
Liquid AI mentioned that with its basis fashions, it hopes to attain the optimum stability between high quality, latency, and reminiscence for particular duties and {hardware} necessities. | Supply: Liquid AI
This week, Liquid AI launched LFM2, a Liquid Basis Mannequin (LFM) that the corporate mentioned units a brand new customary in high quality, pace, and reminiscence effectivity deployment.
Shifting massive generative fashions from distant clouds to lean, on‑gadget LLMs unlocks millisecond latency, offline resilience, and knowledge‑sovereign privateness. These are capabilities important for telephones, laptops, automobiles, robots, wearables, satellites, and different endpoints that should purpose in actual time.
Liquid AI designed the mannequin to offer a quick on-device gen-AI expertise throughout the business, unlocking a large variety of gadgets for generative AI workloads. Constructed on a brand new hybrid structure, LFM2 delivers twice as quick decode and prefill efficiency as Qwen3 on CPU. It additionally considerably outperforms fashions in every dimension class, making them best for powering environment friendly AI brokers, the corporate mentioned.
The Cambridge, Mass.-based firm mentioned these efficiency positive aspects make LFM2 the perfect alternative for native and edge use instances. Past deployment advantages, its new structure and coaching infrastructure ship a thrice enchancment in coaching effectivity over the earlier LFM era.
Liquid AI co-founder and director of MIT’s Pc Science and Synthetic Intelligence Laboratory (CSAIL) Daniela Rus delivered a keynote on the Robotics Summit & Expo 2025, a robotics growth occasion produced by The Robotic Report.
LFM2 fashions can be found right this moment on Hugging Face. Liquid AI is releasing them underneath an open license, which relies on Apache 2.0. The license permits customers to freely use LFM2 fashions for educational and analysis functions. Corporations may also use the fashions commercially in the event that they’re smaller (underneath $10m income).
Liquid AI presents small multimodal basis fashions with a safe enterprise-grade deployment stack that turns each gadget into an AI gadget, domestically. This, it mentioned, offers it the chance to acquire an outsized share in the marketplace as enterprises pivot from cloud LLMs to cost-efficient, quick, personal, and on‑prem intelligence.
What can LFM2 do?
Liquid AI mentioned LFM2 achieves thrice quicker coaching in comparison with its earlier era. It additionally advantages from as much as two occasions quicker decode and prefill pace on CPU in comparison with Qwen3. Moreover, the corporate claimed LFM2 outperforms similarly-sized fashions throughout a number of benchmark classes, together with data, arithmetic, instruction following, and multilingual capabilities.
LFM2 is provided with a brand new structure. It’s a hybrid Liquid mannequin with multiplicative gates and quick convolutions. It consists of 16 blocks: 10 double-gated short-range convolution blocks and 6 blocks of grouped question consideration.
Whether or not it’s deployed on smartphones, laptops, or automobiles, LFM2 runs effectively on CPU, GPU, and NPU {hardware}. The corporate’s full-stack system consists of structure, optimization, and deployment engines to speed up the trail from prototype to product.
Liquid AI is releasing the weights of three dense checkpoints with 0.35B, 0.7B, and 1.2B parameters. Customers can strive them now on the Liquid Playground, Hugging Face, and OpenRouter.
How does LFM2 carry out in opposition to different fashions?
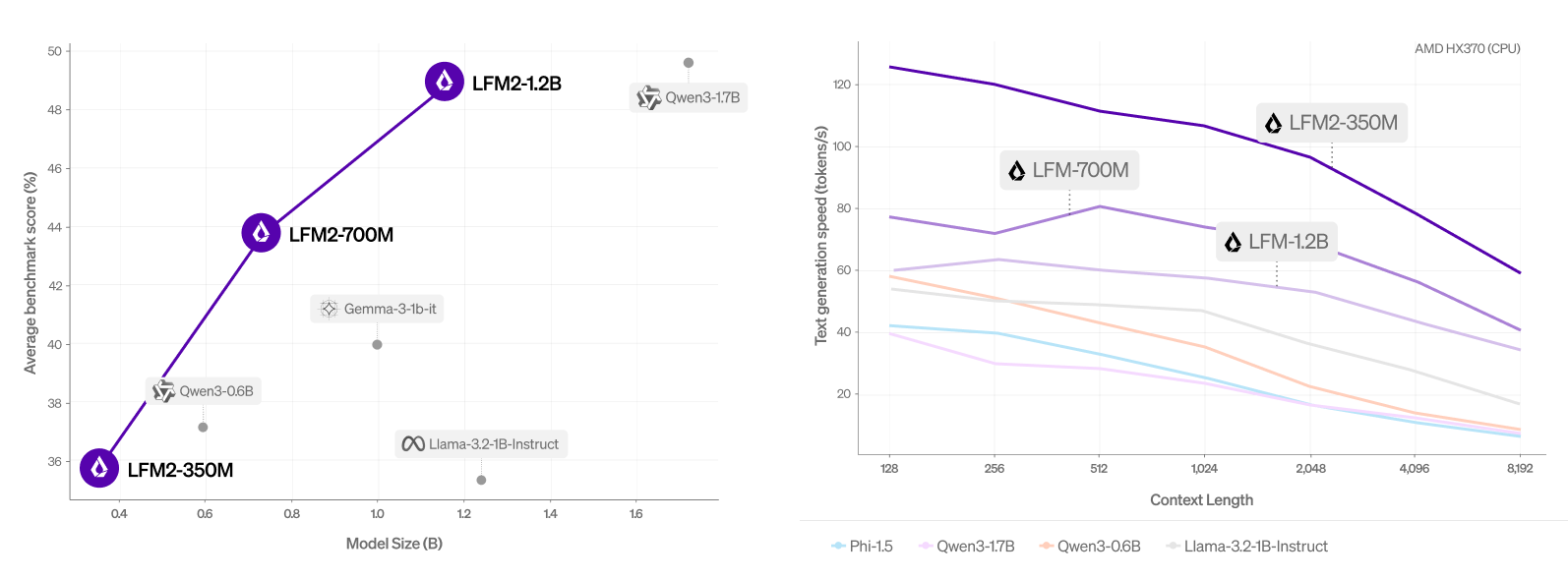
Common rating (MMLU, IFEval, IFBENCH, GSM8K, MMMLU) vs. mannequin dimension. | Supply: Liquid AI
The corporate evaluated LFM2 utilizing automated benchmarks and an LLM-as-a-Decide framework to acquire a complete overview of its capabilities. It discovered that the mannequin outperforms similar-sized fashions throughout totally different analysis classes.
Liquid AI additionally evaluated LFM2 throughout seven widespread benchmarks overlaying data (5-shot MMLU, 0-shot GPQA), instruction following (IFEval, IFBench), arithmetic (0-shot GSM8K, 5-shot MGSM), and multilingualism (5-shot OpenAI MMMLU, 5-shot MGSM once more) with seven languages (Arabic, French, German, Spanish, Japanese, Korean, and Chinese language).
It discovered that LFM2-1.2B performs competitively with Qwen3-1.7B, a mannequin with a 47% greater parameter rely. LFM2-700M outperforms Gemma 3 1B IT, and its tiniest checkpoint, LFM2-350M, is aggressive with Qwen3-0.6B and Llama 3.2 1B Instruct.
How Liquid AI skilled LFM2
To coach and scale-up LFM2, the corporate chosen three mannequin sizes (350M, 700M, and 1.2B parameters) concentrating on low-latency on-device language mannequin workloads. All fashions have been skilled on 10T tokens drawn from a pre-training corpus comprising roughly 75% English, 20% multilingual, and 5% code knowledge sourced from the net and licensed supplies.
For the multilingual capabilities of LFM2 the corporate primarily centered on Japanese, Arabic, Korean, Spanish, French, and German languages.
Throughout pre-training, Liquid AI leveraged its present LFM1-7B as a trainer mannequin in a data distillation framework. The corporate used the cross-entropy between LFM2’s pupil outputs and the LFM1-7B trainer outputs as the first coaching sign all through the complete 10T token coaching course of. The context size was prolonged throughout pretraining to 32k.
Put up-training began with a really large-scale Supervised Superb-Tuning (SFT) stage on a various knowledge combination to unlock generalist capabilities. For these small fashions, the corporate discovered it useful to instantly prepare on a consultant set of downstream duties, reminiscent of RAG or operate calling. The dataset is comprised of open-source, licensed, in addition to focused artificial knowledge, the place the corporate ensures prime quality by way of a mixture of quantitative pattern scoring and qualitative heuristics.
Liquid AI additional applies a customized Direct Desire Optimization algorithm with size normalization on a mixture of offline knowledge and semi-online knowledge. The semi-online dataset is generated by sampling a number of completions from its mannequin, primarily based on a seed SFT dataset.
The corporate then scores all responses with LLM judges and creates desire pairs by combining the very best and lowest scored completions among the many SFT and on-policy samples. Each the offline and semi-online datasets are additional filtered primarily based on a rating threshold. Liquid AI creates a number of candidate checkpoints by various the hyperparameters and dataset mixtures. Lastly, it combines a choice of its greatest checkpoints right into a remaining mannequin by way of totally different mannequin merging methods.

{kind=link}