
As organizations scale their observability and analytics capabilities throughout a number of AWS Areas and environments, sustaining constant dashboards turns into more and more complicated. Groups usually spend hours manually recreating dashboards, creating workspaces, linking knowledge sources, and validating configurations throughout deployments—a repetitive and error-prone course of that slows down operational visibility.
The subsequent technology OpenSearch UI in Amazon OpenSearch Service introduces a unified, managed analytics expertise that decouples from particular person OpenSearch domains and OpenSearch collections. It supplies workspaces, devoted workforce areas with collaborator administration and a tailor-made setting for observability, search, and safety analytics use instances. Every workspace can hook up with a number of knowledge sources, together with OpenSearch Service domains, Amazon OpenSearch Serverless collections, and exterior sources similar to Amazon Easy Storage Service (Amazon S3). OpenSearch UI additionally helps entry with AWS IAM Identification Middle, AWS Identification and Entry Administration (IAM), Identification supplier (IdP)-initiated single sign-on (SAML utilizing IAM federation), and AI-powered insights.)-initiated single sign-on (SAML utilizing IAM federation),and AI-powered insights.
On this put up, you’ll discover ways to use the AWS Cloud Growth Equipment (AWS CDK) to deploy an OpenSearch UI software and combine it with an AWS Lambda perform that mechanically creates workspaces and dashboards utilizing the OpenSearch Dashboards Saved Objects APIs. Utilizing this automation implies that environments launch with ready-to-use analytics which can be standardized, version-controlled, and constant throughout deployments. which can be standardized, version-controlled, and constant throughout deployments.
Particularly, you’ll discover ways to:
- Deploy an OpenSearch UI software utilizing AWS CDK that in flip makes use of AWS CloudFormation
- Routinely create workspaces and dashboards utilizing a Lambda primarily based customized useful resource
- Generate and ingest pattern knowledge for fast visualization
- Construct visualizations programmatically utilizing the OpenSearch Dashboards Saved Objects API
- Authenticate API requests utilizing AWS Signature Model 4
All of the code samples on this put up can be found on this AWS Samples repository.
Resolution overview
The next structure demonstrates learn how to automate OpenSearch UI workspace and dashboard creation utilizing AWS CDK, AWS Lambda, and the OpenSearch UI APIs.
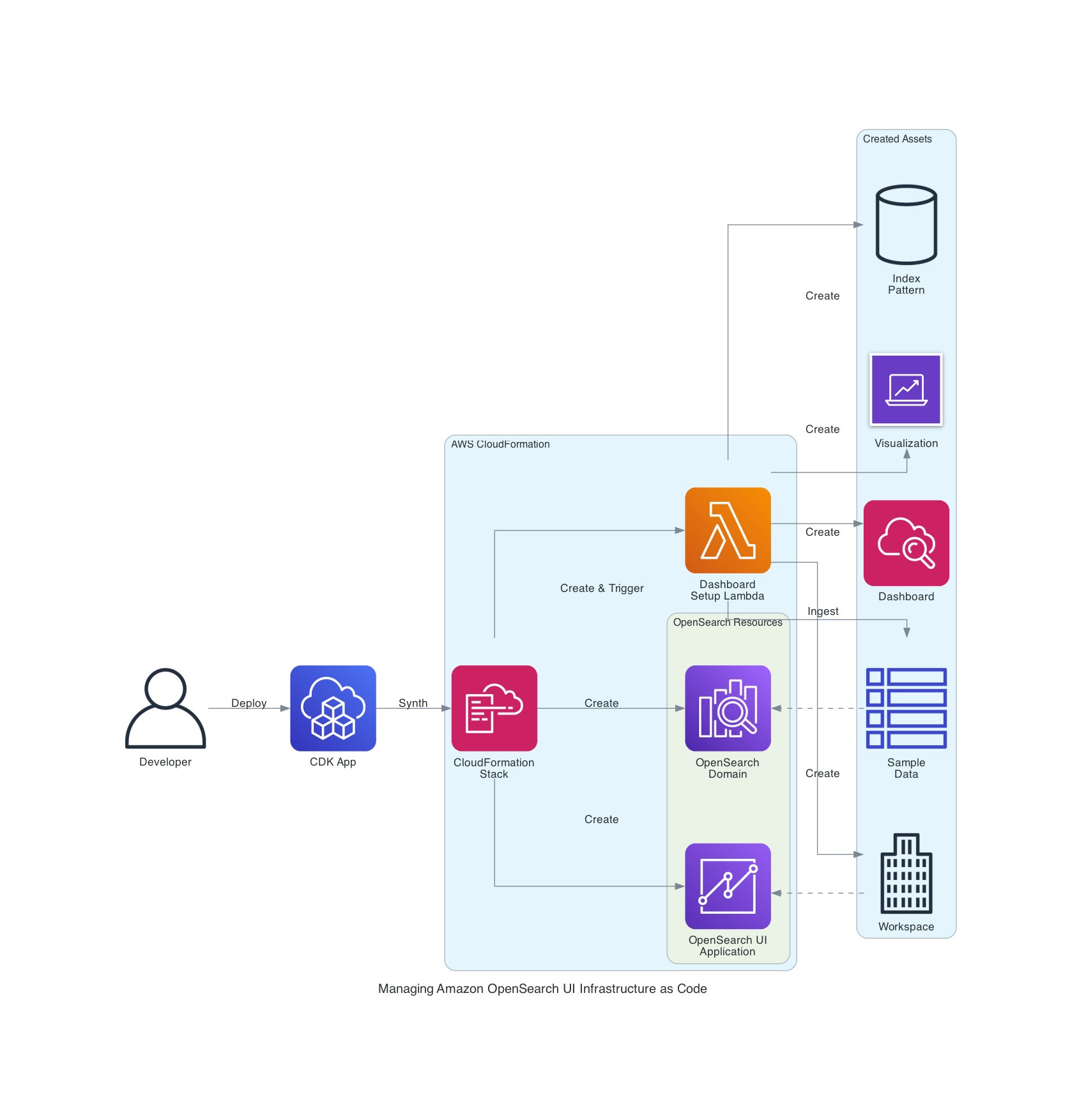
The workflow flows from left to proper:
- Deploy stack – Developer runs
cdk deployto launch the infrastructure and create the CloudFormation stack. - Create area – CloudFormation creates the OpenSearch area (which serves as the info supply)
- Create OpenSearch UI app – CloudFormation creates the OpenSearch UI software
- Set off Lambda – CloudFormation invokes the Lambda perform as a customized useful resource
- Generate and ingest knowledge – Lambda generates pattern metrics and ingests them into the area
- Create workspaces and belongings utilizing saved object API – Lambda creates the workspace, index sample, visualization (pie chart), and dashboard utilizing OpenSearch UI API calls
The result’s a totally configured OpenSearch UI with pattern knowledge and a ready-to-use dashboard automated by way of infrastructure as code (IaC). The identical workflow can be built-in into current infrastructure for OpenSearch UI functions to mechanically create or replace dashboards throughout future deployments, sustaining consistency throughout environments. consistency throughout environments.
Stipulations
To carry out the answer, you want the next conditions:
- An AWS person or position with adequate permissions – You’ll want permissions to create and handle AWS assets similar to OpenSearch Service domains, OpenSearch UI functions, Lambda features, IAM roles and insurance policies, digital non-public cloud (VPC) networking parts (subnets and safety teams), and CloudFormation stacks. For testing or proof-of-concept deployments, we advocate utilizing an administrative position. For manufacturing, comply with the precept of least privilege.
- Set up improvement instruments:
- Bootstrap CDK – This can be a one-time setup per account or Area:
This creates the mandatory S3 bucket and IAM roles for AWS CDK deployments in your account.
Get the pattern code
Clone the pattern implementation from GitHub:
The repository comprises:
This pattern demonstrates learn how to deploy an OpenSearch UI software, create a workspace, ingest pattern knowledge, and mechanically generate visualizations and dashboards utilizing IaC.
After cloning the repository, you possibly can deploy the stack to mechanically create your first OpenSearch workspace and dashboard with pattern knowledge.
Understanding the answer
Earlier than deploying, let’s study how the answer works. The next steps clarify the structure and automation logic that may execute mechanically once you deploy the AWS CDK stack. The subsequent part comprises the precise deployment instructions you’ll run.
Provision OpenSearch UI assets
The AWS CDK integrates seamlessly with AWS CloudFormation. This implies you possibly can outline your OpenSearch assets and automation workflows as IaC. On this answer, AWS CDK provisions the OpenSearch area, OpenSearch UI software, and a Lambda primarily based customized useful resource that performs the automation logic.
When deploying OpenSearch UI automation, the order of useful resource creation is essential to accurately resolve dependencies. The really helpful order is as follows:
- Create the Lambda execution position – Required for entry to AppConfigs and APIs
- Create the OpenSearch area – Serves as the first knowledge supply
- Create the OpenSearch UI software – References the Lambda position in its AppConfigs
- Create the Lambda perform – Defines the automation logic
- Create the customized useful resource – Triggers the Lambda automation throughout stack deployment
The next code snippet (from cdk/lib/dashboard-stack.ts) reveals the important thing infrastructure definitions:
These are some essential implementation notes:
- The Lambda position have to be created earlier than the OpenSearch UI software so its Amazon Useful resource Title (ARN) could be referenced in
dashboardAdmin.teams - The Lambda position consists of each
opensearch:ApplicationAccessAll(for OpenSearch UI API entry) andes:ESHttp*permissions (for ingesting knowledge into the OpenSearch area) - The customized useful resource permits the automation perform to run throughout deployment, passing each OpenSearch UI and OpenSearch area endpoints as parameters
Authenticate with OpenSearch UI APIs
When programmatically interacting with the OpenSearch UI (Dashboards) APIs, correct authentication is required so your Lambda perform or automation script can securely entry the APIs. The OpenSearch UI makes use of AWS Signature Model 4 (SigV4) authentication—just like the OpenSearch area APIs—however with a number of essential distinctions.
When signing OpenSearch UI API requests, the service identify have to be opensearch, not es. This can be a frequent supply of confusion: the OpenSearch area endpoint nonetheless makes use of the legacy service identify es, however the OpenSearch UI endpoints require opensearch. Utilizing the fallacious service identify will trigger your requests to fail authentication, even when the credentials are legitimate.
For POST, PUT, or DELETE requests, embrace the next headers to fulfill the OpenSearch UI API safety necessities:
| Header | Description | |
| 1 | Content material-Sort | Set to software/json for JSON payloads |
| 2 | osd-xsrf | Required for state-changing operations (set to true) |
| 3 | x-amz-content-sha256 | SHA-256 hash of the request physique to make sure knowledge integrity |
The SigV4 signing course of mechanically computes this physique hash when utilizing the botocore AWSRequest object, sustaining request integrity and stopping tampering throughout transmission.
The next code snippet (from lambda/sigv4_signer.py) demonstrates learn how to signal and ship a request to the OpenSearch UI API:
This utility perform indicators the request utilizing the right service identify (opensearch), attaches the required headers, and sends it securely to the OpenSearch UI endpoint.
Create workspace and dashboard with pattern knowledge
The Lambda perform (lambda/dashboard_automation.py) automates all the technique of provisioning a workspace, producing pattern knowledge, and creating visualizations and dashboards by way of the OpenSearch UI APIs. Go to the next lists of APIs:
Comply with these steps:
- Find or create a workspace. Every dashboard within the OpenSearch UI should exist inside a workspace. The perform first checks whether or not a workspace already exists and creates one if vital. The workspace associates a number of knowledge sources (for instance, an OpenSearch area or OpenSearch Serverless assortment):
This logic permits repeated deployments to stay idempotent; the Lambda perform reuses current workspaces slightly than creating duplicates.
- Generate and ingest pattern knowledge. To make the dashboards significant upon first launch, the Lambda perform generates a small dataset simulating HTTP request metrics and ingests it into the OpenSearch area utilizing the Bulk API:
The perform then ingests this knowledge into the area:
This permits every deployment to incorporate pattern analytics knowledge that instantly populates the dashboard upon first login.
- Create a visualization. After the index sample is out there, the Lambda perform creates a pie chart visualization that reveals HTTP standing code distribution:
This visualization will later be embedded inside a dashboard panel.
- Create the dashboard. Lastly, the Lambda perform creates a dashboard that references the visualization created within the earlier step:
This completes the dashboard creation course of, offering customers with an interactive visualization of software metrics as quickly as they entry the workspace.
The complete implementation, together with logging, error dealing with, and helper utilities, is out there within the AWS Samples GitHub repository.
Deploy the infrastructure with AWS CDK
With the AWS CDK stack and Lambda automation in place, you’re able to deploy the complete answer and confirm that your OpenSearch UI dashboard is created mechanically.
Deploy the stack
From the foundation listing of the cloned repository, navigate to the AWS CDK folder and deploy the stack utilizing your IAM person ARN from the Stipulations part:
The deployment course of usually takes 20–25 minutes as a result of AWS CDK provisions the OpenSearch area, OpenSearch UI software, Lambda perform, and customized useful resource that runs the automation.
Confirm the deployment
After the deployment completes:
- Open the OpenSearch UI endpoint displayed within the AWS CDK output.
- Check in utilizing your IAM credentials.
- Swap to the newly created
workspace-demoworkspace. - Open the Utility Metrics dashboard.
- View the pie chart visualization that shows the distribution of HTTP standing codes from the pattern knowledge.

The dashboard mechanically shows a pie chart visualization populated with artificial software metrics, demonstrating how the Saved Objects API can be utilized to bootstrap significant analytics dashboards instantly after deployment.
Enhancement 1: Simplify dashboard creation with Saved Object Import API
As your OpenSearch Dashboards evolve, managing complicated dependencies between index patterns, visualizations, and dashboards can turn out to be more and more tough. Every dashboard usually references a number of saved objects, and manually recreating or syncing them throughout environments could be time-consuming and error susceptible.
To simplify this course of, we advocate utilizing the Saved Objects Import/Export API. You should use this API to bundle total dashboards, together with their dependent objects, right into a single transferable artifact. By utilizing this strategy, you possibly can model, migrate, and deploy dashboards throughout environments as a part of your CI/CD workflow, sustaining consistency and lowering operational overhead.
Export your dashboard
You may export dashboards immediately from the OpenSearch UI or use saved object export API:
- Open Stack Administration after which Saved Objects
- Choose the dashboard and associated objects (for instance, visualizations and index patterns)
- Select Export
- Save the exported file as
dashboard.ndjson
This file comprises saved objects serialized in newline-delimited JSON (NDJSON) format, prepared for versioning or deployment automation.
Import dashboards programmatically
You may programmatically import the NDJSON file right into a goal workspace utilizing the Saved Objects import API:
By utilizing this strategy, you possibly can deal with dashboards as deployable belongings, precisely like software code. You may retailer your exported dashboards in supply management, combine them into your AWS CDK or CloudFormation pipelines, and mechanically deploy them to a number of environments with confidence.
Enhancement 2: Improved safety configurations
In some instances, you may need to enhance the safety configuration of your OpenSearch UI software, otherwise you may be coping with OpenSearch domains which have been deployed with extra safety configurations. On this part, we talk about how one can enhance the safety configuration of your OpenSearch UI software and nonetheless obtain IaC with AWS CDK. Extra particularly, we clarify how one can arrange your OpenSearch UI software when your OpenSearch area is in a VPC and when fine-grained entry management is enabled.
When the OpenSearch Area resides inside a VPC, extra configurations will likely be wanted to correctly join together with your dashboard.
Allow communication between Lambda features used to ingest knowledge and the OpenSearch area within the VPC
When the OpenSearch Service area resides in a VPC, the Lambda features that ingest knowledge into the area should have the ability to talk with it. Probably the most easy method of doing that is to permit the Lambda perform to be executed inside the identical VPC as your OpenSearch Service area and provides it the identical safety group. An instance is supplied within the GitHub repository.
- Enable HTTPS communications from purchasers making an attempt to speak together with your OpenSearch Service area. On this instance, the consumer will likely be utilizing the identical safety group used within the OpenSearch Service area:
- Add this managed coverage to the position assumed by the Lambda perform to permit it entry to the VPC:
- Specify the VPC and the safety group your Lambda perform will likely be utilizing. On this case, the VPC is identical one utilized by your OpenSearch Service area:
Authorize OpenSearch UI service for VPC endpoint entry
For the OpenSearch Service area to be accessible to your dashboard, VPC endpoint entry have to be enabled. This may be achieved through the use of a customized useful resource, as proven within the following configuration:
Allow fine-grained entry management
While you use fine-grained entry management together with an OpenSearch UI, you might have extra management over which operations are allowed for every person. This may be particularly helpful once you need to restrict your customers’ actions past the admin, learn, or write permissions that include OpenSearch UI. Distinctive roles could be created and mapped to a number of customers to attain exact management over who can entry what performance.
Within the earlier sections, the identical Lambda was used to make requests to each the OpenSearch Service area and the OpenSearch UI. Nevertheless, in conditions the place the principle position isn’t the identical between the OpenSearch Service area and the OpenSearch UI, we advocate making a Lambda perform for every position. Once more, when deploying OpenSearch UI automation, the order of useful resource creation is essential to accurately resolve dependencies. As illustrated beforehand, the really helpful order is as follows:
- Create the dashboard Lambda execution position – Required for entry to AppConfigs and APIs
- Create the OpenSearch area primary position – Required for area creation and APIs
- Create the OpenSearch area – Serves as the first knowledge supply
- Create the OpenSearch area Lambda perform – Defines the automation logic for the OpenSearch area
- Create the OpenSearch area customized assets – Triggers the Lambda automation throughout stack deployment
- Create the OpenSearch UI software – References the Lambda position in its AppConfigs
- Create the OpenSearch UI Lambda perform – Defines the automation logic for the OpenSearch UI
- Create the OpenSearch UI customized useful resource – Triggers the Lambda automation throughout stack deployment
When creating the OpenSearch Service area, specify the fine-grained entry management parameter, as follows:
The Lambda perform answerable for speaking with the OpenSearch Service area ought to have the mandatory permissions to write down to it. The next is a configuration instance the place the Lambda perform assumes the area’s primary position:
Then, add the customized assets to create the roles and position mappings, as wanted:
Create extra roles within the OpenSearch Service area (Non-compulsory)
If you wish to grant particular permissions to some customers, we advocate creating roles for them. This may be achieved by making the next requests to the OpenSearch Service area endpoint.
For extra details about the roles endpoint, evaluation the Create position within the OpenSearch documentation.
Create position mappings within the OpenSearch area to your dashboard customers (Non-compulsory)
Customers could be mapped to a number of roles to regulate their entry to the OpenSearch Service area, which will likely be mirrored within the OpenSearch UI dashboard related to the area.
For extra details about the rolesmapping endpoint, evaluation the Create position mapping within the OpenSearch documentation.
These are some essential implementation notes:
- By default, the OpenSearch Area will create a task mapping for its primary person, beneath
all_accessandsecurity_manager. In case you modify these mappings, we advocate preserving the principle person within the record to forestall unintended lack of entry. - When fine-grained entry management is used, if a person opens the OpenSearch UI with out being mapped to a task within the OpenSearch Area, they are going to be unable to visualise or modify the info positioned within the OpenSearch Area, even when they’re a part of the OpenSearch UI’s admin group. For that reason, we advocate creating customized assets so as to add the suitable position mappings. OpenSearch UI admins will nonetheless have the ability to make modifications to the OpenSearch UI dashboards.
- When programmatically interacting with the OpenSearch Area APIs, correct authentication is required so your Lambda perform or automation script can securely entry the APIs. The OpenSearch Area makes use of SigV4 authentication. When signing the OpenSearch Area API requests, the service identify have to be
es.
Value issues
This answer makes use of a number of AWS providers, every with its personal value part:
- Amazon OpenSearch Service – That is the principle value driver. Costs are primarily based on occasion sort, variety of nodes, and Amazon Elastic Block Retailer (Amazon EBS) storage. For testing, you should utilize a smaller occasion (for instance,
t3.small.search) or delete the area after use to attenuate value.) or delete the area after use to attenuate value. - AWS Lambda – The automation perform runs solely throughout deployment and incurs minimal prices for a number of quick invocations.
- AWS CDK and CloudFormation – Create short-term IAM roles and Amazon S3 deployment belongings with negligible value.
For pricing particulars, check with Amazon OpenSearch Service Pricing.
Clear Up
To keep away from incurring ongoing prices, clear up the assets created by this answer once you’ve accomplished your testing.Open your mission listing and destroy the AWS CDK stack:
This command removes the assets provisioned by the AWS CDK stack, together with:
- The Amazon OpenSearch Service area
- The OpenSearch UI software
- The AWS Lambda perform and customized useful resource
- IAM roles and insurance policies related to the deployment
By cleansing up, you cease the associated prices and keep a tidy, cost-efficient AWS setting.
Extra assets
Conclusion
By integrating the Saved Objects API with the next-generation Amazon OpenSearch UI, you possibly can programmatically create total analytics experiences—together with workspaces, pattern knowledge, visualizations, and dashboards—immediately out of your IaC.
This strategy brings the ability of IaC to your analytics layer. Utilizing AWS CDK and AWS Lambda, you possibly can model, deploy, and replace dashboards constantly throughout environments, lowering guide setup whereas bettering reliability and governance. With this automation in place, your groups can give attention to insights slightly than setup—delivering observability-as-code that scales together with your group.
Concerning the authors

{kind=link}