: A Highly effective and Versatile 3D Video Annotation Software for Spatial AI")
How do you create 3D datasets to coach AI for Robotics with out costly conventional approaches? A group of researchers from NVIDIA launched “ViPE: Video Pose Engine for 3D Geometric Notion” bringing a key enchancment for Spatial AI. It addresses the central, agonizing bottleneck that has constrained the sector of 3D laptop imaginative and prescient for years.
ViPE is a strong, versatile engine designed to course of uncooked, unconstrained, “in-the-wild” video footage and mechanically output the important parts of 3D actuality:
- Digital camera Intrinsics (sensor calibration parameters)
- Exact Digital camera Movement (pose)
- Dense, Metric Depth Maps (real-world distances for each pixel)

To really know the magnitude of this breakthrough, we should first perceive the profound issue of the issue it solves.
The problem: Unlocking 3D Actuality from 2D Video
The last word purpose of Spatial AI is to allow machines, robots , autonomous autos, and AR glasses, to understand and work together with the world in 3D. We dwell in a 3D world, however the overwhelming majority of our recorded knowledge, from smartphone clips to cinematic footage, is trapped in 2D.
The Core Drawback: How can we reliably and scalably reverse-engineer the 3D actuality hidden inside these flat video streams?
Reaching this precisely from on a regular basis video, which options shaky actions, dynamic objects, and unknown digicam varieties, is notoriously tough, but it’s the important first step for nearly any superior spatial software.
Issues with Present Approaches
For many years, the sector has been compelled to decide on between 2 highly effective but flawed paradigms.
1. The Precision Lure (Classical SLAM/SfM)
Conventional strategies like Simultaneous Localization and Mapping (SLAM) and Construction-from-Movement (SfM) depend on refined geometric optimization. They’re able to pinpoint accuracy underneath splendid circumstances.
The Deadly Flaw: Brittleness. These methods usually assume the world is static. Introduce a shifting automobile, a textureless wall, or use an unknown digicam, and all the reconstruction can shatter. They’re too delicate for the messy actuality of on a regular basis video.
2. The Scalability Wall (Finish-to-Finish Deep Studying)
Lately, highly effective deep studying fashions have emerged. By coaching on huge datasets, they be taught strong “priors” concerning the world and are impressively resilient to noise and dynamism.
The Deadly Flaw: Intractability. These fashions are computationally hungry. Their reminiscence necessities explode as video size will increase, making the processing of lengthy movies virtually inconceivable. They merely don’t scale.
This impasse created a dilemma. The way forward for superior AI calls for huge datasets annotated with excellent 3D geometry, however the instruments required to generate that knowledge had been both too brittle or too sluggish to deploy at scale.
Meet ViPE: NVIDIA’s Hybrid Breakthrough Shatters the Mould
That is the place ViPE modifications the sport. It’s not merely an incremental enchancment; it’s a well-designed and well-integrated hybrid pipeline that efficiently fuses the most effective of each worlds. It takes the environment friendly, mathematically rigorous optimization framework of classical SLAM and injects it with the highly effective, realized instinct of contemporary deep neural networks.
This synergy permits ViPE to be correct, strong, environment friendly, and versatile concurrently. ViPE delivers an answer that scales with out compromising on precision.
The way it Works: Contained in the ViPE Engine
ViPE‘s structure makes use of a keyframe-based Bundle Adjustment (BA) framework for effectivity.
Listed below are the Key Improvements:
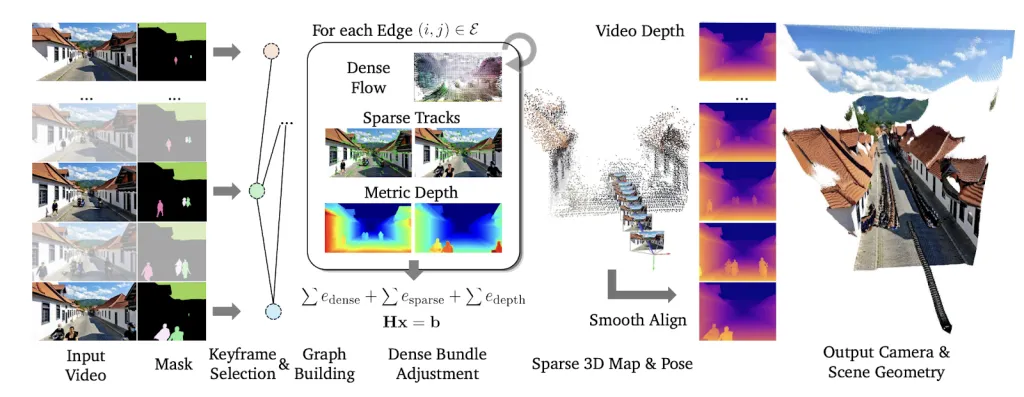
Key Innovation 1: A Synergy of Highly effective Constraints
ViPE achieves unprecedented accuracy by masterfully balancing three important inputs:
- Dense Circulate (Discovered Robustness): Makes use of a realized optical stream community for strong correspondences between frames, even in powerful circumstances.
- Sparse Tracks (Classical Precision): Incorporates high-resolution, conventional characteristic monitoring to seize fine-grained particulars, drastically bettering localization accuracy.
- Metric Depth Regularization (Actual-World Scale): ViPE integrates priors from state-of-the-art monocular depth fashions to supply leads to true, real-world metric scale.
Key Innovation 2: Mastering Dynamic, Actual-World Scenes
To deal with the chaos of real-world video, ViPE employs superior foundational segmentation instruments, GroundingDINO and Phase Something (SAM), to determine and masks out shifting objects (e.g., folks, vehicles). By intelligently ignoring these dynamic areas, ViPE ensures the digicam movement is calculated based mostly solely on the static setting.
Key Innovation 3: Quick Velocity & Normal Versatility
ViPE operates at a exceptional 3-5 FPS on a single GPU, making it considerably quicker than comparable strategies. Moreover, ViPE is universally relevant, supporting various digicam fashions together with commonplace, wide-angle/fisheye, and even 360° panoramic movies, mechanically optimizing the intrinsics for every.
Key Innovation 4: Excessive-Constancy Depth Maps
The ultimate output is enhanced by a complicated post-processing step. ViPE easily aligns high-detail depth maps with the geometrically constant maps from its core course of. The result’s beautiful: depth maps which might be each high-fidelity and temporally steady.
The outcomes are beautiful even advanced scenes…see beneath

Confirmed Efficiency
ViPE demonstrates superior efficiency, outperforming current uncalibrated pose estimation baselines by a staggering:
- 18% on the TUM dataset (indoor dynamics)
- 50% on the KITTI dataset (outside driving)
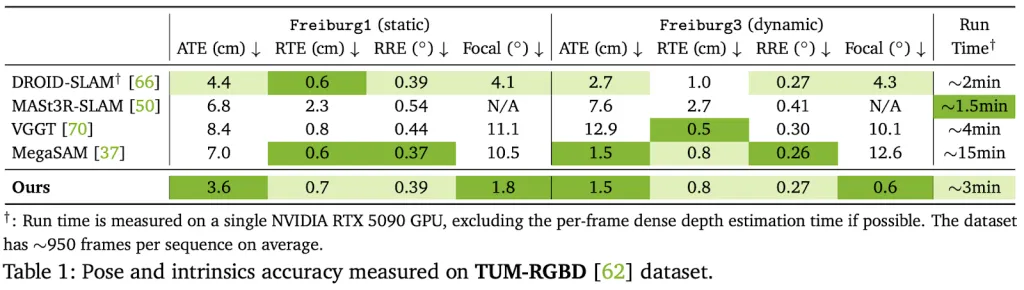
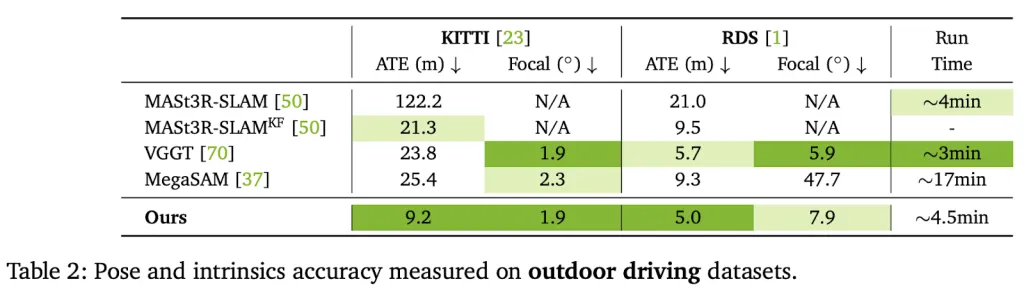
Crucially, the evaluations verify that ViPE gives correct metric scale, whereas different approaches/engines usually produce inconsistent, unusable scales.
The Actual Innovation: A Information Explosion for Spatial AI
Essentially the most important contribution of this work is not only the engine itself, however its deployment as a large-scale knowledge annotation manufacturing unit to gas the way forward for AI. The dearth of huge, various, geometrically annotated video knowledge has been the first bottleneck for coaching strong 3D fashions. ViPE solves this downside!.How
The analysis group used ViPE to create and launch an unprecedented dataset totaling roughly 96 million annotated frames:
- Dynpose-100K++: Almost 100,000 real-world web movies (15.7M frames) with high-quality poses and dense geometry.
- Wild-SDG-1M: An enormous assortment of 1 million high-quality, AI-generated movies (78M frames).
- Web360: A specialised dataset of annotated panoramic movies.
This huge launch gives the required gas for the following era of 3D geometric basis fashions and is already proving instrumental in coaching superior world era fashions like NVIDIA’s Gen3C and Cosmos.
By resolving the elemental conflicts between accuracy, robustness, and scalability, ViPE gives the sensible, environment friendly, and common instrument wanted to unlock the 3D construction of virtually any video. Its launch is poised to dramatically speed up innovation throughout all the panorama of Spatial AI, robotics, and AR/VR.
NVIDIA AI has launched the code right here
Sources /hyperlinks
Datasets:
- https://huggingface.co/datasets/nvidia/vipe-dynpose-100kpp
- https://huggingface.co/datasets/nvidia/vipe-wild-sdg-1m
- https://huggingface.co/datasets/nvidia/vipe-web360
- https://www.nvidia.com/en-us/ai/cosmos/
Because of the NVIDIA group for the thought management/ Sources for this text. NVIDIA group has supported and sponsored this content material/article.

Jean-marc is a profitable AI enterprise government .He leads and accelerates development for AI powered options and began a pc imaginative and prescient firm in 2006. He’s a acknowledged speaker at AI conferences and has an MBA from Stanford.

{kind=link}