
Why was a brand new multilingual encoder wanted?
XLM-RoBERTa (XLM-R) has dominated multilingual NLP for greater than 5 years, an unusually lengthy reign in AI analysis. Whereas encoder-only fashions like BERT and RoBERTa have been central to early progress, most analysis vitality shifted towards decoder-based generative fashions. Encoders, nevertheless, stay extra environment friendly and sometimes outperform decoders on embedding, retrieval, and classification duties. Regardless of this, multilingual encoder growth stalled.
A staff of researchers from Johns Hopkins College suggest mmBERT that addresses this hole by delivering a contemporary encoder, surpassesing XLM-R and rivals latest large-scale fashions equivalent to OpenAI’s o3 and Google’s Gemini 2.5 Professional.
Understanding the structure of mmBERT
mmBERT is available in two primary configurations:
- Base mannequin: 22 transformer layers, 1152 hidden dimension, ~307M parameters (110M non-embedding).
- Small mannequin: ~140M parameters (42M non-embedding).
It adopts the Gemma 2 tokenizer with a 256k vocabulary, rotary place embeddings (RoPE), and FlashAttention2 for effectivity. Sequence size is prolonged from 1024 to 8192 tokens, utilizing unpadded embeddings and sliding-window consideration. This enables mmBERT to course of contexts almost an order of magnitude longer than XLM-R whereas sustaining sooner inference.
What coaching knowledge and phases have been used?
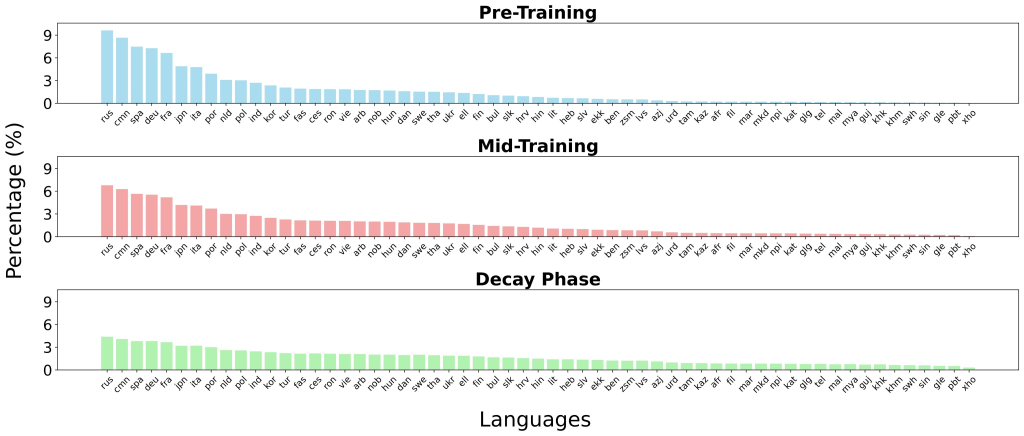
mmBERT was skilled on 3 trillion tokens spanning 1,833 languages. Information sources embrace FineWeb2, Dolma, MegaWika v2, ProLong, StarCoder, and others. English makes up solely ~10–34% of the corpus relying on the part.
Coaching was finished in three levels:
- Pre-training: 2.3T tokens throughout 60 languages and code.
- Mid-training: 600B tokens throughout 110 languages, targeted on higher-quality sources.
- Decay part: 100B tokens overlaying 1,833 languages, emphasizing low-resource adaptation.
What new coaching methods have been launched?
Three primary improvements drive mmBERT’s efficiency:
- Annealed Language Studying (ALL): Languages are launched step by step (60 → 110 → 1833). Sampling distributions are annealed from high-resource to uniform, guaranteeing low-resource languages acquire affect throughout later levels with out overfitting restricted knowledge.
- Inverse Masking Schedule: The masking ratio begins at 30% and decays to five%, encouraging coarse-grained studying early and fine-grained refinements later.
- Mannequin Merging Throughout Decay Variants: A number of decay-phase fashions (English-heavy, 110-language, and 1833-language) are mixed through TIES merging, leveraging complementary strengths with out retraining from scratch.
How does mmBERT carry out on benchmarks?
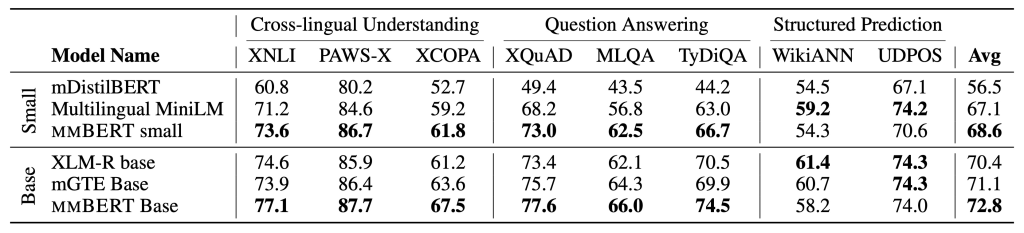
- English NLU (GLUE): mmBERT base achieves 86.3, surpassing XLM-R (83.3) and almost matching ModernBERT (87.4), regardless of allocating >75% of coaching to non-English knowledge.
- Multilingual NLU (XTREME): mmBERT base scores 72.8 vs. XLM-R’s 70.4, with features in classification and QA duties.
- Embedding duties (MTEB v2): mmBERT base ties ModernBERT in English (53.9 vs. 53.8) and leads in multilingual (54.1 vs. 52.4 for XLM-R).
- Code retrieval (CoIR): mmBERT outperforms XLM-R by ~9 factors, although EuroBERT stays stronger on proprietary knowledge.

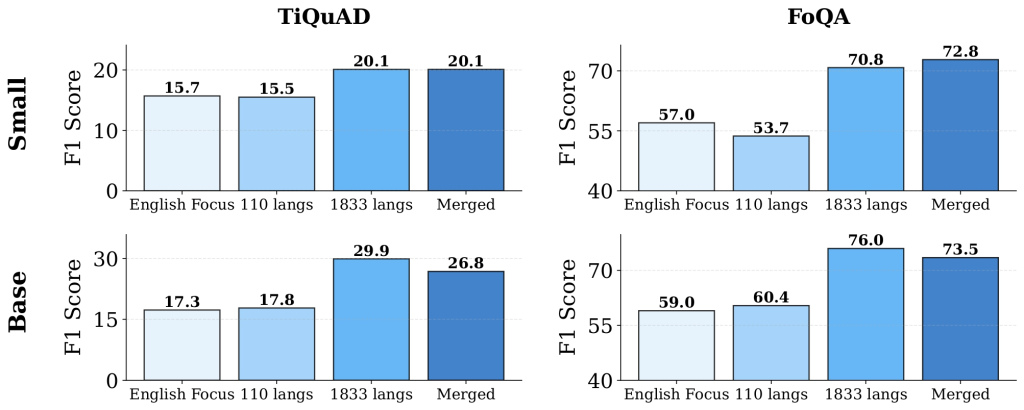
How does mmBERT deal with low-resource languages?
The annealed studying schedule ensures that low-resource languages profit throughout later coaching. On benchmarks like Faroese FoQA and Tigrinya TiQuAD, mmBERT considerably outperforms each o3 and Gemini 2.5 Professional. These outcomes show that encoder fashions, if skilled rigorously, can generalize successfully even in excessive low-resource situations.
What effectivity features does mmBERT obtain?
mmBERT is 2–4× sooner than XLM-R and MiniLM whereas supporting 8192-token inputs. Notably, it stays sooner at 8192 tokens than older encoders have been at 512 tokens. This pace increase derives from the ModernBERT coaching recipe, environment friendly consideration mechanisms, and optimized embeddings.
Abstract
mmBERT comes because the long-overdue substitute for XLM-R, redefining what a multilingual encoder can ship. It runs 2–4× sooner, handles sequences as much as 8K tokens, and outperforms prior fashions on each high-resource benchmarks and low-resource languages that have been underserved up to now. Its coaching recipe—3 trillion tokens paired with annealed language studying, inverse masking, and mannequin merging—reveals how cautious design can unlock broad generalization with out extreme redundancy. The result’s an open, environment friendly, and scalable encoder that not solely fills the six-year hole since XLM-R but in addition offers a strong basis for the following technology of multilingual NLP techniques.
Try the Paper, Mannequin on Hugging Face, GitHub and Technical particulars. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}