
As people, we be taught to do new issues, like ballet or boxing (each actions I had the chance to do this summer season!), via trial and error. We enhance by making an attempt issues out, studying from our errors, and listening to steerage. I do know this suggestions loop properly—a part of my intern mission for the summer season was instructing a reward mannequin to establish higher code fixes to indicate customers, as a part of Databricks’ effort to construct a top-tier Code Assistant.
Nonetheless, my mannequin wasn’t the one one studying via trial and error. Whereas instructing my mannequin to tell apart good code fixes from unhealthy ones, I discovered learn how to write sturdy code, steadiness latency and high quality issues for an impactful product, clearly talk to a bigger staff, and most of all, have enjoyable alongside the way in which.
Databricks Assistant Fast Repair
Should you’ve ever written code and tried to run it, solely to get a pesky error, then you definately would respect Fast Repair. Constructed into Databricks Notebooks and SQL Editors, Fast Repair is designed for high-confidence fixes that may be generated in 1-3 seconds—preferrred for syntax errors, misspelled column names, and easy runtime errors. When Fast Repair is triggered, it takes code and an error message, then makes use of an LLM to generate a focused repair to resolve the error.
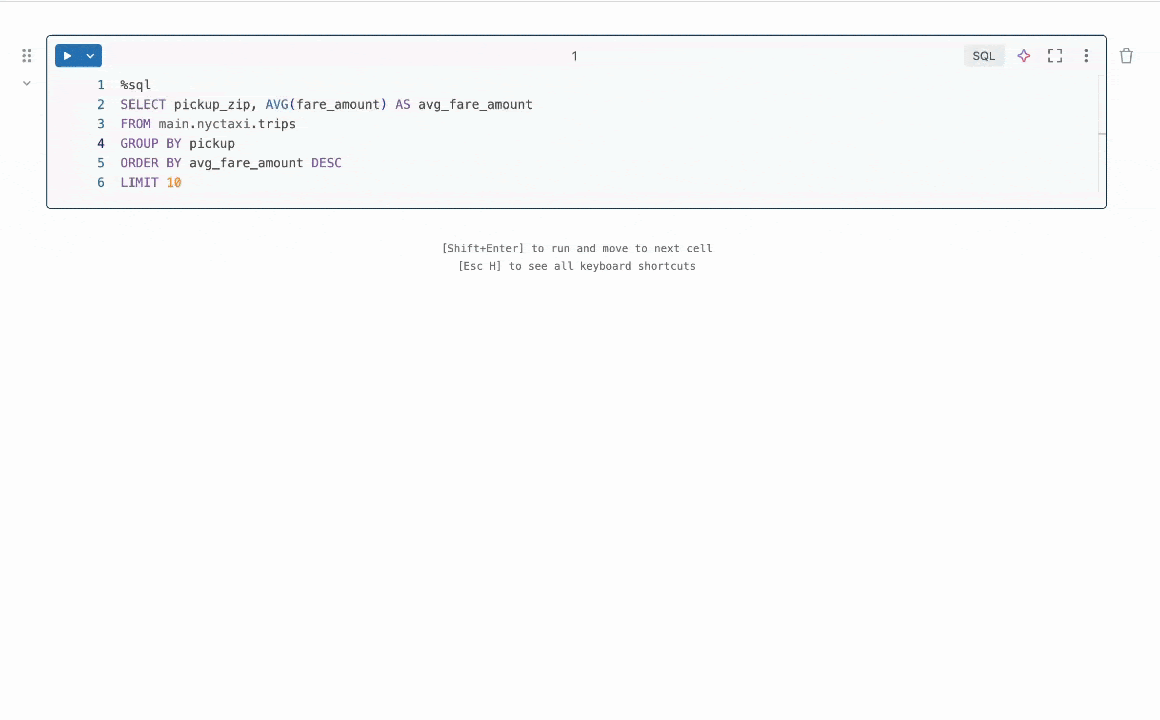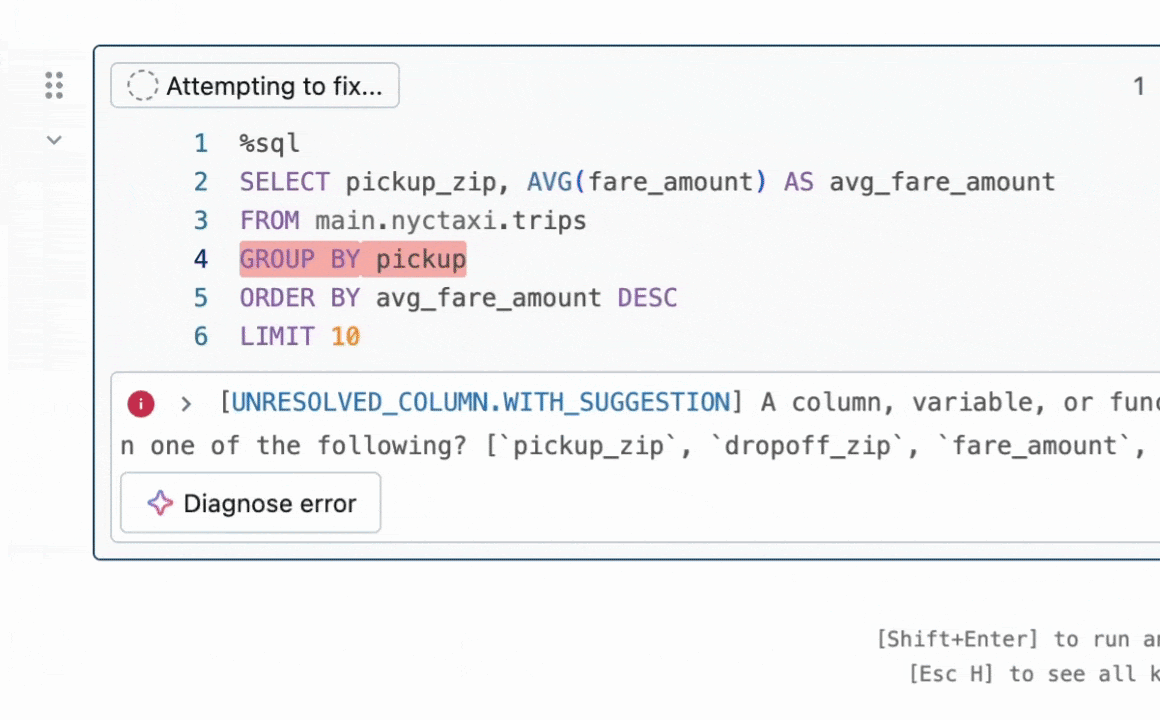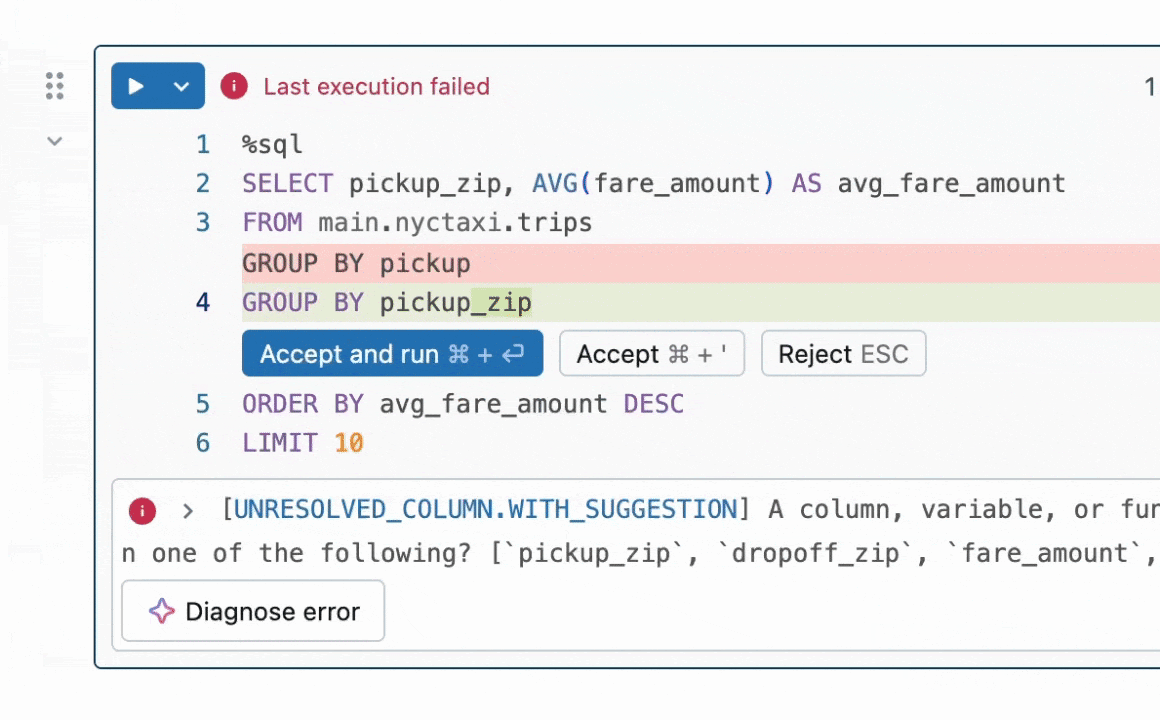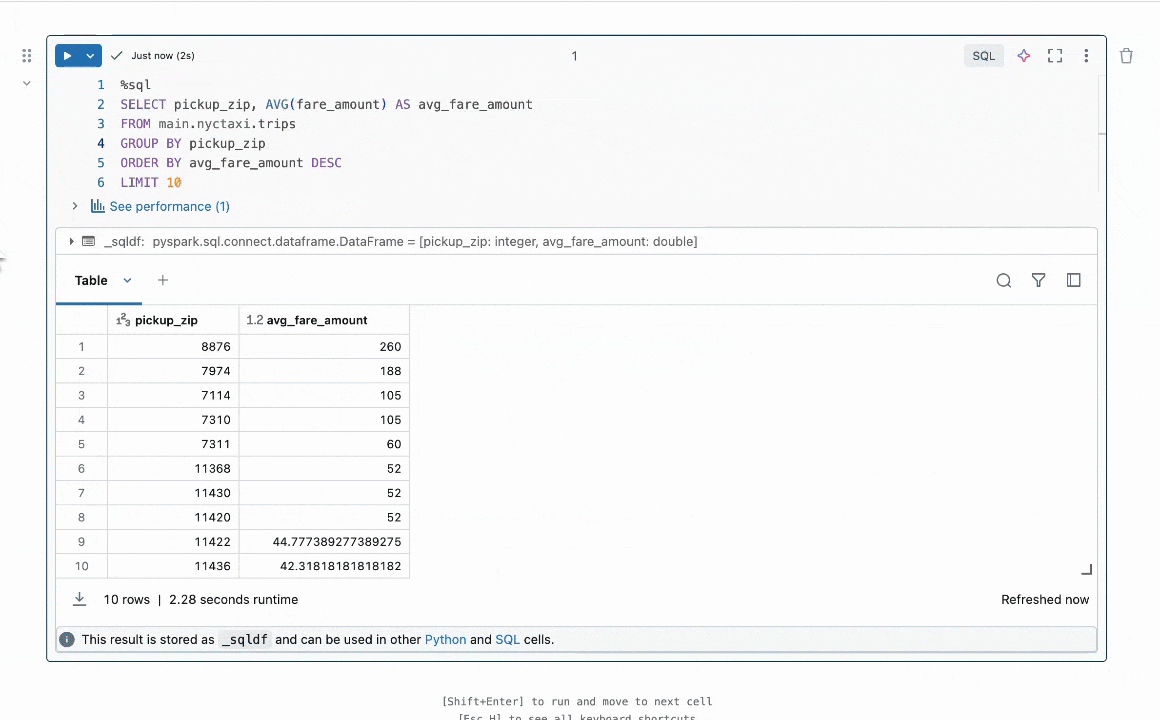
What drawback did my intern mission sort out?
Whereas Fast Repair already existed and was serving to Databricks customers repair their code, there have been loads of methods to make it even higher! For instance, after we generate a code repair and do some fundamental checks that it passes syntax conventions, how can we be certain that the repair we find yourself exhibiting a consumer is probably the most related and correct? Enter best-of-k sampling—generate a number of potential repair ideas, then use a reward mannequin to decide on the most effective one.
My mission construction
My mission concerned a mixture of backend implementation and analysis experimentation, which I discovered to be enjoyable and stuffed with studying.

Producing a number of ideas
I first expanded the Fast Repair backend movement to generate numerous ideas in parallel utilizing completely different prompts and contexts. I experimented with methods like including chain-of-thought reasoning, predicted outputs reasoning, system immediate variations, and selective database context to maximise the standard and variety of ideas. We discovered that producing ideas with further reasoning elevated our high quality metrics but additionally induced some latency value.
Selecting the most effective repair suggestion to indicate to the consumer
After a number of ideas are generated, we’ve got to decide on the most effective one to return. I began by implementing a easy majority voting baseline, which introduced the consumer with probably the most regularly advised repair—working on the precept {that a} extra generally generated answer would seemingly be the best. This baseline carried out properly within the offline evaluations however didn’t carry out considerably higher than the present implementation in on-line consumer A/B testing, so it was not rolled out to manufacturing.
Moreover, I developed reward fashions to rank and choose probably the most promising ideas. I skilled the fashions to foretell which fixes customers would settle for and efficiently execute. We used classical machine studying approaches (logistic regression and gradient boosted resolution tree utilizing the LightGBM bundle) and fine-tuned LLMs.
Outcomes and impression
Surprisingly, for the duty of predicting consumer acceptance and execution success of candidate fixes, the classical fashions carried out comparably to the fine-tuned LLMs in offline evaluations. The choice tree mannequin particularly may need carried out properly as a result of code edits that “look proper” for the sorts of errors that Fast Repair handles are inclined to the truth is be appropriate: the options that turned out to be notably informative have been the similarity between the unique line of code and the generated repair, in addition to the error sort.
Given this efficiency, we determined to deploy the choice tree (LightGBM) mannequin in manufacturing. One other consider favor of the LightGBM mannequin was its considerably sooner inference time in comparison with the fine-tuned LLM. Pace is vital for Fast Repair since ideas should seem earlier than the consumer manually edits their code, and any further latency means fewer errors mounted. The small dimension of the LightGBM mannequin made it way more useful resource environment friendly and simpler to productionize—alongside some mannequin and infrastructure optimizations, we have been in a position to lower our common inference time by virtually 100x.
With the best-of-k strategy and reward mannequin applied, we have been in a position to elevate our inside acceptance charge, growing high quality for our customers. We have been additionally in a position to preserve our latency inside acceptable bounds of our unique implementation.
If you wish to be taught extra concerning the Databricks Assistant, take a look at the touchdown web page or the Assistant Fast Repair Announcement.
My Internship Expertise
Databricks tradition in motion
This internship was an unbelievable expertise to contribute on to a high-impact product. I gained firsthand perception into how Databricks’ tradition encourages a robust bias for motion whereas sustaining a excessive bar for system and product high quality.
From the beginning, I observed how clever but humble everybody was. That impression solely grew stronger over time, as I noticed how genuinely supportive the staff was. Even very senior engineers often went out of their approach to assist me succeed, whether or not by speaking via technical challenges, providing considerate suggestions, or sharing their previous approaches and learnings.
I’d particularly like to present a shoutout to my mentor Will Tipton, my managers Phil Eichmann and Shanshan Zheng, my casual mentors Rishabh Singh and Matt Hayes, the Editor / Assistant staff, the Utilized AI staff, and the MosaicML of us for his or her mentorship. I’ve discovered invaluable abilities and life classes from them, which I’ll take with me for the remainder of my profession.
The opposite superior interns!
Final however not least, I had a good time attending to know the opposite interns! The recruiting staff organized many enjoyable occasions that helped us join—certainly one of my favorites was the Intern Olympics (pictured beneath). Whether or not it was chatting over lunch, making an attempt out native exercise lessons, or celebrating birthdays with karaoke, I actually appreciated how supportive and close-knit the intern group was, each in and outdoors of labor.

Intern Olympics! Go Group 2!

Shout-out to the opposite interns who tried boxing with me!
This summer season taught me that the most effective studying occurs whenever you’re fixing actual issues with actual constraints—particularly whenever you’re surrounded by good, pushed, and supportive individuals. Probably the most rewarding a part of my internship wasn’t simply finishing mannequin coaching or presenting fascinating outcomes to the staff, however realizing that I’ve grown in my means to ask higher questions, cause via design trade-offs, and ship a concrete characteristic from begin to end on a platform as broadly used as Databricks.
If you wish to work on cutting-edge tasks with superb teammates, I’d suggest you to use to work at Databricks! Go to the Databricks Careers web page to be taught extra about job openings throughout the corporate.

{kind=link}