
At Slack, our information platform processes terabytes of knowledge every day utilizing Apache Spark on Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2), powering the insights that drive strategic decision-making throughout the group.
As our information quantity expanded, so did our efficiency challenges. With conventional monitoring instruments, we couldn’t successfully handle our programs when Spark jobs slowed down or prices spiraled uncontrolled. We had been caught looking out via cryptic logs, making educated guesses about useful resource allocation, and watching our engineering groups spend hours on guide tuning that ought to have been automated. That’s why we constructed one thing higher: an in depth metrics framework designed particularly for Spark’s distinctive challenges. It is a visibility system that provides us granular insights into software habits, useful resource utilization, and job-level efficiency patterns we by no means had earlier than. We’ve achieved 30–50% value reductions and 40–60% sooner job completion occasions. That is actual operational effectivity that immediately interprets to higher service for our customers and important financial savings for our infrastructure price range. On this put up, we stroll you thru precisely how we constructed this framework, the important thing metrics that made the distinction, and the way your group can implement comparable monitoring to rework your personal Spark operations.
Why complete Spark monitoring issues
In enterprise environments, poorly optimized Spark jobs can waste 1000’s of {dollars} in cloud compute prices, block essential information pipelines affecting downstream enterprise processes, create cascading failures throughout interconnected information workflows, and affect service stage settlement (SLA) compliance for time-sensitive analytics.
The monitoring framework we’re analyzing captures over 40 distinct metrics throughout 5 key classes, offering the granular insights wanted to stop these points.
How we ingest, course of, and act on Spark metrics
To deal with the challenges of managing Spark at scale, we developed a customized monitoring and optimization pipeline—from metric assortment to AI-assisted tuning. It begins with our in-house Spark listener framework, which captures over 40 metrics in actual time throughout Spark functions, jobs, levels, and duties whereas pulling essential operational context from instruments resembling Apache Airflow and Apache Hadoop YARN.
An Apache Airflow-orchestrated Spark SQL pipeline transforms this information into actionable insights, surfacing efficiency bottlenecks and failure factors. To combine these metrics into the developer tuning workflow, we expose a metrics device and a customized immediate via our inner analytics mannequin context protocol (MCP) server. This allows seamless integration with AI-assisted coding instruments resembling Cursor or Claude Code.
The next is the checklist of instruments used for our Spark monitoring answer, which incorporates metric assortment to AI-assisted tuning:
The result’s quick, dependable, deterministic Spark tuning with out the guesswork. Builders get environment-aware suggestions, automated configuration updates, and ready-to-review pull requests.
Deep dive into Spark metrics assortment
On the middle of our real-time monitoring answer lies a customized Spark listener framework that captures thorough telemetry throughout the Spark lifecycle. Spark’s built-in metrics are sometimes coarse, quick‑lived, and scattered throughout the person interface (UI) and logs, which leaves 4 essential gaps:
- Constant historic report
- Weak linkage from functions to jobs to levels to duties
- Restricted context (person, cluster, group)
- Poor visibility into patterns resembling skew, spill, and retries
Our expanded listener framework closes these gaps by unifying and enriching telemetry with setting and configuration tags, constructing a sturdy, queryable historical past, and correlating occasions throughout the execution graph. It explains why duties fail, pinpoints the place reminiscence or CPU stress happens, compares meant configurations to precise utilization, and produces clear, repeatable tuning suggestions so groups can baseline habits, reduce waste, and resolve points sooner. The next structure diagram illustrates the stream of the Spark metrics assortment pipeline.

Spark listener
Our listener framework captures Spark metrics at 4 distinct ranges:
- Software metrics: General software success/failure charges, complete runtime, and useful resource allocation
- Job-level metrics: Particular person job period and standing monitoring inside an software
- Stage-level metrics: Stage execution particulars, shuffle operations, and reminiscence utilization per stage
- Job-level metrics: Particular person process efficiency for deep debugging eventualities
The next Scala instance code exhibits the SparkTaskListener extends the category SparkListener to seize detailed task-level metrics:
Actual-time streaming to Kafka
These metrics are streamed in actual time to Kafka as JSON-formatted telemetry utilizing a versatile emitter system:
From Kafka, a downstream pipeline ingests these information into an Apache Iceberg desk.
Context-rich observability
Past commonplace Spark metrics, our framework captures important operational context:
- Airflow integration: DAG metadata, process IDs, and execution timestamps
- Useful resource monitoring: Configurable executor metrics (heap utilization, execution reminiscence)
- Atmosphere context: Cluster identification, person monitoring, and Spark configurations
- Failure evaluation: Detailed error messages and process failure root causes
The mixture of thorough metrics assortment and real-time streaming has redefined Spark monitoring at scale, laying the groundwork for highly effective insights.
Deep dive into Spark metrics processing
When uncooked metrics—typically containing hundreds of thousands of information—are ingested from varied sources, a Spark SQL pipeline transforms this high-volume information into actionable insights. It aggregates the information right into a single row per software ID, considerably lowering complexity whereas preserving key efficiency indicators.
For consistency in how groups interpret and act on this information, we apply the 5 Pillars of Spark Monitoring, a structured framework that turns uncooked telemetry into clear diagnostics and repeatable optimization methods, as proven within the following desk.
| Pillar | Metrics | Key goal/perception | Driving occasion |
|---|---|---|---|
| Software metadata and orchestration particulars |
|
Correlate efficiency patterns with groups and infrastructure to determine inefficiencies and possession. |
|
| Person-specified configuration |
|
Examine configuration versus precise efficiency to detect over- and under-provisioning and optimizing prices. That is the place important value financial savings typically cover. | Spark occasion: |
| Efficiency insights |
|
That is the place the true diagnostic energy lies. These metrics determine the three major stoppers of Spark efficiency: skew, spill, and failures. | Spark occasion: |
| Execution insights |
|
Perceive runtime distribution, determine bottlenecks, and spotlight execution outliers. | Spark occasion:
|
| Useful resource utilization and system well being |
|
Reveal reminiscence inefficiencies and JVM-related stress for value and stability enhancements. Evaluating these towards given configs helps determine waste and optimize assets. | Spark occasion:
|
AI-powered Spark tuning
The next structure diagram illustrates the usage of agentic AI instruments to research the aggregated Spark metrics.
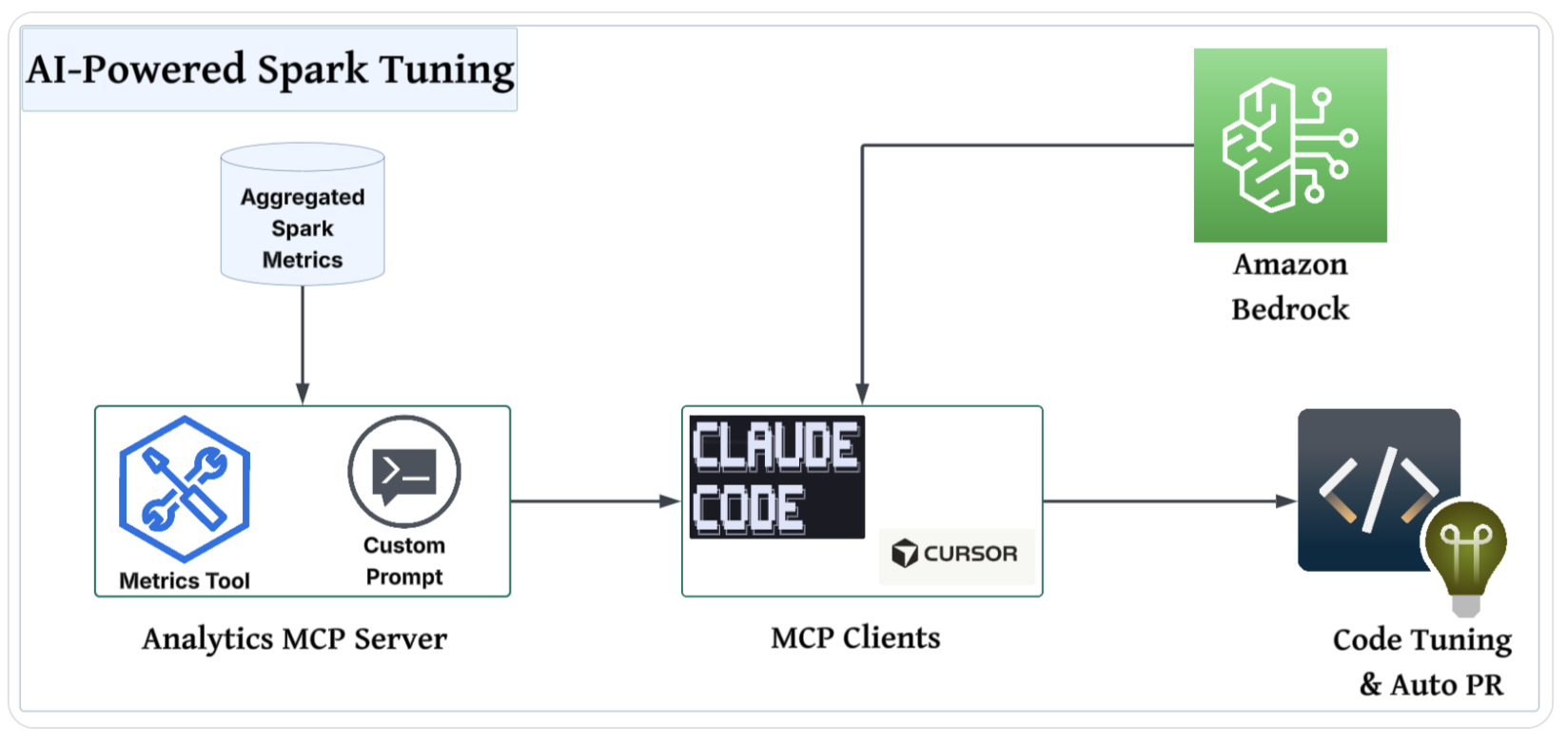
To combine these metrics right into a developer’s tuning workflow, we construct a customized Spark metrics device and a customized immediate that any agent can use. We use our current analytics service, a homegrown net software that customers can question our information warehouse with, construct dashboards, and share insights. The backend is written in Python utilizing FastAPI, and we expose an MCP server from the identical service by utilizing FastMCP. By exposing the Spark metrics device and customized immediate via the MCP server, we make it potential for builders to attach their most well-liked assisted coding instruments (Cursor, Claude Code, and extra) and use information to information their tuning.
As a result of the information uncovered by the analytics MCP server may be delicate, we use Amazon Bedrock in our Amazon Net Providers (AWS) account to offer the inspiration fashions to our MCP purchasers. This retains our information safer and facilitates compliance as a result of it by no means leaves our AWS setting.
Customized immediate
To create our customized immediate for AI-driven Spark tuning, we design a structured, rule-based format that encourages extra deterministic and standardized output. The immediate defines the required sections (software overview, present Spark configuration, job well being abstract, useful resource suggestions, and abstract) for consistency throughout analyses. We embrace detailed formatting guidelines, resembling wrapping values in backticks, avoiding line breaks, and imposing strict desk constructions to keep up readability and machine readability. The immediate additionally embeds express steering for deciphering Spark metrics and mapping them to beneficial tuning actions based mostly on greatest practices, with clear standards for standing flags and affect explanations. The immediate implies that the AI’s suggestions might be traced, reproduced, and actioned based mostly on the supplied information by tightly controlling the input-output stream and making an attempt to stop hallucinations.
Closing outcomes
The screenshots on this part present how our device carried out the evaluation and supplied suggestions. The next is a efficiency evaluation for an current software.

The next is a advice to cut back useful resource waste.
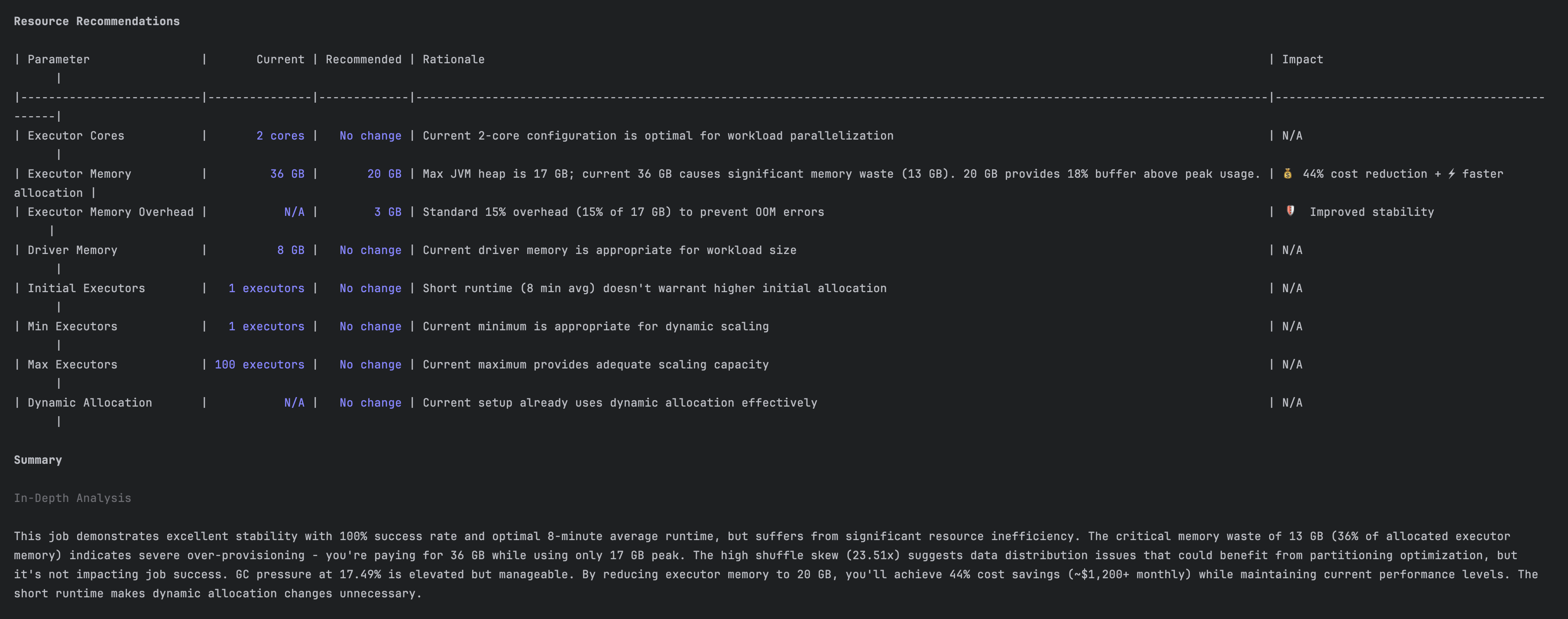
The affect
Our AI-powered framework has basically modified how Spark is monitored and managed at Slack. We’ve reworked Spark tuning from a high-expertise, trial-and-error course of into an automatic, data-backed commonplace by transferring past conventional log-diving and embracing a structured, AI-driven method. The outcomes communicate for themselves, as proven within the following desk.
| Metric | Earlier than | After | Enchancment |
|---|---|---|---|
| Compute value | Non-deterministic | Optimized useful resource use | As much as 50% decrease |
| Job completion time | Non-deterministic | Optimized | Over 40% sooner |
| Developer time on tuning | Hours per week | Minutes per week | >90% discount |
| Configuration waste | Frequent over-provisioning | Exact useful resource allocation | Close to-zero waste |
Conclusion
At Slack, our expertise with Spark monitoring exhibits that you simply don’t must be a efficiency skilled to realize distinctive outcomes. We’ve shifted from reacting to efficiency points to stopping them by systematically making use of 5 key metric classes.
The numbers communicate for themselves: 30–50% value reductions and 40–60% sooner job completion occasions characterize operational effectivity that immediately impacts our capability to serve hundreds of thousands of customers worldwide. These enhancements compound over time as groups construct confidence of their information infrastructure and might deal with innovation slightly than troubleshooting.
Your group can obtain comparable outcomes. Begin with the fundamentals: implement complete monitoring, set up baseline metrics, and decide to steady optimization. Spark efficiency doesn’t require experience in each parameter, nevertheless it does require a powerful monitoring basis and a disciplined method to evaluation.
Acknowledgments
We wish to give our due to all of the individuals who have contributed to this unimaginable journey: Johnny Cao, Nav Shergill, Yi Chen, Lakshmi Mohan, Apun Hiran, and Ricardo Bion.
Concerning the authors

{kind=link}