: A Light-weight Pipeline that Delivers as much as 10x Reminiscence Financial savings and about 2.65x CPU Speedup")
Microsoft Analysis proposes BitNet Distillation, a pipeline that converts current full precision LLMs into 1.58 bit BitNet college students for particular duties, whereas conserving accuracy near the FP16 trainer and bettering CPU effectivity. The tactic combines SubLN based mostly architectural refinement, continued pre coaching, and twin sign distillation from logits and multi head consideration relations. Reported outcomes present as much as 10× reminiscence financial savings and about 2.65× sooner CPU inference, with process metrics akin to FP16 throughout a number of sizes.
What BitNet Distillation modifications?
The neighborhood already confirmed that BitNet b1.58 can match full precision high quality when skilled from scratch, however changing a pretrained FP16 mannequin on to 1.58 bit usually loses accuracy, and the hole grows as mannequin dimension will increase. BitNet Distillation targets this conversion drawback for sensible downstream deployment. It’s designed to protect accuracy whereas delivering CPU pleasant ternary weights with INT8 activations.
Stage 1: Modeling refinement with SubLN
Low bit fashions undergo from massive activation variance. The analysis group inserts SubLN normalization inside every Transformer block, particularly earlier than the output projection of the MHSA module and earlier than the output projection of the FFN. This stabilizes hidden state scales that circulation into quantized projections, which improves optimization and convergence as soon as weights are ternary. The coaching loss curves within the evaluation part assist this design.
Stage 2: Continued pre coaching to adapt weight distributions
Direct process effective tuning at 1.58 bit offers the scholar solely a small variety of process tokens, which isn’t sufficient to reshape the FP16 weight distribution for ternary constraints. BitNet Distillation performs a quick continued pre coaching on a normal corpus, the analysis group makes use of 10B tokens from the FALCON corpus, to push weights towards BitNet like distributions. The visualization exhibits the mass concentrating close to transition boundaries, which makes small gradients flip weights amongst [-1, 0, 1] throughout downstream process coaching. This improves studying capability with out a full pretraining run.
Stage 3: Distillation based mostly effective tuning with two alerts
The coed learns from the FP16 trainer utilizing logits distillation and multi head self consideration relation distillation. The logits path makes use of temperature softened KL between trainer and pupil token distributions. The eye path follows the MiniLM and MiniLMv2 formulations, which switch relations amongst Q, Ok, V with out requiring the identical variety of heads, and allow you to select a single layer to distill. Ablations present that combining each alerts works finest, and that deciding on one nicely chosen layer preserves flexibility.
Understanding the outcomes
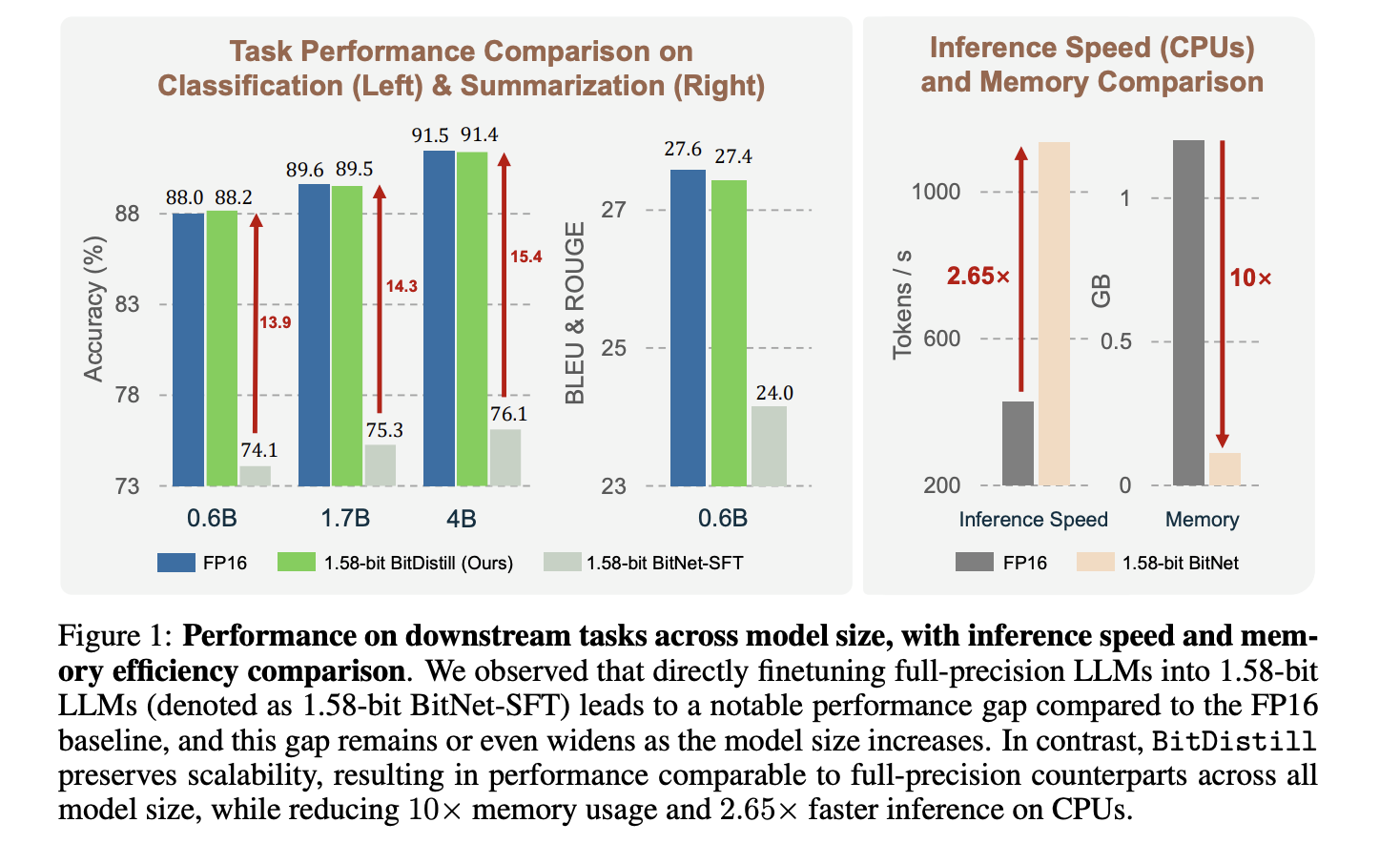
The analysis group evaluates classification, MNLI, QNLI, SST 2, and summarization on CNN/DailyMail dataset. It compares three settings, FP16 process effective tuning, direct 1.58 bit process effective tuning, and BitNet Distillation. Determine 1 exhibits that BitNet Distillation matches FP16 accuracy for Qwen3 backbones at 0.6B, 1.7B, 4B, whereas the direct 1.58 bit baseline lags extra as mannequin dimension grows. On CPU, tokens per second enhance by about 2.65×, and reminiscence drops by about 10× for the scholar. The analysis group quantizes activations to INT8 and makes use of the Straight Via Estimator for gradients via the quantizer.
The framework is appropriate with submit coaching quantization strategies equivalent to GPTQ and AWQ, which give further beneficial properties on prime of the pipeline. Distilling from a stronger trainer helps extra, which suggests pairing small 1.58 bit college students with bigger FP16 lecturers when accessible.
Key Takeaways
- BitNet Distillation is a 3 stage pipeline, SubLN insertion, continued pre coaching, and twin distillation from logits and multi head consideration relations.
- The analysis studies close to FP16 accuracy with about 10× decrease reminiscence and about 2.65× sooner CPU inference for 1.58 bit college students.
- The tactic transfers consideration relations utilizing MiniLM and MiniLMv2 type aims, which don’t require matching head counts.
- Evaluations cowl MNLI, QNLI, SST 2, and CNN/ DailyMail, and embody Qwen3 backbones at 0.6B, 1.7B, and 4B parameters.
- Deployment targets ternary weights with INT8 activations, with optimized CPU and GPU kernels accessible within the official BitNet repository.
BitNet Distillation is a practical step towards 1.58 bit deployment with out a full retrain, the three stage design, SubLN, continuous pre coaching, and MiniLM household consideration distillation, maps cleanly to identified failure modes in excessive quantization. The reported 10× reminiscence discount and about 2.65× CPU speedup at close to FP16 accuracy point out strong engineering worth for on premise and edge targets. The reliance on consideration relation distillation is nicely grounded in prior MiniLM work, which helps clarify the steadiness of outcomes. The presence of bitnet.cpp with optimized CPU and GPU kernels lowers integration danger for manufacturing groups.
Try the Technical Paper and GitHub Repo. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be part of us on telegram as nicely.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}