
Liquid AI has formally launched LFM2-VL, a brand new household of vision-language basis fashions optimized for low-latency, on-device deployment. With two extremely environment friendly variants—LFM2-VL-450M and LFM2-VL-1.6B—this launch marks a big leap in bringing multimodal AI to smartphones, laptops, wearables, and embedded methods with out compromising pace or accuracy.
Unprecedented Pace and Effectivity
LFM2-VL fashions are engineered to ship as much as 2× sooner GPU inference in comparison with current vision-language fashions, whereas sustaining aggressive benchmark efficiency on duties like picture description, visible query answering, and multimodal reasoning. The 450M-parameter variant is tailor-made for extremely resource-constrained environments, whereas the 1.6B-parameter model provides larger functionality whereas nonetheless remaining light-weight sufficient for single-GPU or high-end cell use.
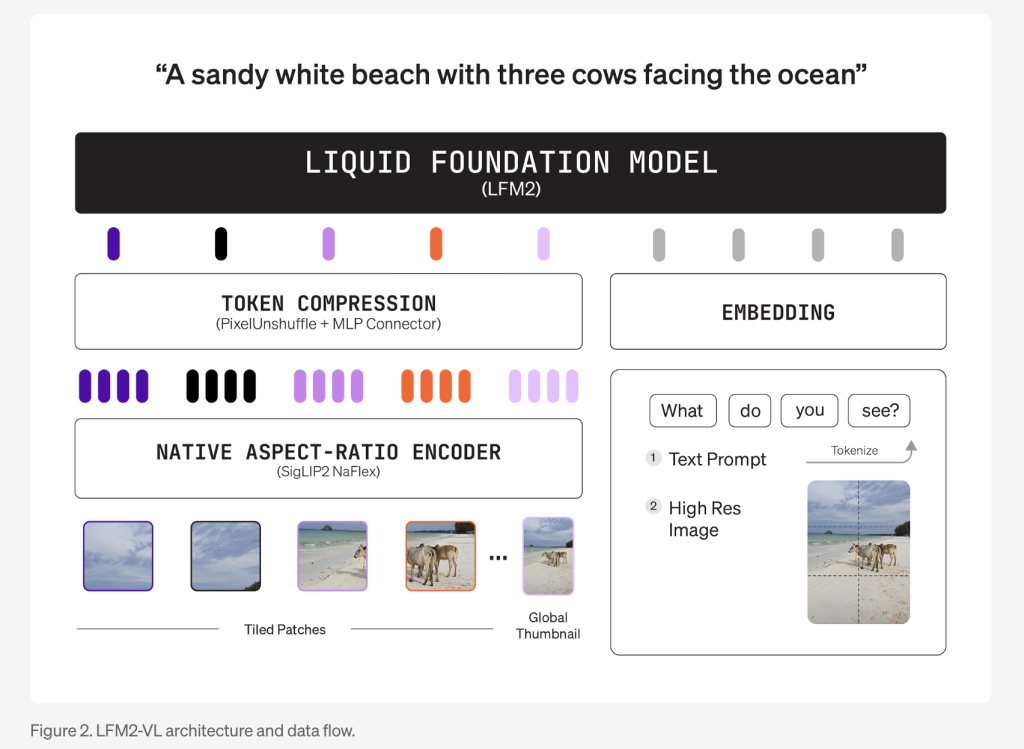
Technical Improvements
- Modular Structure: LFM2-VL combines a language mannequin spine (LFM2-1.2B or LFM2-350M), a SigLIP2 NaFlex imaginative and prescient encoder (400M or 86M parameters), and a multimodal projector with a “pixel unshuffle” approach that dynamically reduces picture token counts for sooner processing.
- Native Decision Dealing with: Pictures are processed at their native decision as much as 512×512 pixels with out distortion from upscaling. Bigger photos are cut up into non-overlapping 512×512 patches, preserving element and side ratio. The 1.6B mannequin additionally encodes a downscaled thumbnail of the total picture for international context understanding.
- Versatile Inference: Customers can tune the speed-quality tradeoff at inference time by adjusting most picture tokens and patch rely, permitting real-time adaptation to machine capabilities and software wants.
- Coaching: The fashions had been first pre-trained on the LFM2 spine, then collectively mid-trained to fuse imaginative and prescient and language capabilities utilizing a progressive adjustment of text-to-image information ratios, and at last fine-tuned for picture understanding on roughly 100 billion multimodal tokens.
Benchmark Efficiency
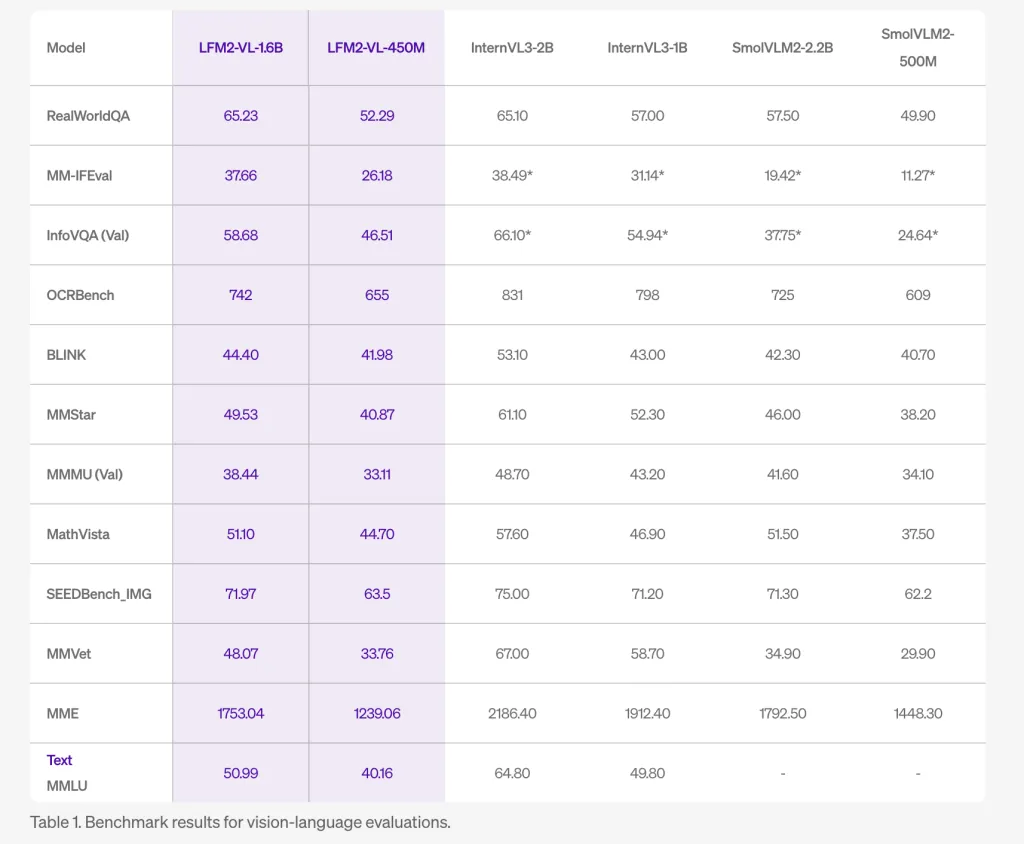
LFM2-VL delivers aggressive outcomes on public benchmarks comparable to RealWorldQA, MM-IFEval, and OCRBench, rivaling bigger fashions like InternVL3 and SmolVLM2, however with a smaller reminiscence footprint and far sooner processing—making it ultimate for edge and cell functions.
Each mannequin sizes are open-weight and downloadable on Hugging Face beneath an Apache 2.0-based license, allowing free use for analysis and business use by firms. Bigger enterprises should contact Liquid AI for a business license. The fashions combine seamlessly with Hugging Face Transformers and assist quantization for additional effectivity positive aspects on edge {hardware}.
Use Instances and Integration
LFM2-VL is designed for builders and enterprises in search of to deploy quick, correct, and environment friendly multimodal AI instantly on gadgets—lowering cloud dependency and enabling new functions in robotics, IoT, sensible cameras, cell assistants, and extra. Instance functions embrace real-time picture captioning, visible search, and interactive multimodal chatbots.
Getting Began
- Obtain: Each fashions can be found now on the Liquid AI Hugging Face assortment.
- Run: Instance inference code is supplied for platforms like llama.cpp, supporting numerous quantization ranges for optimum efficiency on totally different {hardware}.
- Customise: The structure helps integration with Liquid AI’s LEAP platform for additional customization and multi-platform edge deployment.
In abstract, Liquid AI’s LFM2-VL units a brand new normal for environment friendly, open-weight vision-language fashions on the sting. With native decision assist, tunable speed-quality tradeoffs, and a deal with real-world deployment, it empowers builders to construct the following era of AI-powered functions—anyplace, on any machine.
Try the Technical Particulars and Fashions on Hugging Face. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}