
NVIDIA researchers have shattered the longstanding effectivity hurdle in massive language mannequin (LLM) inference, releasing Jet-Nemotron—a household of fashions (2B and 4B) that delivers as much as 53.6× increased technology throughput than main full-attention LLMs whereas matching, and even surpassing, their accuracy. Most significantly, this breakthrough isn’t the results of a brand new pre-training run from scratch, however relatively a retrofit of current, pre-trained fashions utilizing a novel approach known as Put up Neural Structure Search (PostNAS). The implications are transformative for companies, practitioners, and researchers alike.
The Want for Velocity in Fashionable LLMs
Whereas at present’s state-of-the-art (SOTA) LLMs, like Qwen3, Llama3.2, and Gemma3, have set new benchmarks for accuracy and adaptability, their O(n²) self-attention mechanism incurs exorbitant prices—each in compute and reminiscence—particularly for long-context duties. This makes them costly to deploy at scale and practically not possible to run on edge or memory-constrained gadgets. Efforts to interchange full-attention Transformers with extra environment friendly architectures (Mamba2, GLA, RWKV, and many others.) have struggled to shut the accuracy hole, till now.
PostNAS: A Surgical, Capital-Environment friendly Overhaul
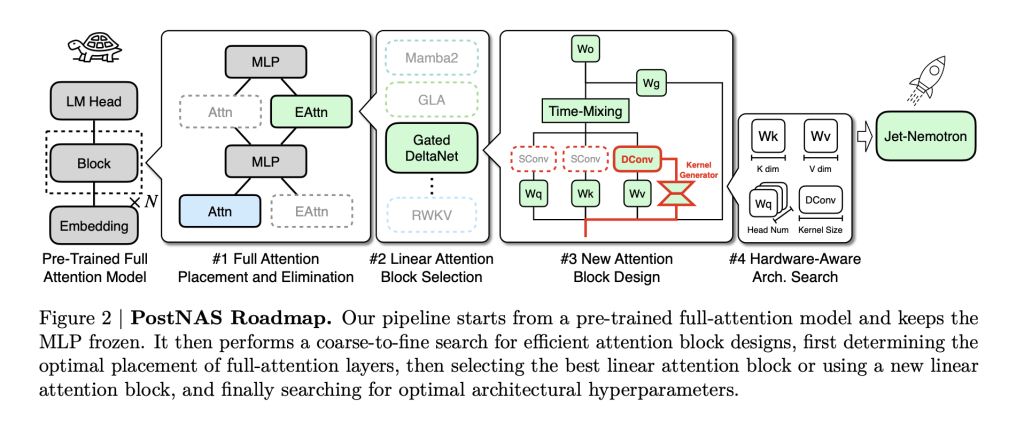
The core innovation is PostNAS: a neural structure search pipeline designed particularly for effectively retrofitting pre-trained fashions. Right here’s the way it works:
- Freeze the Data: Begin with a SOTA full-attention mannequin (like Qwen2.5). Freeze its MLP layers—this preserves the mannequin’s realized intelligence and enormously reduces coaching price.
- Surgical Substitute: Change computationally costly full-attention (Transformers) with JetBlock, a brand new, hardware-efficient linear consideration block designed for NVIDIA’s newest GPUs.
- Hybrid, {Hardware}-Conscious Design: Use super-network coaching and beam search to mechanically decide the optimum placement and minimal set of full-attention layers essential to protect accuracy on key duties (retrieval, math, MMLU, coding, and many others.). This step is task-specific and hardware-aware: the search maximizes throughput for goal {hardware}, not simply parameter depend.
- Scale and Deploy: The result’s a hybrid-architecture LLM that inherits the spine intelligence of the unique mannequin however slashes latency and reminiscence footprint.
JetBlock is especially noteworthy: it introduces dynamic causal convolution kernels conditioned on enter (not like static kernels in prior linear consideration blocks) and removes redundant convolutions for streamlined effectivity. With hardware-aware hyperparameter search, it not solely retains tempo with prior linear consideration designs in throughput, however truly boosts accuracy.
Jet-Nemotron: Efficiency by the Numbers
The important thing metrics from NVIDIA’s technical paper are staggering:
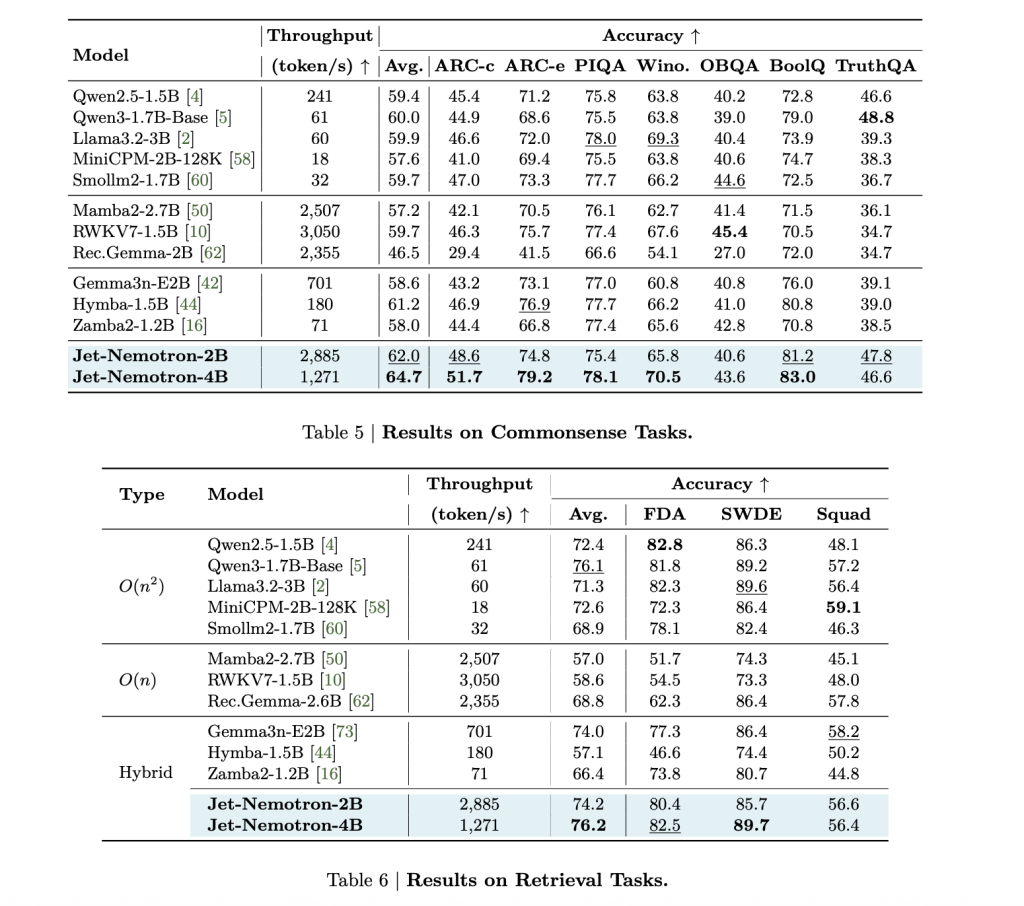
| Mannequin | MMLU-Professional Acc. | Era Throughput (tokens/s, H100) | KV Cache Measurement (MB, 64K context) | Notes |
|---|---|---|---|---|
| Qwen3-1.7B-Base | 37.8 | 61 | 7,168 | Full-attention baseline |
| Jet-Nemotron-2B | 39.0 | 2,885 | 154 | 47× throughput, 47× smaller cache |
| Jet-Nemotron-4B | 44.2 | 1,271 | 258 | 21× throughput, nonetheless SOTA acc. |
| Mamba2-2.7B | 8.6 | 2,507 | 80 | All-linear, a lot decrease accuracy |
| RWKV7-1.5B | 13.4 | 3,050 | 24 | All-linear, a lot decrease accuracy |
| DeepSeek-V3-Small (MoE) | — | — | — | 2.2B activated, 15B complete, decrease acc. |
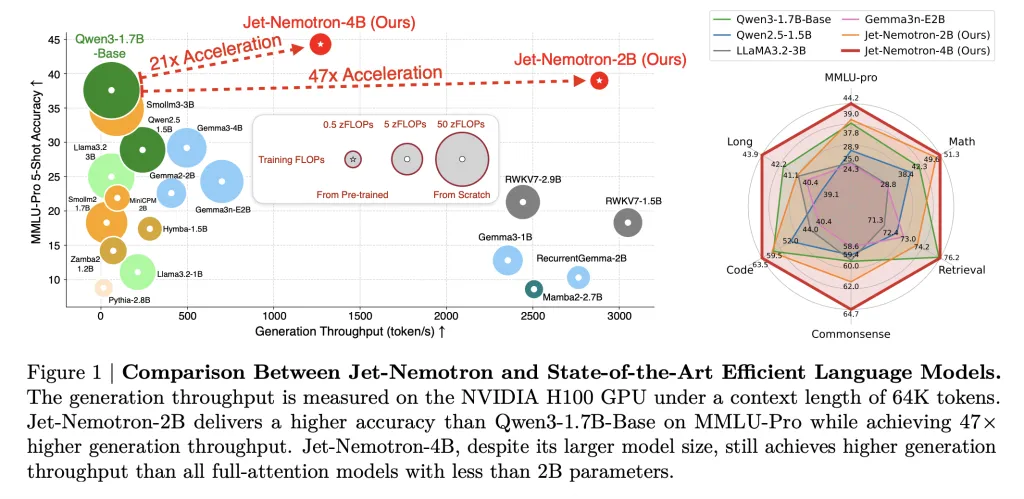
Jet-Nemotron-2B matches or exceeds Qwen3-1.7B-Base on each main benchmark—math, commonsense, coding, retrieval, long-context—whereas delivering 47× increased technology throughput.
This isn’t a small achieve: a 53.6× speedup in decoding at 256K context size means a 98% discount in inference price for a similar quantity of tokens. Prefilling speedups are additionally dramatic: 6.14× sooner at 256K context.
Reminiscence footprint shrinks by 47× (154MB cache vs. 7,168MB for Qwen3-1.7B-Base). This can be a game-changer for edge deployment: Jet-Nemotron-2B is 8.84× and 6.5× sooner than Qwen2.5-1.5B on Jetson Orin and RTX 3090, respectively.
Functions
For Enterprise Leaders: Higher ROI $$
- Inference at scale is now inexpensive. A 53× throughput achieve means dollar-for-dollar, you’ll be able to serve 53× extra customers—or slash internet hosting prices by 98%.
- Operational effectivity is reworked: latency drops, batch sizes develop, and reminiscence constraints vanish. Cloud suppliers can provide SOTA AI at commodity costs.
- The AI enterprise mannequin reshapes: Duties as soon as too costly (real-time doc AI, long-context brokers, on-device copilots) out of the blue turn into viable.
For Practitioners: SOTA on the Edge
- Overlook about quantization, distillation, or pruning compromises. Jet-Nemotron’s tiny KV cache (154MB) and 2B parameters match on Jetson Orin, RTX 3090, and even cell chips—no extra offloading to the cloud.
- No retraining, no knowledge pipeline adjustments: Simply retrofitting. Your current Qwen, Llama, or Gemma checkpoints might be upgraded with out shedding accuracy.
- Actual-world AI providers (search, copilots, summarization, coding) are actually on the spot and scalable.
For Researchers: Decrease Barrier, Increased Innovation
- PostNAS slashes the price of LLM structure innovation. As a substitute of months and tens of millions on pre-training, structure search occurs on frozen spine fashions in a fraction of the time.
- {Hardware}-aware NAS is the longer term: The Jet-Nemotron course of considers KV cache dimension (not simply parameters) because the crucial issue for real-world pace. This can be a paradigm shift in how we measure and optimize effectivity.
- The neighborhood can iterate sooner: PostNAS is a speedy testbed. If a brand new consideration block works right here, it’s price pre-training; if not, it’s filtered out earlier than the large spend.
Abstract
The open-sourcing of Jet-Nemotron and JetBlock (code on GitHub) means the broader AI ecosystem can now retrofit their fashions for unprecedented effectivity. PostNAS just isn’t a one-off trick: it’s a general-purpose framework for accelerating any Transformer, reducing the price of future breakthroughs.
Try the Paper and GitHub Web page. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}