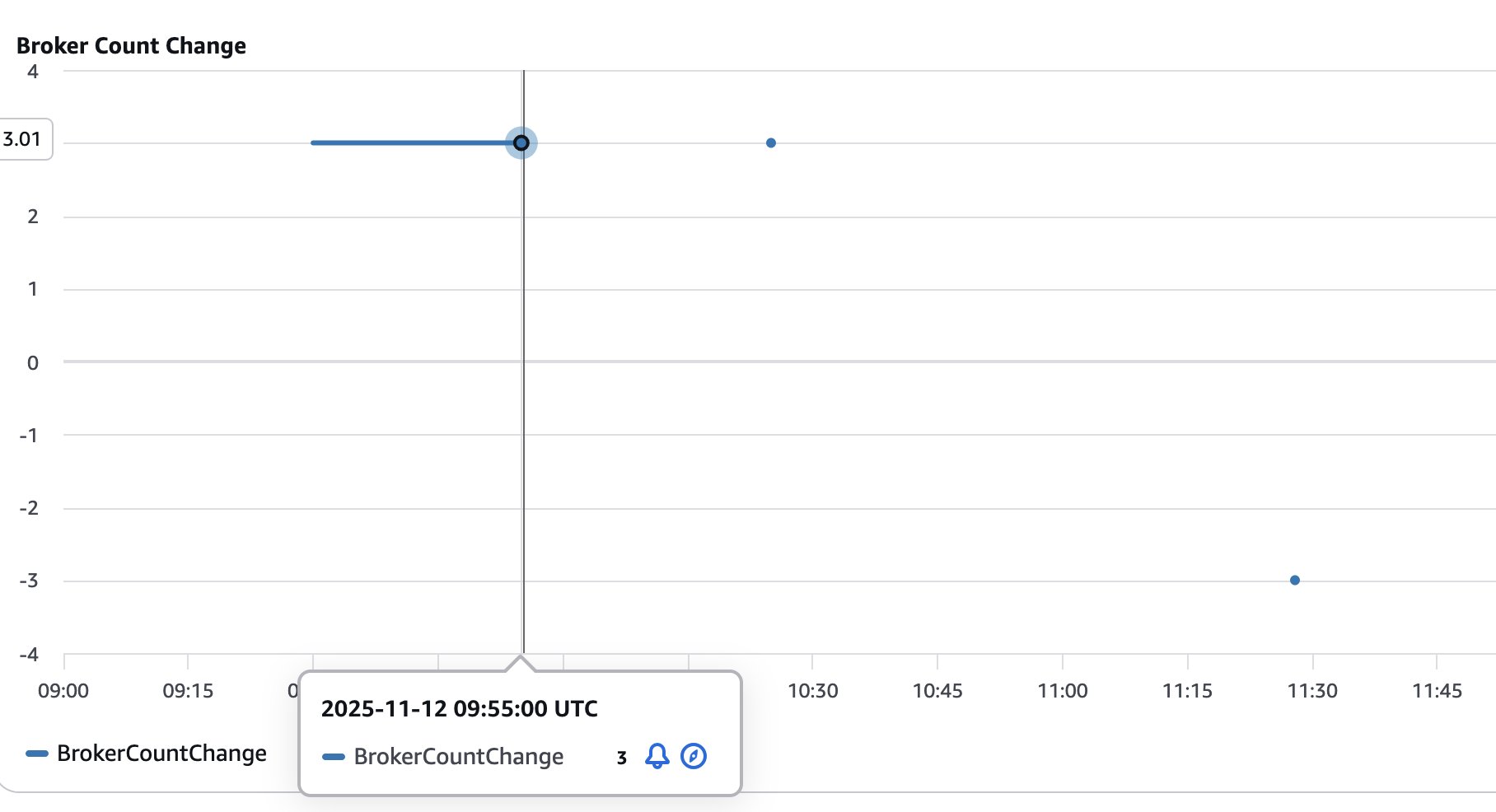
The next determine reveals the variety of brokers added (optimistic values) or eliminated (detrimental values) from the cluster. This helps visualize and monitor the scale of the cluster because it goes by way of scaling operations.
Scheduled scaling answer
The scheduled scaling implementation helps timing patterns by way of an EventBridge schedule. You possibly can configure timing to set off an motion utilizing cron expressions. Primarily based on the cron expression, the EventBridge Scheduler triggers a Lambda perform on the specified time to scale out or scale in. The Lambda perform performs checks if the cluster is prepared for a scaling operation and performs the requested scaling operation by invoking the Amazon MSK management airplane API. The service permits eradicating solely three brokers at a time from a cluster. The answer handles this state of affairs by repeatedly eradicating the brokers in counts of three till the specified variety of brokers are reached.
The next diagram illustrates the structure of the scheduled scaling answer.
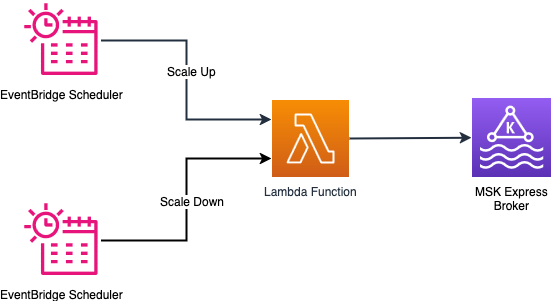
Configuration parameters
EventBridge schedules assist cron expressions for exact timing management, so you may fine-tune scaling operations for particular occasions of day and days of the week. For instance, you may configure scaling to happen at 8:00 AM on weekdays utilizing the cron expression cron(0 8 ? * MON-FRI *). To scale in at 6:00 PM on the identical days, use cron(0 18 ? * MON-FRI *). For extra patterns, consult with Setting a schedule sample for scheduled guidelines (legacy) in Amazon EventBridge. You may also configure the specified dealer rely to be reached throughout scale-out and scale-in operations.
Deploy scheduled scaling answer
Comply with these steps to deploy the scheduled scaling answer:
- Run the next instructions to set the challenge up:
- Modify the scaling schedule by enhancing
scaling/cdk/src/config/scheduled_scaling_config.json. Consult with the configuration documentation for extra particulars of the configuration choices accessible. - Deploy the scheduled scaling AWS CDK utility:
Check and monitor the scheduled scaling answer
The scheduled scaling is triggered as specified within the EventBridge Scheduler cron. Nevertheless, if you wish to check the scale-out operations, run the next command to manually invoke the Lambda perform:
Equally, you may manually begin a scale-in operation by operating the next command:
Monitor the scaling operations by tailing the Lambda perform logs:
You possibly can monitor scheduled scaling utilizing the CloudWatch dashboard as described within the on-demand scaling part.
Evaluation scaling configuration parameters
The configuration parameters for each on-demand and scheduled scaling are documented in Configuration Choices. These configurations offer you flexibility to vary how and when the scaling occurs. It is very important undergo the configuration parameters and ensure they meet your online business requirement. For on-demand scaling, you may scale the cluster based mostly on built-in efficiency metrics or customized metrics (for instance MessagesInPerSec).
Concerns
Be mindful the next concerns when deploying both answer:
- EventBridge notifications for scaling failures – Each on-demand and scheduled scaling options publish EventBridge notifications when scaling operations fail. Create EventBridge guidelines to route these failure occasions to your monitoring and alerting system to detect failures in scaling and reply to them. For particulars on occasion sources, sorts, and payloads, consult with the EventBridge notifications part within the GitHub repo.
- Cool-down interval administration – Correctly configure cool-down durations to stop scaling oscillations the place the cluster repeatedly scales out and scales in quickly. Oscillations sometimes happen when visitors patterns have short-term spikes that don’t characterize sustained demand. Oscillations can even occur when thresholds are set too near regular working ranges. Set cool-down durations based mostly in your workload traits and the scaling completion occasions. Additionally think about totally different cool-down durations for scale-out vs. scale-in operations by setting longer cool-down durations for scale-in operations (
scale_in_cooldown_minutes) in comparison with scaling out (scale_out_cooldown_minutes). Check cool-down settings beneath life like load patterns earlier than manufacturing deployment to realize optimum efficiency. - Value management by way of monitoring frequency – The answer incurs prices for providers like Lambda features, EventBridge schedules, CloudWatch metrics, and logs which are used within the answer. Each on-demand and scheduled scaling options work by operating periodically to verify the cluster well being standing and if a scaling operation must be carried out. The default 1-minute monitoring frequency gives responsive scaling however will increase different prices related to the answer. Take into account growing the monitoring interval based mostly in your workload traits to stability scaling responsiveness and the price incurred by the answer. You possibly can change the monitoring frequency by altering the monitoring_frequency_minutes if you deploy the answer.
- Resolution isolation – The on-demand and scheduled scaling options had been designed and examined in isolation to assist predictable conduct and optimum efficiency. You possibly can deploy both answer, however keep away from operating each options concurrently on the identical cluster. Utilizing each approaches collectively may cause unpredictable scaling conduct the place the options may battle with one another’s scaling choices, resulting in useful resource rivalry and potential scaling oscillations. Select the method that finest matches your workload patterns and deploy just one scaling answer per cluster.
Clear up
Comply with these steps to delete the assets created by the answer. Be certain that all of the scaling operations which are in flight are accomplished earlier than you run the cleanup.Delete the on-demand scaling answer with the next code:
Delete the scheduled scaling answer with the next code:
Abstract
On this publish, we confirmed use clever rebalancing to scale your Specific based mostly cluster based mostly on your online business necessities with out requiring handbook partition rebalancing. You possibly can lengthen the answer to make use of the particular CloudWatch metrics that your online business is dependent upon to dynamically scale your Kafka cluster. Equally, you may alter the scheduled scaling answer to scale out and scale in your cluster if you anticipate vital change in visitors to your cluster at particular occasions.To be taught extra concerning the providers used on this answer, consult with the next assets:
Concerning the authors

{kind=link}