
With the rising adoption of open desk codecs like Apache Iceberg, Amazon Redshift continues to advance its capabilities for open format information lakes. In 2025, Amazon Redshift delivered a number of efficiency optimizations that improved question efficiency over twofold for Iceberg workloads on Amazon Redshift Serverless, delivering distinctive efficiency and cost-effectiveness to your information lake workloads.
On this put up, we describe a number of the optimizations that led to those efficiency positive factors. Information lakes have change into a basis of recent analytics, serving to organizations retailer huge quantities of structured and semi-structured information in cost-effective information codecs like Apache Parquet whereas sustaining flexibility by open desk codecs. This structure creates distinctive efficiency optimization alternatives throughout the complete question processing pipeline.
Efficiency enhancements
Our newest enhancements span a number of areas of the Amazon Redshift SQL question processing engine, together with vectorized scanners that speed up execution, optimum question plans powered by just-in-time (JIT) runtime statistics, distributed Bloom filters, and new decorrelation guidelines.
The next chart summarizes the efficiency enhancements achieved thus far in 2025, as measured by {industry} customary 10 TB TPC-DS and TPC-H benchmarks run on Iceberg tables on an 88 RPU Redshift Serverless endpoint.
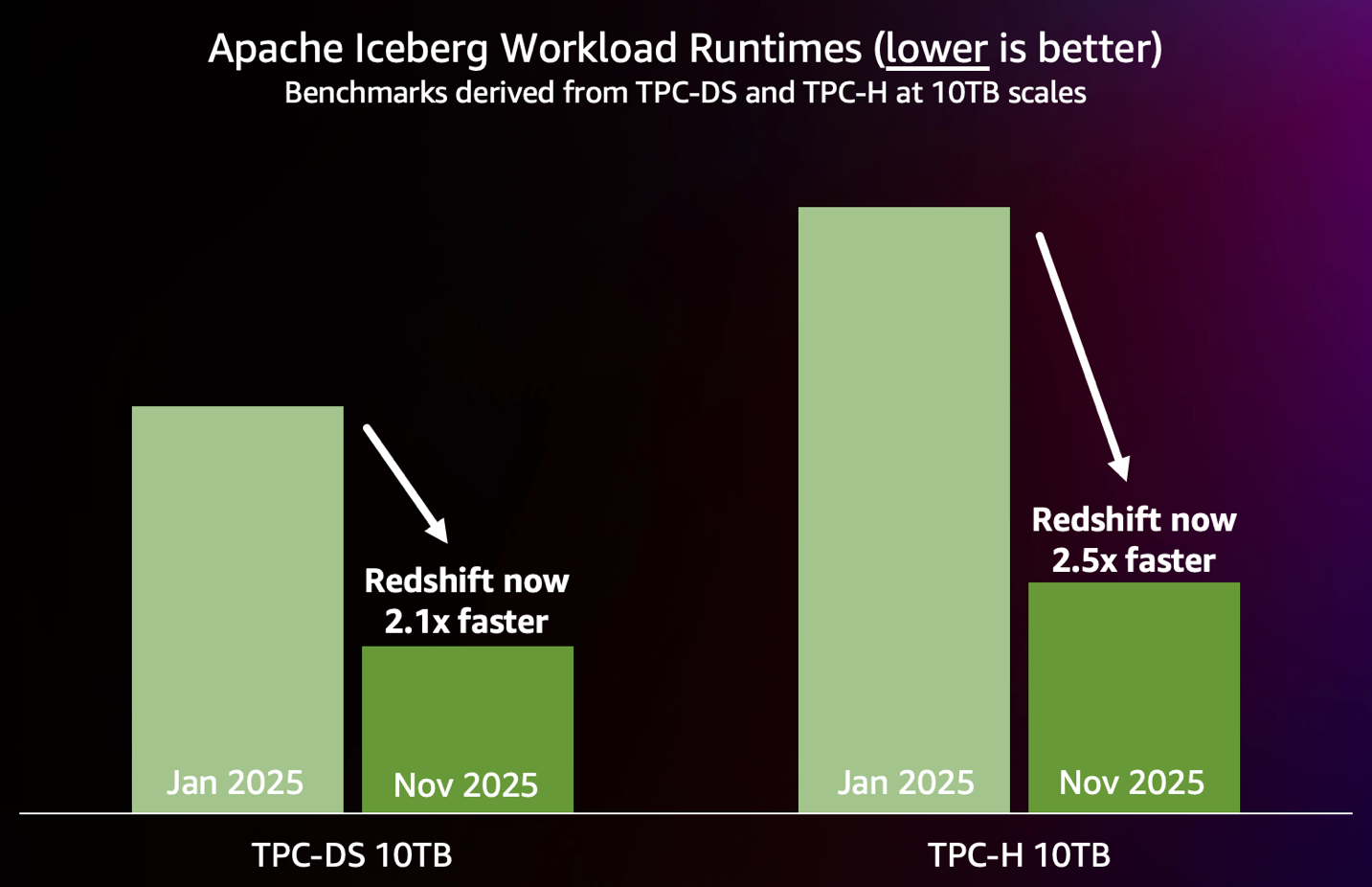
Discover the very best efficiency to your workloads
The efficiency outcomes offered on this put up are primarily based on benchmarks derived from the industry-standard TPC-DS and TPC-H benchmarks, and have the next traits:
- The schema and information of Iceberg tables are used unmodified from TPC-DS. Tables are partitioned to replicate real-world information group patterns.
- The queries are generated utilizing the official TPC-DS and TPC-H kits with question parameters generated utilizing the default random seed of the kits.
- The TPC-DS check consists of all 99 TPC-DS SELECT queries. It doesn’t embrace upkeep and throughput steps. The TPC-H check consists of all 22 TPC-H SELECT queries.
- Benchmarks are run out of the field: no guide tuning or stats assortment is finished for the workloads.
Within the following sections, we focus on key efficiency enhancements delivered in 2025.
Sooner information lake scans
To enhance information lake learn efficiency, the Amazon Redshift workforce constructed a very new scan layer designed from the ground-up for information lakes. This new scan layer features a purpose-built I/O subsystem, incorporating sensible prefetch capabilities to scale back information latency. Moreover, the brand new scan layer is optimized for processing Apache Parquet recordsdata, probably the most generally used file format for Iceberg, by quick vectorized scans.
This new scan layer additionally consists of refined information pruning mechanisms that function at each partition and file ranges, dramatically lowering the amount of information that must be scanned. This pruning functionality works in concord with the sensible prefetch system, making a coordinated strategy that maximizes effectivity all through the complete information retrieval course of.
JIT ANALYZE for Iceberg tables
Not like conventional information warehouses, information lakes typically lack complete table- and column-level statistics concerning the underlying information, making it difficult for the planner and optimizer within the question engine to decide on up-front which execution plan can be most optimum. Sub-optimal plans can result in slower and fewer predictable efficiency.
JIT ANALYZE is a brand new Amazon Redshift characteristic that mechanically collects and makes use of statistics for Iceberg tables throughout question execution—minimizing guide statistics assortment whereas giving the planner and optimizer within the question engine the knowledge it must generate optimum question plans. The system makes use of clever heuristics to establish queries that may profit from statistics, performs quick file-level sampling utilizing Iceberg metadata, and extrapolates inhabitants statistics utilizing superior methods.
JIT ANALYZE delivers out-of-the-box efficiency almost equal to queries which have pre-calculated statistics, whereas offering the muse for a lot of different efficiency optimizations. Some TPC-DS queries improved by 50 instances quicker with these statistics.
Question optimizations
For correlated subqueries akin to those who comprise EXISTS/IN clauses, Amazon Redshift makes use of decorrelation guidelines to rewrite the queries. In lots of instances, these decorrelation guidelines weren’t producing optimum plans, leading to question execution efficiency regressions. To deal with this, we launched a brand new inside be part of kind, SEMI JOIN, and a brand new decorrelation rule primarily based on this be part of kind. This decorrelation rule helps in producing probably the most optimum plans, thereby bettering execution efficiency. For example, one of many TPC-DS queries that accommodates EXIST clause ran 7 instances quicker with this optimization.
We launched distributed Bloom filter optimization for information lake workloads. Distributed Bloom filters create Bloom filters regionally in each compute node after which distributes them to each different node. Distributing Bloom filters can considerably cut back the quantity of information that must be despatched over the community for the be part of by filtering out the tuples earlier. This gives good efficiency positive factors for big, advanced information lake queries that course of and be part of massive quantities of information.
Conclusion
These efficiency enhancements for Iceberg workloads signify a significant leap ahead in Redshift information lake capabilities. By specializing in out-of-the-box efficiency, we’ve made it simple to realize distinctive question efficiency with out advanced tuning or optimization.
These enhancements display the facility of deep technical innovation mixed with sensible buyer focus. JIT ANALYZE reduces the operational burden of statistics administration whereas offering optimum question planning data. The brand new Redshift information lake question engine on Redshift Serverless was rewritten from the bottom up for best-in-class scan efficiency, and lays the groundwork for extra superior efficiency optimizations. Semi-join optimizations sort out a number of the most difficult question patterns in analytical workloads. You may run advanced analytical workloads in your Iceberg information and get quick, predictable question efficiency.
Amazon Redshift is dedicated to being the very best analytics engine for information lake workloads, and these efficiency optimizations signify our continued funding in that objective.
To study extra about Amazon Redshift and its efficiency capabilities, go to the Amazon Redshift product web page. To get began with Redshift, you’ll be able to attempt Amazon Redshift Serverless and begin querying information in minutes with out having to arrange and handle information warehouse infrastructure. For extra particulars on efficiency greatest practices, see the Amazon Redshift Database Developer Information. To remain up-to-date with the newest developments in Amazon Redshift, subscribe to the What’s New in Amazon Redshift RSS feed.
Particular because of this put up’s contributors: Martin Milenkoski, Gerard Louw, Konrad Werblinski, Mengchu Cai, Mehmet Bulut, Mohammed Alkateb, and Sanket Hase

{kind=link}