: A 32-Billion-Parameter Open-Weights LLM, to Advance Analysis on Code Technology with World Fashions")
Meta FAIR launched Code World Mannequin (CWM), a 32-billion-parameter dense decoder-only LLM that injects world modeling into code technology by coaching on execution traces and long-horizon agent–atmosphere interactions—not simply static supply textual content.
What’s new: studying code by predicting execution?
CWM mid-trains on two giant households of statement–motion trajectories: (1) Python interpreter traces that report native variable states after every executed line, and (2) agentic interactions inside Dockerized repositories that seize edits, shell instructions, and take a look at suggestions. This grounding is meant to show semantics (how state evolves) somewhat than solely syntax.
To scale assortment, the analysis workforce constructed executable repository pictures from 1000’s of GitHub initiatives and foraged multi-step trajectories by way of a software-engineering agent (“ForagerAgent”). The discharge experiences ~3M trajectories throughout ~10k pictures and three.15k repos, with mutate-fix and issue-fix variants.
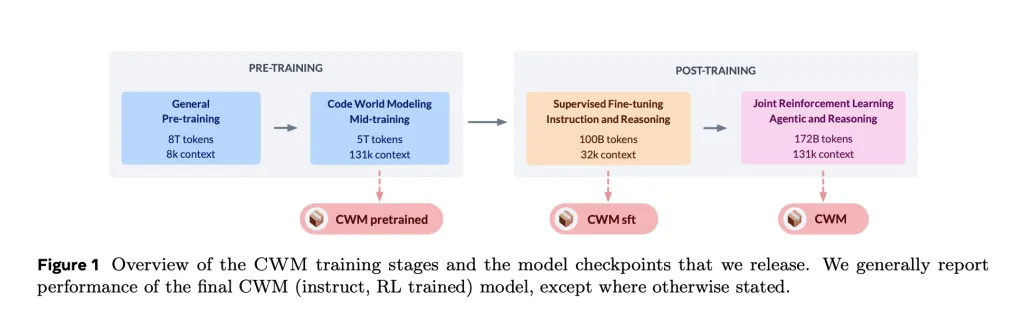
Mannequin and context window
CWM is a dense, decoder-only Transformer (no MoE) with 64 layers, GQA (48Q/8KV), SwiGLU, RMSNorm, and Scaled RoPE. Consideration alternates native 8k and international 131k sliding-window blocks, enabling 131k tokens efficient context; coaching makes use of document-causal masking.
Coaching recipe (pre → mid → submit)
- Normal pretraining: 8T tokens (code-heavy) at 8k context.
- Mid-training: +5T tokens, long-context (131k) with Python execution traces, ForagerAgent information, PR-derived diffs, IR/compilers, Triton kernels, and Lean math.
- Put up-training: 100B-token SFT for instruction + reasoning, then multi-task RL (~172B-token) throughout verifiable coding, math, and multi-turn SWE environments utilizing a GRPO-style algorithm and a minimal toolset (bash/edit/create/submit).
- Quantized inference suits on a single 80 GB H100.
Benchmarks
The analysis workforce cites the next go@1 / scores (test-time scaling famous the place relevant):
- SWE-bench Verified: 65.8% (with test-time scaling).
- LiveCodeBench-v5: 68.6%; LCB-v6: 63.5%.
- Math-500: 96.6%; AIME-24: 76.0%; AIME-25: 68.2%.
- CruxEval-Output: 94.3%.
The analysis workforce place CWM as aggressive with equally sized open-weights baselines and even with bigger or closed fashions on SWE-bench Verified.
For context on SWE-bench Verified’s process design and metrics, see the official benchmark assets.
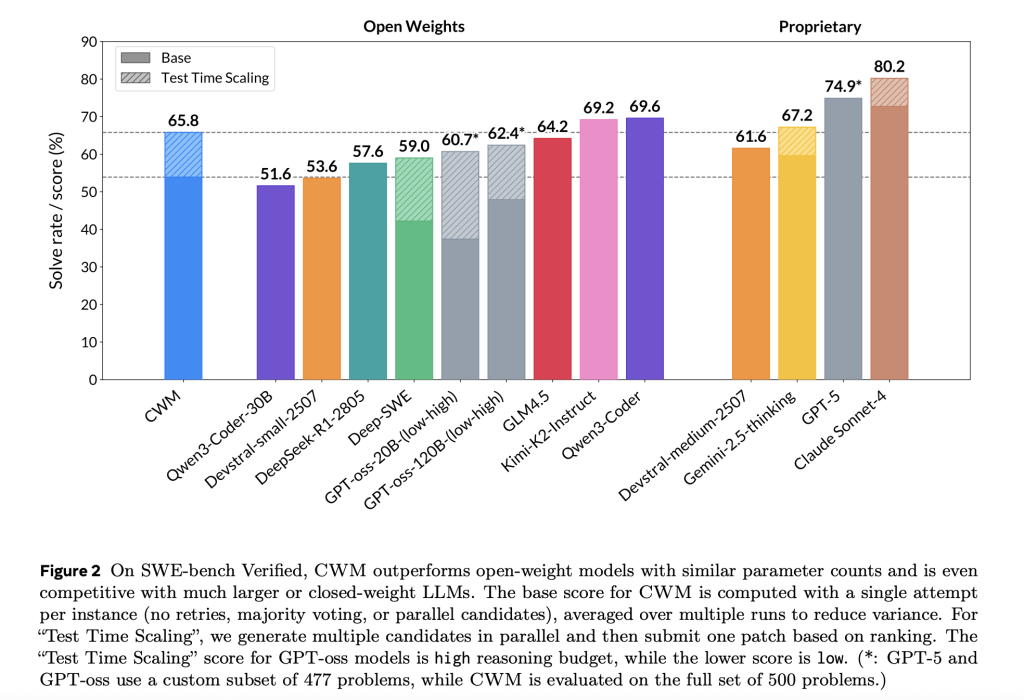
Why world modeling issues for code?
The discharge emphasizes two operational capabilities:
- Execution-trace prediction: given a perform and a hint begin, CWM predicts stack frames (locals) and the executed line at every step by way of a structured format—usable as a “neural debugger” for grounded reasoning with out dwell execution.
- Agentic coding: multi-turn reasoning with instrument use in opposition to actual repos, verified by hidden checks and patch similarity rewards; the setup trains the mannequin to localize faults and generate end-to-end patches (git diff) somewhat than snippets.
Some particulars value noting
- Tokenizer: Llama-3 household with reserved management tokens; reserved IDs are used to demarcate hint and reasoning segments throughout SFT.
- Consideration structure: the 3:1 native:international interleave is repeated throughout the depth; long-context coaching happens at giant token batch sizes to stabilize gradients.
- Compute scaling: learning-rate/batch measurement schedules are derived from inside scaling-law sweeps tailor-made for long-context overheads.
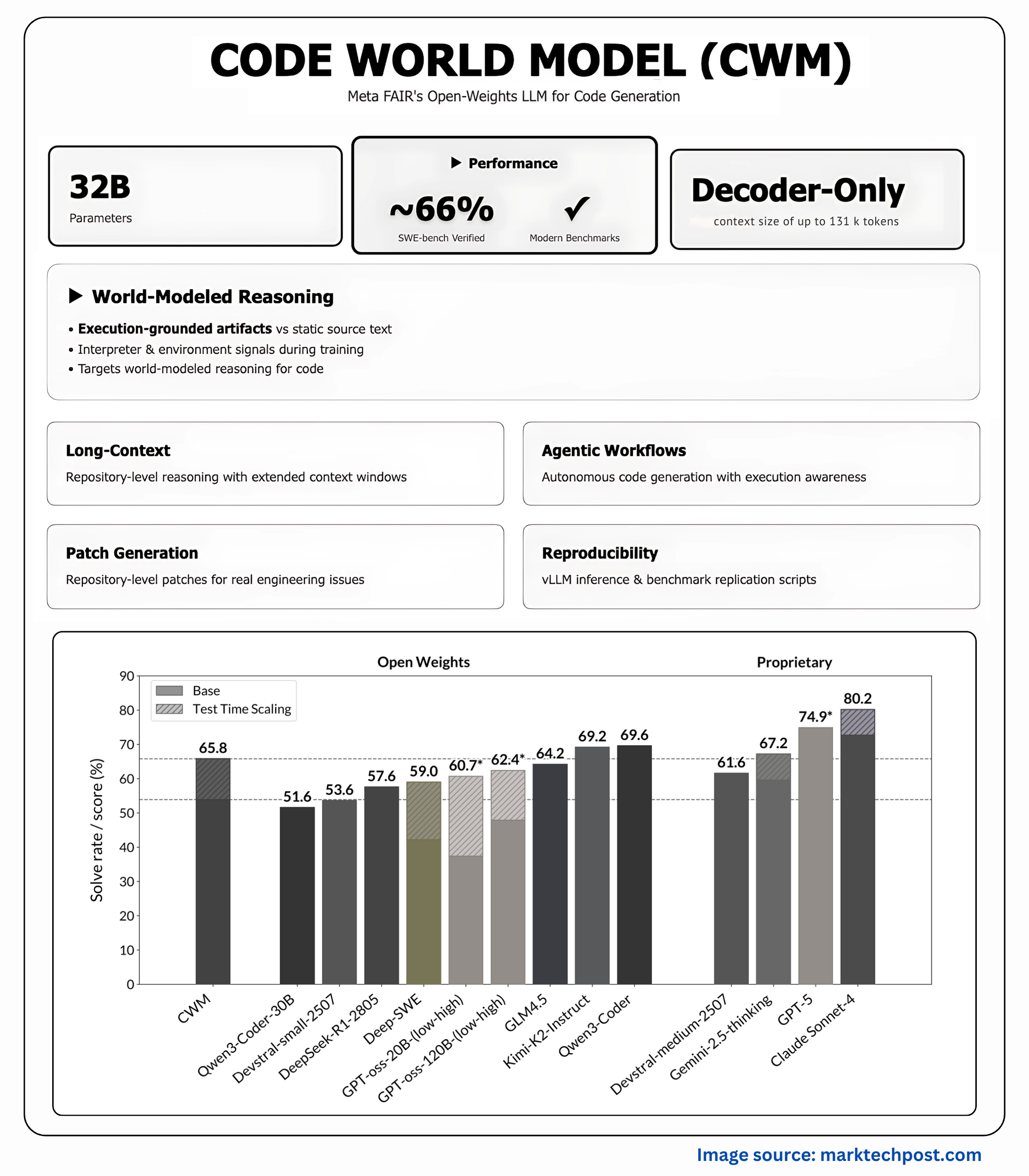
Abstract
CWM is a practical step towards grounded code technology: Meta ties a 32B dense transformer to execution-trace studying and agentic, test-verified patching, releases intermediate/post-trained checkpoints, and gates utilization underneath the FAIR Non-Industrial Analysis License—making it a helpful platform for reproducible ablations on long-context, execution-aware coding with out conflating analysis with manufacturing deployment.
Take a look at the Paper, GitHub Web page, and Mannequin on Hugging Face. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}