
NVIDIA has unveiled the Nemotron Nano 2 household, introducing a line of hybrid Mamba-Transformer massive language fashions (LLMs) that not solely push state-of-the-art reasoning accuracy but additionally ship as much as 6× greater inference throughput than fashions of comparable measurement. This launch stands out with unprecedented transparency in knowledge and methodology, as NVIDIA supplies a lot of the coaching corpus and recipes alongside mannequin checkpoints for the neighborhood. Critically, these fashions preserve large 128K-token context functionality on a single midrange GPU, considerably decreasing obstacles for long-context reasoning and real-world deployment.
Key Highlights
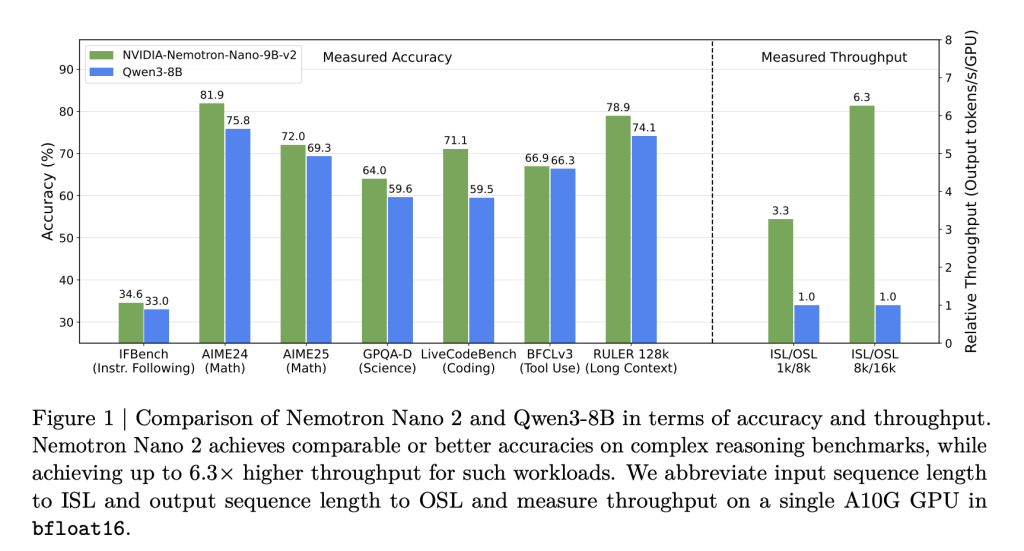
- 6× throughput vs. equally sized fashions: Nemotron Nano 2 fashions ship as much as 6.3× the token technology velocity of fashions like Qwen3-8B in reasoning-heavy situations—with out sacrificing accuracy.
- Superior accuracy for reasoning, coding & multilingual duties: Benchmarks present on-par or higher outcomes vs. aggressive open fashions, notably exceeding friends in math, code, instrument use, and long-context duties.
- 128K context size on a single GPU: Environment friendly pruning and hybrid structure make it doable to run 128,000 token inference on a single NVIDIA A10G GPU (22GiB).
- Open knowledge & weights: Many of the pretraining and post-training datasets, together with code, math, multilingual, artificial SFT, and reasoning knowledge, are launched with permissive licensing on Hugging Face.
Hybrid Structure: Mamba Meets Transformer
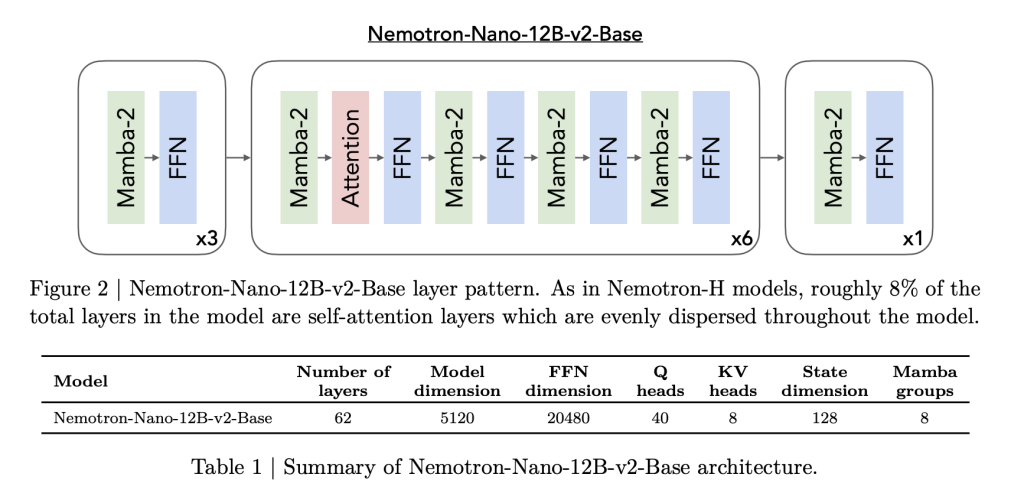
Nemotron Nano 2 is constructed on a hybrid Mamba-Transformer spine, impressed by the Nemotron-H Structure. Most conventional self-attention layers are changed by environment friendly Mamba-2 layers, with solely about 8% of the overall layers utilizing self-attention. This structure is rigorously crafted:
- Mannequin Particulars: The 9B-parameter mannequin options 56 layers (out of a pre-trained 62), a hidden measurement of 4480, with grouped-query consideration and Mamba-2 state house layers facilitating each scalability and lengthy sequence retention.
- Mamba-2 Improvements: These state-space layers, not too long ago popularized as high-throughput sequence fashions, are interleaved with sparse self-attention (to protect long-range dependencies), and enormous feed-forward networks.
This construction allows excessive throughput on reasoning duties requiring “considering traces”—lengthy generations based mostly on lengthy, in-context enter—the place conventional transformer-based architectures typically decelerate or run out of reminiscence.
Coaching Recipe: Large Information Variety, Open Sourcing
Nemotron Nano 2 fashions are skilled and distilled from a 12B parameter instructor mannequin utilizing an intensive, high-quality corpus. NVIDIA’s unprecedented knowledge transparency is a spotlight:
- 20T tokens pretraining: Information sources embrace curated and artificial corpora for internet, math, code, multilingual, tutorial, and STEM domains.
- Main Datasets Launched:
- Nemotron-CC-v2: Multilingual internet crawl (15 languages), artificial Q&A rephrasing, deduplication.
- Nemotron-CC-Math: 133B tokens of math content material, standardized to LaTeX, over 52B “highest high quality” subset.
- Nemotron-Pretraining-Code: Curated and quality-filtered GitHub supply code; rigorous decontamination and deduplication.
- Nemotron-Pretraining-SFT: Artificial, instruction-following datasets throughout STEM, reasoning, and basic domains.
- Put up-training Information: Contains over 80B tokens of supervised fine-tuning (SFT), RLHF, tool-calling, and multilingual datasets—most of that are open-sourced for direct reproducibility.
Alignment, Distillation, and Compression: Unlocking Price-Efficient, Lengthy-Context Reasoning
NVIDIA’s mannequin compression course of is constructed on the “Minitron” and Mamba pruning frameworks:
- Information distillation from the 12B instructor reduces the mannequin to 9B parameters, with cautious pruning of layers, FFN dimensions, and embedding width.
- Multi-stage SFT and RL: Contains tool-calling optimization (BFCL v3), instruction-following (IFEval), DPO and GRPO reinforcement, and “considering price range” management (help for controllable reasoning-token budgets at inference).
- Reminiscence-targeted NAS: Via structure search, the pruned fashions are particularly engineered in order that the mannequin and key-value cache each match—and stay performant—throughout the A10G GPU reminiscence at a 128k context size.
The end result: inference speeds of as much as 6× sooner than open opponents in situations with massive enter/output tokens, with out compromised process accuracy.
Benchmarking: Superior Reasoning and Multilingual Capabilities
In head-to-head evaluations, Nemotron Nano 2 fashions excel:
| Process/Bench | Nemotron-Nano-9B-v2 | Qwen3-8B | Gemma3-12B |
|---|---|---|---|
| MMLU (Basic) | 74.5 | 76.4 | 73.6 |
| MMLU-Professional (5-shot) | 59.4 | 56.3 | 45.1 |
| GSM8K CoT (Math) | 91.4 | 84.0 | 74.5 |
| MATH | 80.5 | 55.4 | 42.4 |
| HumanEval+ | 58.5 | 57.6 | 36.7 |
| RULER-128K (Lengthy Context) | 82.2 | – | 80.7 |
| World-MMLU-Lite (Avg Multi) | 69.9 | 72.8 | 71.9 |
| MGSM Multilingual Math (Avg) | 84.8 | 64.5 | 57.1 |
- Throughput (tokens/s/GPU) at 8k enter/16k output:
- Nemotron-Nano-9B-v2: as much as 6.3× Qwen3-8B in reasoning traces.
- Maintains as much as 128k-context with batch measurement=1—beforehand impractical on midrange GPUs.
Conclusion
NVIDIA’s Nemotron Nano 2 launch is a crucial second for open LLM analysis: it redefines what’s doable on a single cost-effective GPU—each in velocity and context capability—whereas elevating the bar for knowledge transparency and reproducibility. Its hybrid structure, throughput supremacy, and high-quality open datasets are set to speed up innovation throughout the AI ecosystem.
Try the Technical Particulars, Paper and Fashions on Hugging Face. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}