: Reinforcement as a Pretraining Goal for Constructing Reasoning Throughout Pretraining")
Why this issues technically: in contrast to prior “reinforcement pretraining” variants that depend on sparse, binary correctness indicators or proxy filters, RLP’s dense, verifier-free reward attaches position-wise credit score wherever pondering improves prediction, enabling updates at each token place usually web-scale corpora with out exterior verifiers or curated reply keys.
Understanding the Outcomes
Qwen3-1.7B-Base: Pretraining with RLP improved the general math+science common by ~19% vs the bottom mannequin and ~17% vs compute-matched steady pretraining (CPT). After similar post-training (SFT + RLVR) throughout all variants, the RLP-initialized mannequin retained a ~7–8% relative benefit, with the most important positive aspects on reasoning-heavy benchmarks (AIME25, MMLU-Professional).
Nemotron-Nano-12B v2: Making use of RLP to a 12B hybrid Mamba-Transformer checkpoint yielded an total common improve from 42.81% to 61.32% and an absolute +23% achieve on scientific reasoning, regardless that the RLP run used ~200B fewer tokens (coaching for 19.8T vs 20T tokens; RLP utilized for 250M tokens). This highlights knowledge effectivity and architecture-agnostic conduct.
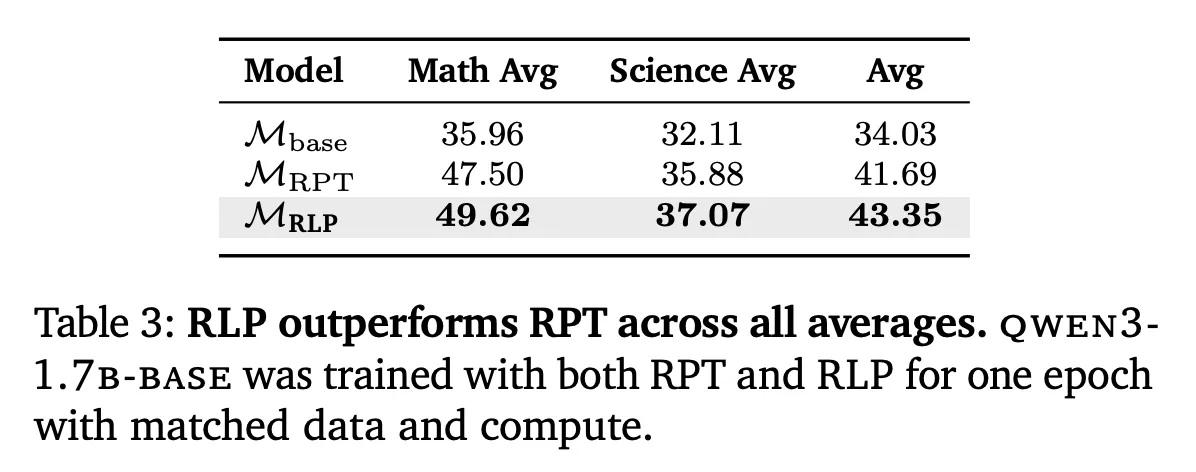
RPT comparability: Underneath matched knowledge and compute with Omni-MATH-style settings, RLP outperformed RPT on math, science, and total averages—attributed to RLP’s steady information-gain reward versus RPT’s sparse binary sign and entropy-filtered tokens.
Positioning vs. Submit-Coaching RL and Information Curation
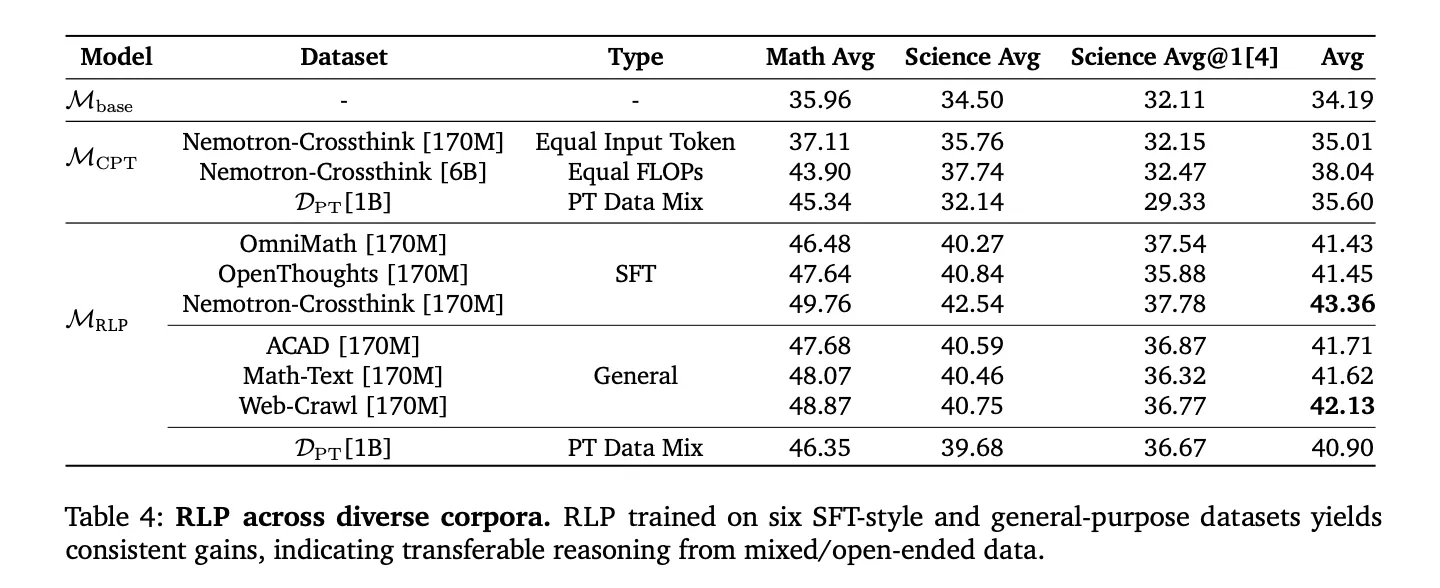
Reinforcement Studying Pretraining (RLP) is orthogonal to post-training pipelines (SFT, RLVR) and exhibits compounding enhancements after normal alignment. As a result of the reward is computed from mannequin log-evidence relatively than exterior verifiers, it scales to domain-agnostic corpora (net crawl, tutorial textual content, textbooks) and SFT-style reasoning corpora, avoiding the brittleness of slender curated datasets. In compute-matched comparisons (together with CPT with 35× extra tokens to match FLOPs), RLP nonetheless led on total averages, suggesting the enhancements derive from goal design, not price range.
Key Takeaways
- RLP makes reasoning a pretraining goal: pattern a chain-of-thought earlier than next-token prediction and reward it by data achieve over a no-think EMA baseline.
- Verifier-free, dense, position-wise sign: works on strange textual content streams with out exterior graders, enabling scalable pretraining updates on each token.
- Qwen3-1.7B outcomes: +19% vs Base and +17% vs compute-matched CPT throughout pretraining; with similar SFT+RLVR, RLP retains ~7–8% positive aspects (largest on AIME25, MMLU-Professional).
- Nemotron-Nano-12B v2: total common rises 42.81% → 61.32% (+18.51 pp; ~35–43% rel.) and +23 factors on scientific reasoning, utilizing ~200B fewer NTP tokens.
- Coaching particulars that matter: replace gradients solely on thought tokens with a clipped surrogate and group-relative benefits; extra rollouts (≈16) and longer thought lengths (≈2048) assist; token-level KL anchoring presents no profit.
Conclusion
RLP reframes pretraining to instantly reward “think-before-predict” conduct utilizing a verifier-free, information-gain sign, yielding sturdy reasoning positive aspects that persist by means of similar SFT+RLVR and prolong throughout architectures (Qwen3-1.7B, Nemotron-Nano-12B v2). The tactic’s goal—contrasting CoT-conditioned chance in opposition to a no-think EMA baseline—integrates cleanly into large-scale pipelines with out curated verifiers, making it a sensible improve to next-token pretraining relatively than a post-training add-on.
Try the Paper, Code and Mission Web page. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}