
Whereas VLMs are sturdy at understanding each textual content and pictures, they typically rely solely on textual content when reasoning, limiting their skill to unravel duties that require visible pondering, comparable to spatial puzzles. Folks naturally visualize options fairly than describing each element, however VLMs wrestle to do the identical. Though some current fashions can generate each textual content and pictures, coaching them for picture technology typically weakens their skill to cause. Producing photos additionally doesn’t assist step-by-step visible reasoning. Because of this, unlocking the complete potential of VLMs for advanced, visually grounded pondering stays a key problem within the discipline.
CoT prompting encourages fashions to cause by means of issues step-by-step utilizing examples with intermediate explanations. This concept has been prolonged to multimodal duties, the place visible info is built-in into the reasoning circulation. Strategies like ICoT embed picture areas inside textual content sequences, whereas Visible CoT makes use of visible annotations to coach fashions for improved spatial understanding. Some current fashions can generate each textual content and pictures concurrently; nevertheless, they require heavy supervision and incur excessive computational prices. Individually, researchers are exploring methods to embed reasoning internally inside fashions by guiding their hidden states, utilizing particular tokens or latent representations as an alternative of express reasoning steps.

Researchers from the College of Massachusetts Amherst and MIT suggest an method impressed by how people use psychological imagery, which entails forming easy, task-relevant visuals internally whereas pondering. They introduce Mirage, a framework that permits VLMs to interleave visible reasoning instantly into their textual content outputs with out producing full photos. As an alternative, the mannequin inserts compact visible cues derived from its hidden states. It’s educated in two phases: first with each textual content and visible supervision, then with text-only steering. Reinforcement studying additional refines its reasoning expertise. Mirage permits VLMs to suppose extra like people, thereby enhancing their efficiency on advanced, multimodal duties.
Mirage is a framework impressed by human psychological imagery that permits VLMs to cause utilizing compact visible cues as an alternative of producing full photos. It employs two coaching phases: first, it grounds compressed visible options, often known as latent tokens, inside the reasoning course of utilizing helper photos and joint supervision. Then, it relaxes this constraint, permitting the mannequin to generate its latent tokens and use them to information reasoning. This setup permits interleaved multimodal reasoning. A last reinforcement studying stage additional fine-tunes the mannequin utilizing accuracy and formatting rewards, encouraging each right solutions and structured thought processes.
The research evaluates the mannequin on 4 spatial reasoning duties, comparable to visible puzzles and geometry issues, utilizing a small dataset of 1,000 coaching samples. To assist reasoning, it generates artificial helper photos and thought steps, mimicking how people use sketches and cues to facilitate thought processes. The mannequin constantly outperforms each text-only and multimodal baselines, even in duties that require in depth planning, comparable to maze fixing. A smaller model of the mannequin additionally yields sturdy outcomes, demonstrating that the tactic is strong. Ablation research verify that grounding latent visible tokens first, adopted by versatile coaching, is vital. General, interleaving visible and textual content reasoning with out actual photos boosts each understanding and accuracy.
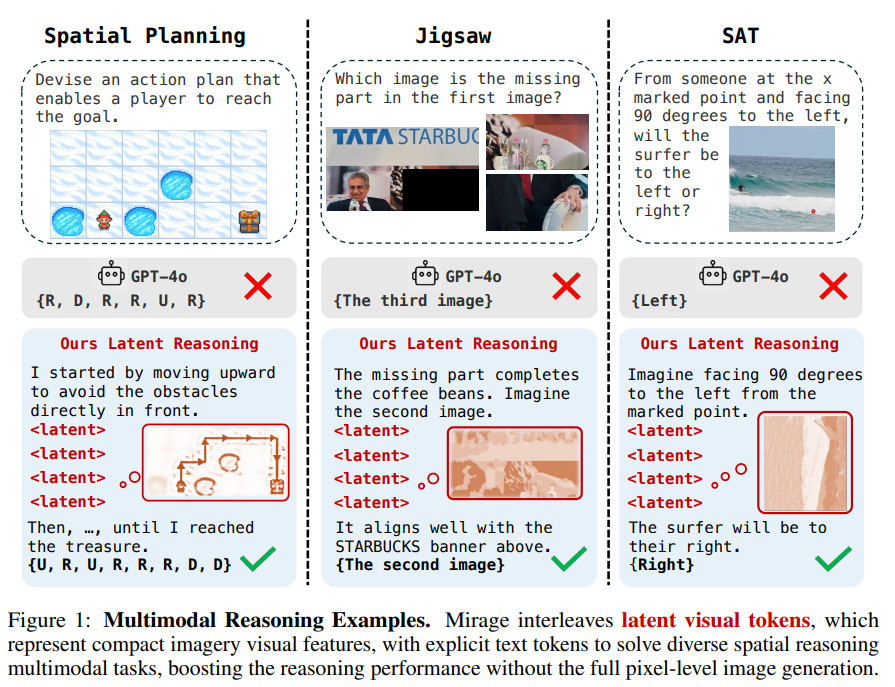
In conclusion, impressed by how people use psychological imagery to cause, the research introduces a light-weight method that lets VLMs suppose visually, with out ever producing precise photos. By interleaving compact visible cues with textual content throughout decoding, the mannequin learns to cause multimodally by means of a two-phase coaching course of: first, anchoring these cues to actual picture options, then permitting them to evolve freely to assist reasoning. A last reinforcement studying step sharpens efficiency. Examined on spatial reasoning duties, the tactic constantly outperforms conventional text-only fashions. Nevertheless, challenges stay in scaling to different duties and enhancing the standard of the artificial coaching knowledge.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this venture.
| Sponsorship Alternative |
|---|
| Attain probably the most influential AI builders worldwide. 1M+ month-to-month readers, 500K+ neighborhood builders, infinite potentialities. [Explore Sponsorship] |
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.

{kind=link}