
Organizations working Apache Spark workloads, whether or not on Amazon EMR, AWS Glue, Amazon Elastic Kubernetes Service (Amazon EKS), or self-managed clusters, make investments numerous engineering hours in efficiency troubleshooting and optimization. When a crucial extract, rework, and cargo (ETL) pipeline fails or runs slower than anticipated, engineers find yourself spending hours navigating by a number of interfaces similar to logs or Spark UI, correlating metrics throughout completely different methods and manually analyzing execution patterns to establish root causes. Though Spark Historical past Server offers detailed telemetry knowledge, together with job execution timelines, stage-level metrics, and useful resource consumption patterns, accessing and decoding this wealth of knowledge requires deep experience in Spark internals and navigating by a number of interconnected net interface tabs.
Right now, we’re saying the open supply launch of Spark Historical past Server MCP, a specialised Mannequin Context Protocol (MCP) server that transforms this workflow by enabling AI assistants to entry and analyze your current Spark Historical past Server knowledge by pure language interactions. This venture, developed collaboratively by AWS open supply and Amazon SageMaker Knowledge Processing, turns complicated debugging classes into conversational interactions that ship sooner, extra correct insights with out requiring modifications to your present Spark infrastructure. You should utilize this MCP server together with your self-managed or AWS managed Spark Historical past Servers to investigate Spark purposes working within the cloud or on-premises deployments.
Understanding Spark observability problem
Apache Spark has turn out to be the usual for large-scale knowledge processing, powering crucial ETL pipelines, real-time analytics, and machine studying (ML) workloads throughout hundreds of organizations. Constructing and sustaining Spark purposes is, nevertheless, nonetheless an iterative course of, the place builders spend important time testing, optimizing, and troubleshooting their code. Spark utility builders centered on knowledge engineering and knowledge integration use instances usually encounter important operational challenges due to a couple completely different causes:
- Complicated connectivity and configuration choices to a wide range of assets with Spark – Though this makes it a well-liked knowledge processing platform, it usually makes it difficult to search out the foundation reason behind inefficiencies or failures when Spark configurations aren’t optimally or accurately configured.
- Spark’s in-memory processing mannequin and distributed partitioning of datasets throughout its staff – Though good for parallelism, this usually makes it tough for customers to establish inefficiencies. This leads to sluggish utility execution or root reason behind failures brought on by useful resource exhaustion points similar to out of reminiscence and disk exceptions.
- Lazy analysis of Spark transformations – Though lazy analysis optimizes efficiency, it makes it difficult to precisely and shortly establish the applying code and logic that prompted the failure from the distributed logs and metrics emitted from completely different executors.
Spark Historical past Server
Spark Historical past Server offers a centralized net interface for monitoring accomplished Spark purposes, serving complete telemetry knowledge together with job execution timelines, stage-level metrics, job distribution, executor useful resource consumption, and SQL question execution plans. Though Spark Historical past Server assists builders for efficiency debugging, code optimization, and capability planning, it nonetheless has challenges:
- Time-intensive handbook workflows – Engineers spend hours navigating by the Spark Historical past Server UI, switching between a number of tabs to correlate metrics throughout jobs, phases, and executors. Engineers should consistently change between the Spark UI, cluster monitoring instruments, code repositories, and documentation to piece collectively a whole image of utility efficiency, which regularly takes days.
- Experience bottlenecks – Efficient Spark debugging requires deep understanding of execution plans, reminiscence administration, and shuffle operations. This specialised data creates dependencies on senior engineers and limits workforce productiveness.
- Reactive problem-solving – Groups usually uncover efficiency points solely after they influence manufacturing methods. Handbook monitoring approaches don’t scale to proactively establish degradation patterns throughout a whole lot of each day Spark jobs.
How MCP transforms Spark observability
The Mannequin Context Protocol offers a standardized interface for AI brokers to entry domain-specific knowledge sources. In contrast to general-purpose AI assistants working with restricted context, MCP-enabled brokers can entry technical details about particular methods and supply insights primarily based on precise operational knowledge somewhat than generic suggestions.With the assistance of Spark Historical past Server accessible by MCP, as a substitute of manually gathering efficiency metrics from a number of sources and correlating them to grasp utility habits, engineers can interact with AI brokers which have direct entry to all Spark execution knowledge. These brokers can analyze execution patterns, establish efficiency bottlenecks, and supply optimization suggestions primarily based on precise job traits somewhat than common greatest practices.
Introduction to Spark Historical past Server MCP
The Spark Historical past Server MCP is a specialised bridge between AI brokers and your current Spark Historical past Server infrastructure. It connects to a number of Spark Historical past Server cases and exposes their knowledge by standardized instruments that AI brokers can use to retrieve utility metrics, job execution particulars, and efficiency knowledge.
Importantly, the MCP server capabilities purely as a knowledge entry layer, enabling AI brokers similar to Amazon Q Developer CLI, Claude desktop, Strands Brokers, LlamaIndex, and LangGraph to entry and motive about your Spark knowledge. The next diagram exhibits this circulation.
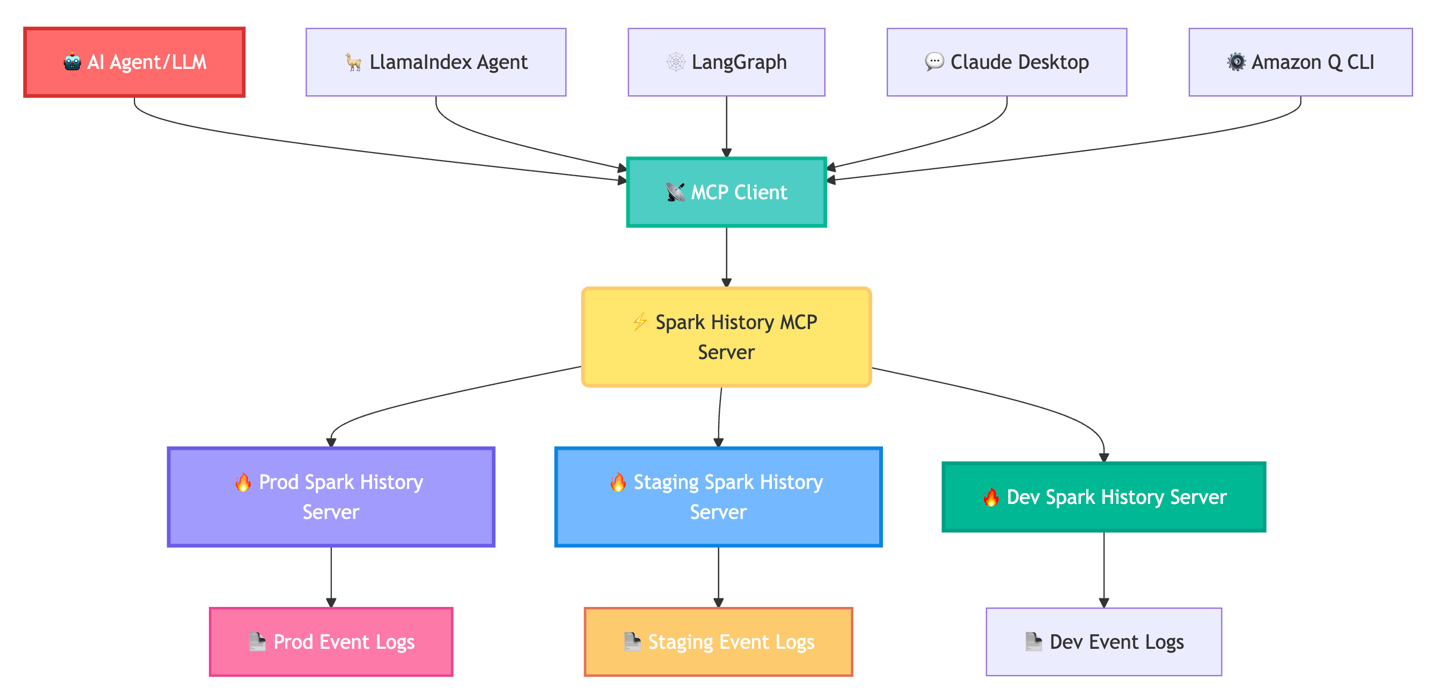
The Spark Historical past Server MCP instantly addresses these operational challenges by enabling AI brokers to entry Spark efficiency knowledge programmatically. This transforms the debugging expertise from handbook UI navigation to conversational evaluation. As a substitute of hours within the UI, ask, “Why did job spark-abcd fail?” and obtain root trigger evaluation of the failure. This enables customers to make use of AI brokers for expert-level efficiency evaluation and optimization suggestions, with out requiring deep Spark experience.
The MCP server offers complete entry to Spark telemetry throughout a number of granularity ranges. Utility-level instruments retrieve execution summaries, useful resource utilization patterns, and success charges throughout job runs. Job and stage evaluation instruments present execution timelines, stage dependencies, and job distribution patterns for figuring out crucial path bottlenecks. Job-level instruments expose executor useful resource consumption patterns and particular person operation timings for detailed optimization evaluation. SQL-specific instruments present question execution plans, be part of methods, and shuffle operation particulars for analytical workload optimization. You may evaluation the whole set of instruments out there within the MCP server within the venture README.
The right way to use the MCP server
The MCP is an open customary that permits safe connections between AI purposes and knowledge sources. This MCP server implementation helps each Streamable HTTP and STDIO protocols for optimum flexibility.
The MCP server runs as a neighborhood service inside your infrastructure both on Amazon Elastic Compute Cloud (Amazon EC2) or Amazon EKS, connecting on to your Spark Historical past Server cases. You preserve full management over knowledge entry, authentication, safety, and scalability.
All of the instruments can be found with streamable HTTP and STDIO protocol:
- Streamable HTTP – Full superior instruments for LlamaIndex, LangGraph, and programmatic integrations
- STDIO mode – Core performance of Amazon Q CLI and Claude Desktop
For deployment, it helps a number of Spark Historical past Server cases and offers deployments with AWS Glue, Amazon EMR, and Kubernetes.
Fast native setup
To arrange Spark Historical past MCP server regionally, execute the next instructions in your terminal:
For complete configuration examples and integration guides, consult with the venture README.
Integration with AWS managed companies
The Spark Historical past Server MCP integrates seamlessly with AWS managed companies, providing enhanced debugging capabilities for Amazon EMR and AWS Glue workloads. This integration adapts to numerous Spark Historical past Server deployments out there throughout these AWS managed companies whereas offering a constant, conversational debugging expertise:
- AWS Glue – Customers can use the Spark Historical past Server MCP integration with self-managed Spark Historical past Server on an EC2 occasion or launch regionally utilizing Docker container. Organising the combination is simple. Observe the step-by-step directions within the README to configure the MCP server together with your most popular Spark Historical past Server deployment. Utilizing this integration, AWS Glue customers can analyze AWS Glue ETL job efficiency no matter their Spark Historical past Server deployment strategy.
- Amazon EMR – Integration with Amazon EMR makes use of the service-managed Persistent UI characteristic for EMR on Amazon EC2. The MCP server requires solely an EMR cluster Amazon Useful resource Identify (ARN) to find the out there Persistent UI on the EMR cluster or mechanically configure a brand new one for instances its lacking with token-based authentication. This eliminates the necessity for manually configuring Spark Historical past Server setup whereas offering safe entry to detailed execution knowledge from EMR Spark purposes. Utilizing this integration, knowledge engineers can ask questions on their Spark workloads, similar to “Are you able to get job bottle neck for spark-
? ” The MCP responds with detailed evaluation of execution patterns, useful resource utilization variations, and focused optimization suggestions, so groups can fine-tune their Spark purposes for optimum efficiency throughout AWS companies.
For complete configuration examples and integration particulars, consult with the AWS Integration Guides.
Wanting forward: The way forward for AI-assisted Spark optimization
This open-source launch establishes the inspiration for enhanced AI-powered Spark capabilities. This venture establishes the inspiration for deeper integration with AWS Glue and Amazon EMR to simplify the debugging and optimization expertise for purchasers utilizing these Spark environments. The Spark Historical past Server MCP is open supply underneath the Apache 2.0 license. We welcome contributions together with new software extensions, integrations, documentation enhancements, and deployment experiences.
Get began right this moment
Rework your Spark monitoring and optimization workflow right this moment by offering AI brokers with clever entry to your efficiency knowledge.
- Discover the GitHub repository
- Assessment the excellent README for setup and integration directions
- Be part of discussions and submit points for enhancements
- Contribute new options and deployment patterns
Acknowledgment: A particular because of everybody who contributed to the event and open-sourcing of the Apache Spark historical past server MCP: Vaibhav Naik, Akira Ajisaka, Wealthy Bowen, Savio Dsouza.
Concerning the authors
 Manabu McCloskey is a Options Architect at Amazon Net Providers. He focuses on contributing to open supply utility supply tooling and works with AWS strategic clients to design and implement enterprise options utilizing AWS assets and open supply applied sciences. His pursuits embody Kubernetes, GitOps, Serverless, and Souls Collection.
Manabu McCloskey is a Options Architect at Amazon Net Providers. He focuses on contributing to open supply utility supply tooling and works with AWS strategic clients to design and implement enterprise options utilizing AWS assets and open supply applied sciences. His pursuits embody Kubernetes, GitOps, Serverless, and Souls Collection.
 Vara Bonthu is a Principal Open Supply Specialist SA main Knowledge on EKS and AI on EKS at AWS, driving open supply initiatives and serving to AWS clients to numerous organizations. He makes a speciality of open supply applied sciences, knowledge analytics, AI/ML, and Kubernetes, with intensive expertise in improvement, DevOps, and structure. Vara focuses on constructing extremely scalable knowledge and AI/ML options on Kubernetes, enabling clients to maximise cutting-edge know-how for his or her data-driven initiatives
Vara Bonthu is a Principal Open Supply Specialist SA main Knowledge on EKS and AI on EKS at AWS, driving open supply initiatives and serving to AWS clients to numerous organizations. He makes a speciality of open supply applied sciences, knowledge analytics, AI/ML, and Kubernetes, with intensive expertise in improvement, DevOps, and structure. Vara focuses on constructing extremely scalable knowledge and AI/ML options on Kubernetes, enabling clients to maximise cutting-edge know-how for his or her data-driven initiatives
 Andrew Kim is a Software program Growth Engineer at AWS Glue, with a deep ardour for distributed methods structure and AI-driven options, specializing in clever knowledge integration workflows and cutting-edge characteristic improvement on Apache Spark. Andrew focuses on re-inventing and simplifying options to complicated technical issues, and he enjoys creating net apps and producing music in his free time.
Andrew Kim is a Software program Growth Engineer at AWS Glue, with a deep ardour for distributed methods structure and AI-driven options, specializing in clever knowledge integration workflows and cutting-edge characteristic improvement on Apache Spark. Andrew focuses on re-inventing and simplifying options to complicated technical issues, and he enjoys creating net apps and producing music in his free time.
 Shubham Mehta is a Senior Product Supervisor at AWS Analytics. He leads generative AI characteristic improvement throughout companies similar to AWS Glue, Amazon EMR, and Amazon MWAA, utilizing AI/ML to simplify and improve the expertise of information practitioners constructing knowledge purposes on AWS.
Shubham Mehta is a Senior Product Supervisor at AWS Analytics. He leads generative AI characteristic improvement throughout companies similar to AWS Glue, Amazon EMR, and Amazon MWAA, utilizing AI/ML to simplify and improve the expertise of information practitioners constructing knowledge purposes on AWS.
 Kartik Panjabi is a Software program Growth Supervisor on the AWS Glue workforce. His workforce builds generative AI options for the Knowledge Integration and distributed system for knowledge integration.
Kartik Panjabi is a Software program Growth Supervisor on the AWS Glue workforce. His workforce builds generative AI options for the Knowledge Integration and distributed system for knowledge integration.
 Mohit Saxena is a Senior Software program Growth Supervisor on the AWS Knowledge Processing Crew (AWS Glue and Amazon EMR). His workforce focuses on constructing distributed methods to allow clients with new AI/ML-driven capabilities to effectively rework petabytes of information throughout knowledge lakes on Amazon S3, databases and knowledge warehouses on the cloud.
Mohit Saxena is a Senior Software program Growth Supervisor on the AWS Knowledge Processing Crew (AWS Glue and Amazon EMR). His workforce focuses on constructing distributed methods to allow clients with new AI/ML-driven capabilities to effectively rework petabytes of information throughout knowledge lakes on Amazon S3, databases and knowledge warehouses on the cloud.

{kind=link}