
NVIDIA has launched its Streaming Sortformer, a breakthrough in real-time speaker diarization that immediately identifies and labels individuals in conferences, calls, and voice-enabled purposes—even in noisy, multi-speaker environments. Designed for low-latency, GPU-powered inference, the mannequin is optimized for English and Mandarin, and may monitor as much as 4 simultaneous audio system with millisecond-level precision. This innovation marks a serious step ahead in conversational AI, enabling a brand new technology of productiveness, compliance, and interactive voice purposes.
Core Capabilities: Actual-Time, Multi-Speaker Monitoring
Not like conventional diarization techniques that require batch processing or costly, specialised {hardware}, Streaming Sortformer performs frame-level diarization in actual time. Meaning each utterance is tagged with a speaker label (e.g., spk_0, spk_1) and a exact timestamp because the dialog unfolds. The mannequin is low-latency, processing audio in small, overlapping chunks—a vital function for stay transcriptions, sensible assistants, and call middle analytics the place each millisecond counts.
- Labels 2–4+ audio system on the fly: Robustly tracks as much as 4 individuals per dialog, assigning constant labels as every speaker enters the stream.
- GPU-accelerated inference: Absolutely optimized for NVIDIA GPUs, integrating seamlessly with the NVIDIA NeMo and NVIDIA Riva platforms for scalable, manufacturing deployment.
- Multilingual assist: Whereas tuned for English, the mannequin reveals robust outcomes on Mandarin assembly information and even non-English datasets like CALLHOME, indicating broad language compatibility past its core targets.
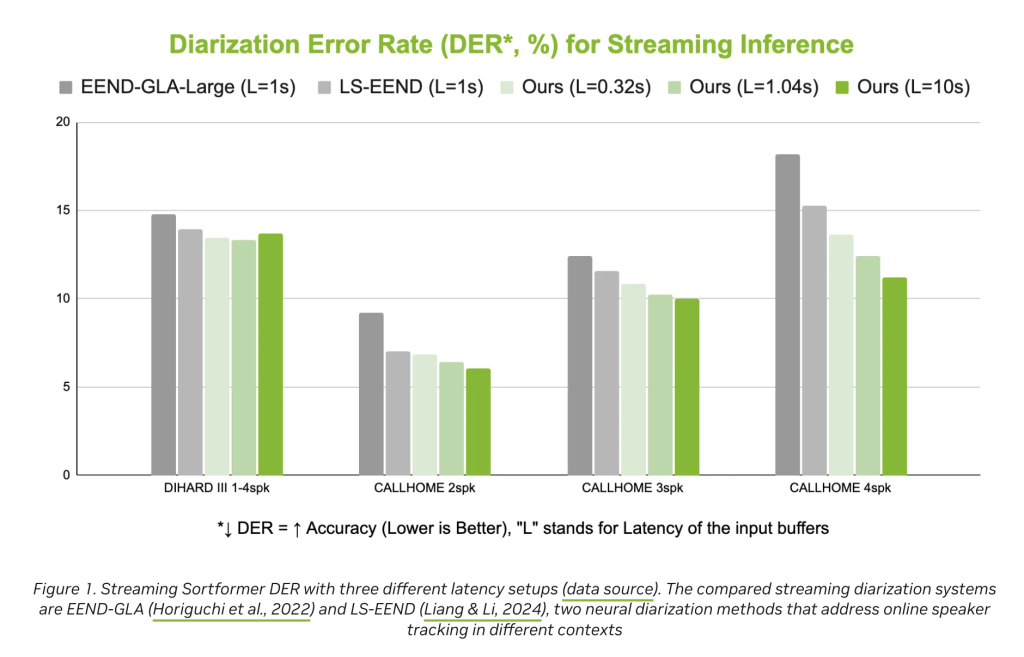
- Precision and reliability: Delivers a aggressive Diarization Error Price (DER), outperforming current options like EEND-GLA and LS-EEND in real-world benchmarks.
These capabilities make Streaming Sortformer instantly helpful for stay assembly transcripts, contact middle compliance logs, voicebot turn-taking, media modifying, and enterprise analytics—all situations the place realizing “who stated what, when” is crucial.
Structure and Innovation
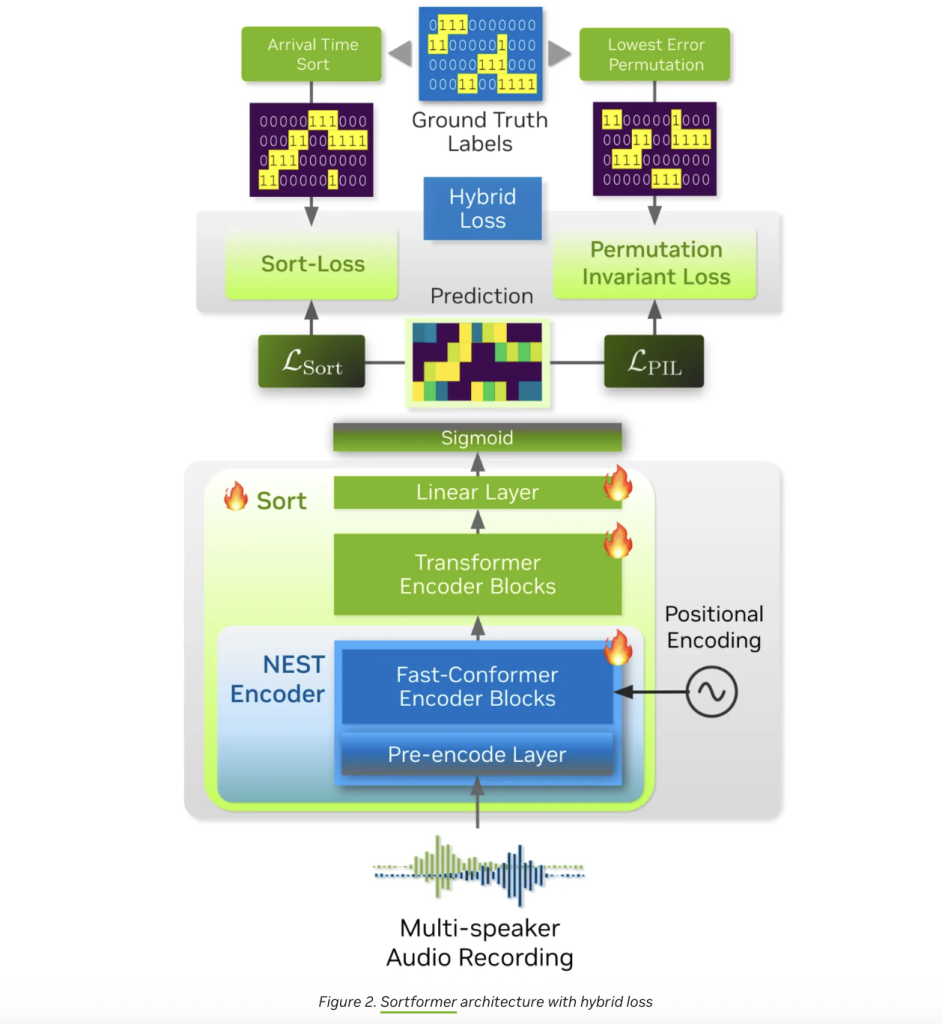
At its core, Streaming Sortformer is a hybrid neural structure, combining the strengths of Convolutional Neural Networks (CNNs), Conformers, and Transformers. Right here’s the way it works:
- Audio pre-processing: A convolutional pre-encode module compresses uncooked audio right into a compact illustration, preserving vital acoustic options whereas lowering computational overhead.
- Context-aware sorting: A multi-layer Quick-Conformer encoder (17 layers within the streaming variant) processes these options, extracting speaker-specific embeddings. These are then fed into an 18-layer Transformer encoder with a hidden dimension of 192, adopted by two feedforward layers with sigmoid outputs for every body.
- Arrival-Order Speaker Cache (AOSC): The actual magic occurs right here. Streaming Sortformer maintains a dynamic reminiscence buffer—AOSC—that shops embeddings of all audio system detected thus far. As new audio chunks arrive, the mannequin compares them in opposition to this cache, making certain that every participant retains a constant label all through the dialog. This elegant answer to the “speaker permutation drawback” is what allows real-time, multi-speaker monitoring with out costly recomputation.
- Finish-to-end coaching: Not like some diarization pipelines that depend on separate voice exercise detection and clustering steps, Sortformer is skilled end-to-end, unifying speaker separation and labeling in a single neural community.
Integration and Deployment
Streaming Sortformer is open, production-grade, and prepared for integration into present workflows. Builders can deploy it through NVIDIA NeMo or Riva, making it a drop-in substitute for legacy diarization techniques. The mannequin accepts commonplace 16kHz mono-channel audio (WAV information) and outputs a matrix of speaker exercise possibilities for every body—perfect for constructing customized analytics or transcription pipelines.
Actual-World Functions
The sensible affect of Streaming Sortformer is huge:
- Conferences and productiveness: Generate stay, speaker-tagged transcripts and summaries, making it simpler to comply with discussions and assign motion gadgets.
- Contact facilities: Separate agent and buyer audio streams for compliance, high quality assurance, and real-time teaching.
- Voicebots and AI assistants: Allow extra pure, context-aware dialogues by precisely monitoring speaker id and turn-taking patterns.
- Media and broadcast: Routinely label audio system in recordings for modifying, transcription, and moderation workflows.
- Enterprise compliance: Create auditable, speaker-resolved logs for regulatory and authorized necessities.
Benchmark Efficiency and Limitations
In benchmarks, Streaming Sortformer achieves a decrease Diarization Error Price (DER) than current streaming diarization techniques, indicating larger accuracy in real-world situations. Nevertheless, the mannequin is presently optimized for situations with as much as 4 audio system; increasing to bigger teams stays an space for future analysis. Efficiency can also range in difficult acoustic environments or with underrepresented languages, although the structure’s flexibility suggests room for adaptation as new coaching information turns into accessible.
Technical Highlights at a Look
| Characteristic | Streaming Sortformer |
|---|---|
| Max audio system | 2–4+ |
| Latency | Low (real-time, frame-level) |
| Languages | English (optimized), Mandarin (validated), others potential |
| Structure | CNN + Quick-Conformer + Transformer + AOSC |
| Integration | NVIDIA NeMo, NVIDIA Riva, Hugging Face |
| Output | Body-level speaker labels, exact timestamps |
| GPU Help | Sure (NVIDIA GPUs required) |
| Open Supply | Sure (pre-trained fashions, codebase) |
Trying Forward
NVIDIA’s Streaming Sortformer is not only a technical demo—it’s a production-ready software already altering how enterprises, builders, and repair suppliers deal with multi-speaker audio. With GPU acceleration, seamless integration, and sturdy efficiency throughout languages, it’s poised to grow to be the de facto commonplace for real-time speaker diarization in 2025 and past.
For AI managers, content material creators, and digital entrepreneurs targeted on conversational analytics, cloud infrastructure, or voice purposes, Streaming Sortformer is a must-evaluate platform. Its mixture of pace, accuracy, and ease of deployment makes it a compelling selection for anybody constructing the following technology of voice-enabled merchandise.
Abstract
NVIDIA’s Streaming Sortformer delivers immediate, GPU-accelerated speaker diarization for as much as 4 individuals, with confirmed ends in English and Mandarin. Its novel structure and open accessibility place it as a foundational expertise for real-time voice analytics—a leap ahead for conferences, contact facilities, AI assistants, and past.
FAQs: NVIDIA Streaming Sortformer
How does Streaming Sortformer deal with a number of audio system in actual time?
Streaming Sortformer processes audio in small, overlapping chunks and assigns constant labels (e.g., spk_0–spk_3) as every speaker enters the dialog. It maintains a light-weight reminiscence of detected audio system, enabling immediate, frame-level diarization with out ready for the complete recording. This helps fluid, low-latency experiences for stay transcripts, contact facilities, and voice assistants.
What {hardware} and setup are advisable for greatest efficiency?
It’s designed for NVIDIA GPUs to realize low-latency inference. A typical setup makes use of 16 kHz mono audio enter, with integration paths via NVIDIA’s speech AI stacks (e.g., NeMo/Riva) or the accessible pretrained fashions. For manufacturing workloads, allocate a current NVIDIA GPU and guarantee streaming-friendly audio buffering (e.g., 20–40 ms frames with slight overlap).
Does it assist languages past English, and what number of audio system can it monitor?
The present launch targets English with validated efficiency on Mandarin and may label two to 4 audio system on the fly. Whereas it could actually generalize to different languages to some extent, accuracy will depend on acoustic situations and coaching protection. For situations with greater than 4 concurrent audio system, contemplate segmenting the session or evaluating pipeline changes as mannequin variants evolve.
Take a look at the Mannequin on Hugging Face and Technical particulars right here. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}