
Twilio is a buyer engagement platform that powers real-time, personalised buyer experiences for main manufacturers by way of APIs that democratize communications channels like voice, textual content, chat, and video.
At Twilio, we handle a 20 petabyte-scale Amazon Easy Storage Service (Amazon S3) information lake that serves the analytics wants of over 1,500 customers, processing 2.5 million queries month-to-month, and scanning a mean of 85 PB of information. To fulfill our rising calls for for scalability, rising expertise assist, and information mesh structure adoption, we constructed Odin, a multi-engine question platform that gives an abstraction layer constructed on high of Presto Gateway.
On this put up, we focus on how we designed and constructed Odin, combining Amazon Athena with open-source Presto to create a versatile, scalable information querying resolution.
A rising want for a multi-engine platform
Our information platform has been constructed on Presto since its inception, however over time as we expanded to assist a number of enterprise strains and numerous use instances, we started to come across challenges associated to scalability, operational overhead, and value administration. Sustaining the platform by way of frequent model upgrades additionally turned troublesome. These upgrades required important time to judge backwards compatibility, combine with our current information ecosystem, and decide optimum configurations throughout releases.
The executive burden of upgrades and our dedication to minimizing consumer disruption brought on our Presto model to fall behind. This prevented us from accessing the most recent options and optimizations out there in later releases. The adoption of Apache Hudi for our transaction-dependent essential workloads created a brand new requirement which our current Presto deployment model couldn’t assist. We would have liked an up-to-date Presto or Trino appropriate service to accommodate these use instances whereas nonetheless lowering the operational overhead of sustaining our personal question infrastructure.
Constructing a complete information platform required us to steadiness a number of competing necessities and enterprise constraints. We would have liked an answer that would assist numerous workload sorts, from interactive analytics to ETL batch processing, whereas offering the flexibleness to optimize compute assets primarily based on particular use instances. We additionally needed to enhance upon price administration and attribution in our shared multi-tenanted question platform. Moreover, we would have liked to make sure that adopting any new expertise didn’t trigger any disruption to our customers and maintained backward compatibility with current methods through the transition interval.
Deciding on Amazon Athena as our trendy analytics engine
Our customers relied on SQL for interactive evaluation, and we needed to protect this expertise and make use of our current jobs and software code. This meant we would have liked a Presto-compatible analytics service to modernize our information platform.
Amazon Athena is a serverless interactive question service constructed on Presto and Trino that lets you run queries utilizing a well-recognized ANSI SQL interface. Athena appealed to us on account of its compatibility with open-source Trino and its seamless improve expertise. Athena helps to ease the burden of managing a large-scale question infrastructure, and with provisioned capability, affords predictable and scalable pricing for our largest question workloads. Athena’s workgroups offered the question and value administration capabilities we would have liked to effectively assist numerous groups and workload patterns with minimal overhead.
The power to mix on-demand and devoted serverless capability fashions permits us to optimize workload distribution for our necessities, attaining the flexibleness and scalability wanted in a managed question surroundings. To deal with latency-sensitive and predictive question workloads, we adopted provisioned capability for its serverless capability assure and workload concurrency management options. For queries which may be ad-hoc and extra versatile in scheduling, we opted to make use of the cost-efficient multi-tenant on-demand mannequin, which optimizes useful resource utilization by way of shared infrastructure. In parallel to migrating workloads to Athena, we additionally wanted a strategy to assist legacy workloads that use customized implementations of Presto options. This requirement drove us to summary the underlying implementation, permitting us to current customers with a unified interface. This could give us the flexibleness key to future proof our infrastructure and use probably the most applicable compute for the workload and use case.
The delivery of Odin
The next diagram reveals Twilio’s multi-engine question platform that comes with each Amazon Athena and open-source Presto.
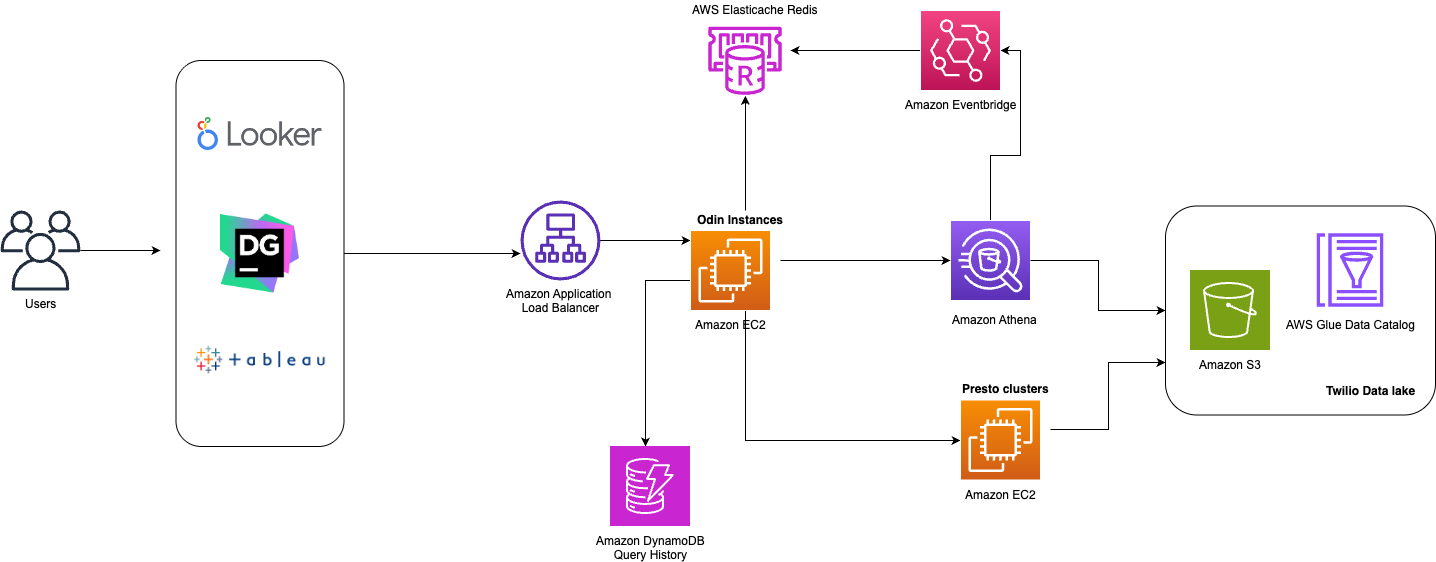
Excessive Stage Structure of Odin’s Question Engines
Odin is a Presto-based gateway constructed on Zuul, an open-source L7 software gateway developed by Netflix. Zuul had already demonstrated its scalability at Twilio, having been efficiently adopted by different inside groups. Since finish customers primarily connect with the platform by way of a JDBC connector utilizing the Presto Driver (which operates by way of HTTP calls), Zuul’s specialization in HTTP name administration made it a super technical selection for our wants.
Odin features as a central hub for question processing, using a pluggable design that accommodates numerous question frameworks for max extensibility and suppleness. To work together with the Odin platform customers are initially directed to an Amazon Software Load Balancer that sits in entrance of the Odin cases operating on Amazon EC2. The Odin cases deal with the authentication, routing, and full question workflow all through the question’s lifetime. Amazon ElastiCache for Redis handles the question monitoring for Athena and Amazon DynamoDB is accountable for the sustaining the question historical past. Each question engines, Amazon Athena and the Presto clusters operating on Amazon EC2,are supported by the AWS Glue Information Catalog because the metastore repository and question information from our Amazon S3-based information lake.
Routing queries to a number of engines
We had quite a lot of use instances that had been being served by this question platform and subsequently we opted to make use of Amazon Athena as our main question engine whereas persevering with to route sure legacy workloads to our Presto clusters. Previous to our architectural redesign, we encountered operational challenges on account of our finish customers being tightly certain to particular Presto clusters which led to inevitable disruptions throughout upkeep home windows. Moreover, customers regularly overloaded particular person clusters with numerous workloads starting from light-weight ad-hoc analytics to complicated information warehousing queries and resource-intensive ETL processes. This prompted us to implement a extra refined routing resolution, one which was use case targeted and never tightly certain to the precise underlying compute.
To allow routing throughout a number of question engines inside the similar platform, we developed a question trace mechanism that enables customers to specify their meant use case. Customers append this trace to the JDBC string by way of the X-Presto-Further-Credential header, which Odin’s logical routing layer then evaluates alongside a number of components together with consumer identification, question origin, and fallback planning. The system additionally assesses whether or not the goal useful resource has ample capability, if not, it reroutes the question to an alternate useful resource with out there capability. Whereas customers present preliminary context by way of their hints, Odin makes the ultimate routing choices intelligently on the server aspect. This strategy balances consumer enter with centralized orchestration, guaranteeing constant efficiency and useful resource availability.
For instance, say a consumer may specify the next connection string when connecting to the Odin platform from a Tableau shopper:
The connection string makes use of the extraCredentials header to sign execution on Athena, the place Odin validates question submission particulars, together with the submitting consumer and power, earlier than figuring out the suitable Athena workgroup for preliminary routing. Since this Tableau information supply and consumer qualify as “essential queries,” the system routes them to a workgroup backed by capability reservations. Nevertheless, if that workgroup has too many pending queries within the execution queue, Odin’s routing logic routinely redirects to different workgroups with better out there assets. When vital, queries might in the end path to workgroups operating on on-demand capability. Via this fallback logic, Odin offers built-in load balancing on the routing layer, guaranteeing optimum utilization throughout the underlying compute infrastructure.
Right here is an instance workflow of how our queries are routed to Athena workgroups:
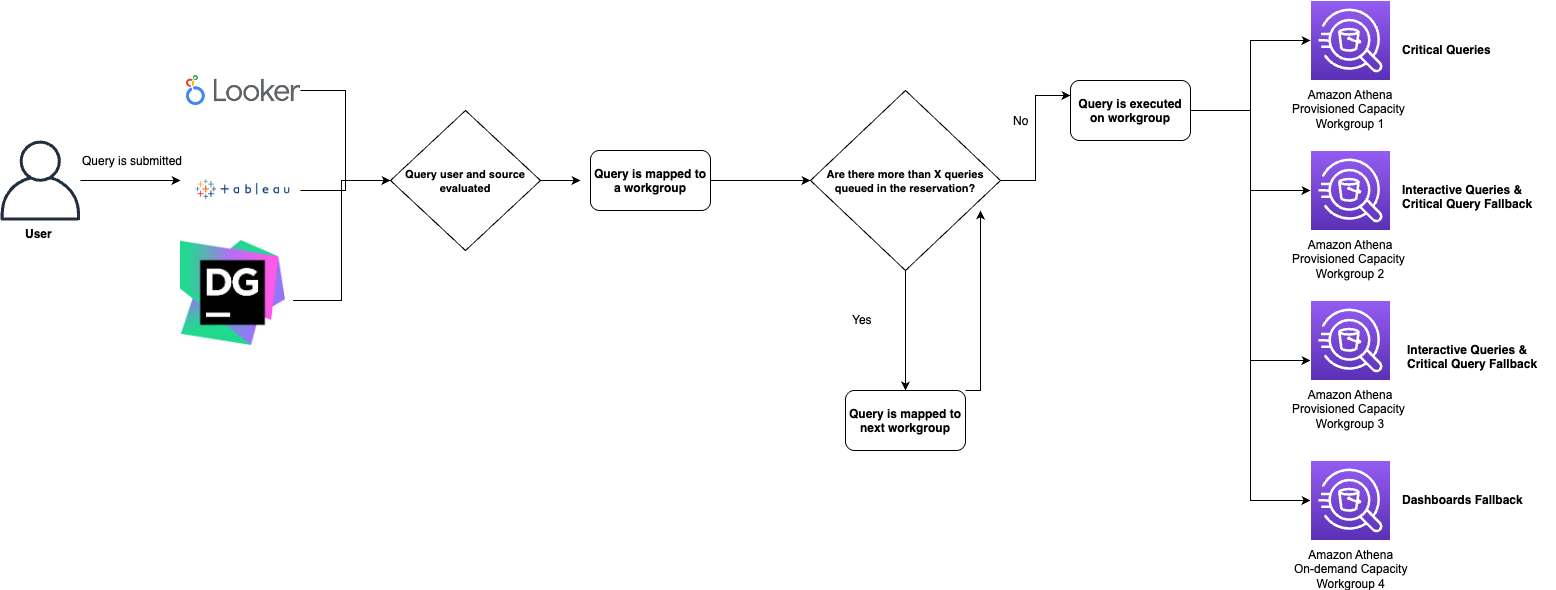
As soon as a question has been submitted to a workgroup for execution, Odin may even log the routing determination in our monitoring system primarily based on Amazon ElastiCache for Redis in order that Odin’s routing logic can preserve real-time consciousness of queue depths throughout all Athena workgroups. Moreover, Odin makes use of Amazon EventBridge to combine with Amazon Athena to maintain monitor of a question state change and create event-based workflows. Our Redis-based question monitoring system successfully handles edge instances, corresponding to when a JDBC shopper terminates mid-query. Even throughout such surprising interruptions, the platform constantly maintains and updates the correct state of the question.
Question historical past
Following profitable question routing to both an Athena workgroup or one in all our open-source Presto clusters, Odin persists the question identifier and vacation spot endpoint in a question historical past desk in DynamoDB. This design makes use of a RESTful structure the place preliminary question submissions function as POST requests, whereas subsequent standing checks operate as GET requests that make the most of DynamoDB because the authoritative lookup mechanism to find and ballot the suitable execution engine. By centralizing question execution data in DynamoDB moderately than sustaining state on particular person servers, we’ve created a really stateless system the place incoming requests may be dealt with by any Amazon EC2 occasion internet hosting our Odin net service.
Classes discovered
The transition from open-source Presto to Athena required some adaptation time, on account of delicate variations in how these question engines function. Since our Odin framework was constructed on the Presto driver, we would have liked to switch our processing strategy to make sure compatibility between each methods.
As we started to undertake Athena for extra use instances, we observed a distinction within the file counts between Athena and the unique Presto queries. We found this was on account of open-source Presto returning outcomes with each web page containing a header column, whereas Athena outcomes solely include the header column on the primary web page and subsequent pages containing data solely. This distinction meant that for a 60-page consequence set, Athena would return 59 fewer rows than open-source Presto. As soon as we recognized this pagination conduct, we optimized Odin’s consequence dealing with logic to correctly interpret and course of Athena’s format, in order that queries would return correct outcomes.
As a result of nature of utilizing the Odin platform, most of our interactions with the Athena service are API pushed so we make use of the ResultSet object with the GetQueryResults API to retrieve question execution information. Utilizing this mechanism, the API returns the info as all VARCHAR information sort, even for complicated sorts corresponding to row, map, or array. This created a problem as a result of Odin makes use of the Presto driver for question parsing, leading to a kind mismatch between the anticipated codecs and precise returned information. To deal with this, we applied a translation layer inside the Odin framework that converts all information sorts to VARCHAR and handles any downstream implications of this conversion internally.
These technical changes, whereas initially difficult, highlighted the significance of rigorously managing the delicate variations between totally different question execution engines when constructing a unified information platform.
Scale of Odin and looking out forward
The Odin platform serves over 1,500 customers who execute roughly 80,000 queries each day, totaling 2.5 million queries monthly. Odin additionally powers greater than 5,000 Enterprise Intelligence (BI) stories and dashboards for Tableau and Looker. The queries are executed throughout our multi-engine panorama of greater than 30 workgroups in Athena primarily based on each provisioned capability and on-demand workgroups and 4 Presto clusters on operating on EC2 cases with Auto Scaling enabled that run on common 180 cases every. As Twilio continues to expertise speedy development, our Odin platform has enabled us to mature our expertise stacks by each upgrading current compute assets and integrating new applied sciences. We will do all this with out disrupting the expertise for our finish customers. Whereas Odin serves as our basis, we’re excited to proceed to broaden this pluggable infrastructure. Our roadmap contains migrating our self-managed open-source Presto implementation to EMR Trino, introducing Apache Spark as a compute engine by way of Amazon EMR Serverless or AWS Glue jobs, and integrating generative AI capabilities to intelligently route queries throughout Odin’s numerous compute choices.
Conclusion
On this put up, we’ve shared how we constructed Odin, our unified multi-engine question platform. By combining AWS companies like Amazon Athena, Amazon ElastiCache for Redis, and Amazon DynamoDB with our open-source expertise stack, we created a clear abstraction layer for customers. This integration has resulted in a extremely out there and resilient platform surroundings that serves our question processing wants.
By embracing this multi-engine strategy, not solely did we clear up our question infrastructure challenges however we additionally established a versatile basis that may proceed to evolve with our information wants, guaranteeing we will ship highly effective insights at scale no matter how expertise developments shift sooner or later.
To study extra and get began utilizing Amazon Athena, please see the Athena Consumer Information.
In regards to the authors

{kind=link}