
When you’ve been watching the open-source LLM area, you already comprehend it has become a full-blown race. Each few months, a brand new mannequin comes out claiming to push the boundary and a few genuinely do. Chinese language labs particularly have been transferring quick, with fashions like GLM 4.6, Kimi K2 Considering, Qwen 3 Subsequent, ERNIE-4.5-VL and extra. So when DeepSeek dropped V3.2, the apparent query wasn’t “Is that this the brand new king?” The actual query was:
Does this replace really transfer the open-source world ahead, or is it simply one other mannequin within the combine?
To reply that, let’s stroll via the story behind V3.2, what modified, and why individuals are paying consideration.
What’s DeepSeek V3.2?
DeepSeek V3.2 is an upgraded model of DeepSeek-V3.2-Exp which was launched again in October. It’s designed to push reasoning, long-context understanding, and agent workflows additional than earlier variations. Not like many open fashions that merely scale parameters, V3.2 introduces architectural adjustments and a a lot heavier reinforcement-learning part to enhance how the mannequin thinks, not simply what it outputs.
DeepSeek additionally launched two variants:
- V3.2 (Commonplace): The sensible, deployment-friendly model appropriate for chat, coding, instruments, and on a regular basis workloads.
- V3.2 Speciale: A high-compute, reasoning-maximized model that produces longer chains of thought and excels at Olympiad-level math and aggressive programming.
Efficiency and Benchmarks for DeepSeek V3.2
DeepSeek V3.2 comes with among the strongest benchmark outcomes we’ve seen from an open-source mode.
- In math-heavy assessments like AIME 2025 and HMMT 2025, the Speciale variant scores 96% and 99.2%, matching or surpassing fashions like GPT-5 Excessive and Claude 4.5.
- Its Codeforces score of 2701 locations it firmly in competitive-programmer territory, whereas the Considering variant nonetheless delivers a strong 2386.
- On agentic duties, DeepSeek holds its personal with 73% on SWE Verified and 80 % on the τ² Bench, even when prime closed fashions edge forward in just a few classes.
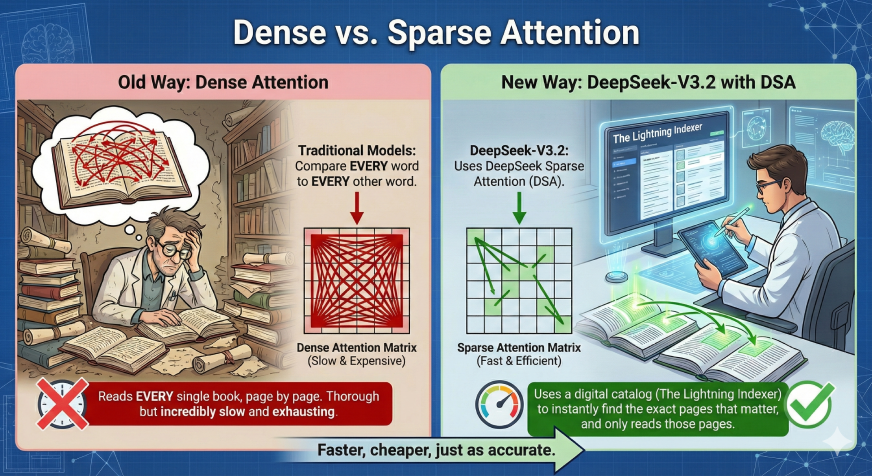
The Massive Concept: Smarter “Skimming”
Strongest AI fashions endure from a typical downside: because the doc will get longer, the mannequin will get a lot slower and dearer to run. It is because conventional fashions attempt to evaluate each single phrase to each different phrase to grasp context.
DeepSeek-V3.2 solves this by introducing a brand new methodology known as DeepSeek Sparse Consideration (DSA). Consider it like a researcher in a library:
- Outdated Approach (Dense Consideration): The researcher reads each single e-book on the shelf, web page by web page, simply to reply one query. It’s thorough however extremely gradual and exhausting.
- New Approach (DeepSeek-V3.2): The researcher makes use of a digital catalog (The Lightning Indexer) to immediately discover the precise pages that matter, and solely reads these pages. It’s simply as correct, however a lot sooner.
DeepSeek V3.2 Structure
The core innovation is DSA (DeepSeek Sparse Consideration), which has two primary steps:
1. The Lightning Indexer (The Scout)
Earlier than the AI tries to grasp the textual content, a light-weight, super-fast software known as the “Lightning Indexer” scans the content material. It provides every bit of data a “relevance rating.” It asks: “Is that this piece of information helpful for what we’re doing proper now?”
2. The High-k Selector (The Filter)
As an alternative of feeding the whole lot into the AI’s mind, the system picks solely the “High-k” (the very best scoring) items of data. The AI ignores the irrelevant fluff and focuses its computing energy strictly on the info that issues.
Does It Really Work?
You may fear that “skimming” makes the AI non-accurate. Based on the info, it doesn’t.
- Similar Intelligence: DeepSeek-V3.2 performs simply in addition to its predecessor (DeepSeek-V3.1-Terminus) on commonplace assessments and human choice charts (ChatbotArena).
- Higher at Lengthy Duties: Surprisingly, it really scored greater on some reasoning duties involving very lengthy paperwork.
- Coaching: It was taught to do that by first watching the older, slower mannequin work (Dense Heat-up) after which training by itself to choose the fitting data (Sparse Coaching).
What This Means for Customers?
Right here is the “What can it do for others” worth proposition:
- Large Pace Enhance: As a result of the mannequin isn’t bogging itself down processing irrelevant phrases, it runs considerably sooner, particularly when coping with lengthy paperwork (like authorized contracts or books).
- Decrease Value: It requires much less computing energy (GPU hours) to get the identical end result. This makes high-end AI extra inexpensive to run.
- Lengthy-Context Mastery: Customers can feed it huge quantities of knowledge (as much as 128,000 tokens) with out the system slowing to a crawl or crashing, making it excellent for analyzing large datasets or lengthy tales.
DeepSeek now retains its inner reasoning context whereas utilizing instruments fairly than restarting its thought course of after each step, which makes finishing advanced duties considerably sooner and extra environment friendly.
- Beforehand, each time the AI used a software (like working code), it forgot its plan and needed to “re-think” the issue from scratch. This was gradual and wasteful.
- Now, the AI retains its thought course of lively whereas it makes use of instruments. It remembers why it’s doing a process and doesn’t have to start out over after each step.
- It solely clears its “ideas” when you ship a brand new message. Till then, it stays targeted on the present job.
Consequence: The mannequin is quicker and cheaper as a result of it doesn’t waste power enthusiastic about the identical factor twice.
Word: This works finest when the system separates “software outputs” from “person messages.” In case your software program treats software outcomes as person chat, this characteristic gained’t work.
You possibly can learn extra about DeepSeek V3.2 right here. Let’s see how the mannequin performs within the part given beneath:
Job 1: Create a Sport
Create a cute and interactive UI for a “Guess the Phrase” sport the place the participant is aware of a secret phrase and gives 3 quick clues (max 10 letters every). The AI then has 3 makes an attempt to guess the phrase. If the AI guesses accurately, it wins; in any other case, the participant wins.
My Take:
DeepSeek created an intuitive sport with all of the requested options. I discovered this implementation to be glorious, delivering a elegant and fascinating expertise that met all necessities completely.
Job 2: Planning
I must plan a 7-day journey to Kyoto, Japan, for mid-November. The itinerary ought to deal with conventional tradition, together with temples, gardens, and tea ceremonies. Discover one of the best time to see the autumn leaves, an inventory of three must-visit temples for ‘Momiji’ (autumn leaves), and a highly-rated conventional tea home with English-friendly providers. Additionally, discover a well-reviewed ryokan (conventional Japanese inn) within the Gion district. Manage all the knowledge into a transparent, day-by-day itinerary.
Output:

Discover full output right here.
My Take:
The V3.2 response is glorious for a traveler who desires a transparent, actionable, and well-paced plan. Its formatting, logical geographic stream, and built-in sensible recommendation make it prepared to make use of virtually straight out of the field. It demonstrates robust synthesis of data right into a compelling narrative.
Additionally Learn: DeepSeek Math V2 Information: Smarter AI for Actual Math
Conclusion
DeepSeek V3.2 isn’t making an attempt to win by measurement, it wins by considering smarter. With Sparse Consideration, decrease prices, long-context power, and higher tool-use reasoning, it reveals how open-source fashions can keep aggressive with out huge {hardware} budgets. It could not dominate each benchmark, nevertheless it meaningfully improves how actual customers can work with AI at this time. And that’s what makes it stand out in a crowded area.
Hi there, I’m Nitika, a tech-savvy Content material Creator and Marketer. Creativity and studying new issues come naturally to me. I’ve experience in creating result-driven content material methods. I’m nicely versed in search engine optimization Administration, Key phrase Operations, Net Content material Writing, Communication, Content material Technique, Modifying, and Writing.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}