
As information quantity grows, so do the dangers in your information platform: from stale pipelines to hidden errors and runaway prices. With out observability built-in into your information engineering answer, you’re flying blind and risking impacting not simply the well being and freshness of your information pipelines, but additionally lacking critical points in your downstream information, analytics, and AI workloads. With Lakeflow, Databricks’ unified and clever information engineering answer, you possibly can simply deal with this problem with built-in observability options in an intuitive interface straight inside your ETL platform, on high of your Information Intelligence.
On this weblog, we’ll introduce Lakeflow’s observability capabilities and present methods to construct dependable, recent, and wholesome information pipelines.
Observability is Important for Information Engineering
Observability for information engineering is the flexibility to find, monitor, and troubleshoot methods to make sure the ETL operates appropriately and successfully. It’s the key to sustaining wholesome and dependable information pipelines, surfacing insights, and delivering reliable downstream analytics.
As organizations handle an more and more rising variety of business-critical pipelines, monitoring and guaranteeing the reliability of an information platform has change into very important for a enterprise. To deal with this problem, extra information engineers are recognizing and looking for the advantages of observability. In response to Gartner, 65% of knowledge and analytics leaders anticipate information observability to change into a core a part of their information technique inside two years. Information engineers who need to keep present and discover methods to enhance productiveness, whereas driving secure information at scale, ought to implement observability practices of their information engineering platform.
Establishing the precise observability in your group entails bringing the next key capabilities:
- Finish-to-end visibility at scale: get rid of blind spots and uncover system insights by simply viewing and analyzing your jobs and information pipelines in a single single location
- Proactive monitoring and early failure detection: establish potential points as quickly as they come up, earlier than they influence something downstream
- Troubleshooting and optimization: repair issues to make sure the standard of your outputs and optimize your system’s efficiency to enhance operational prices
Learn on to see how Lakeflow helps all of those in a single expertise.
Finish-to-Finish Visibility at Scale into Jobs and Pipelines
Efficient observability begins with full visibility. Lakeflow comes with quite a lot of out-of-the-box visualizations and unified views that will help you keep on high of your information pipelines and ensure your complete ETL course of is operating easily.
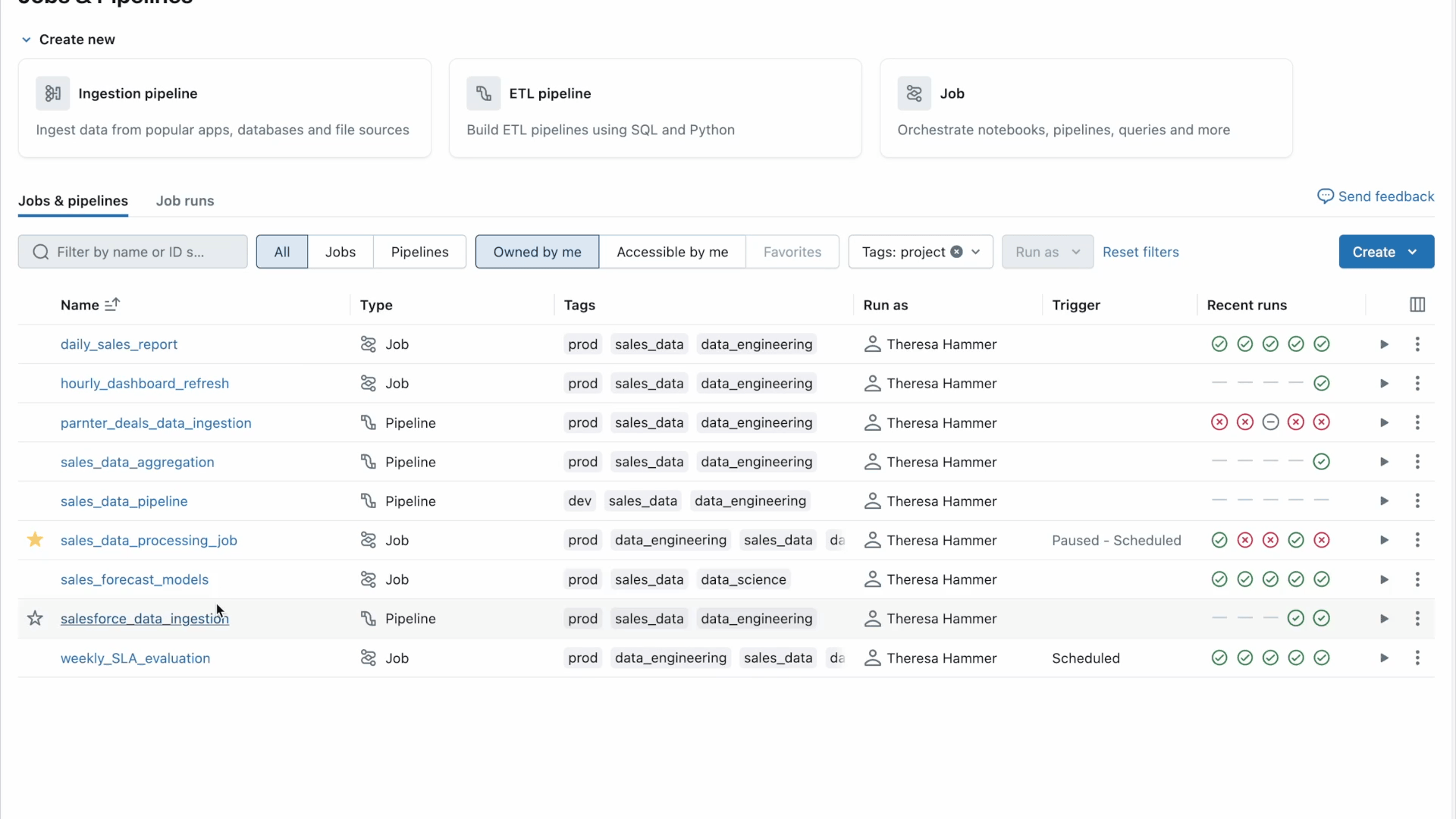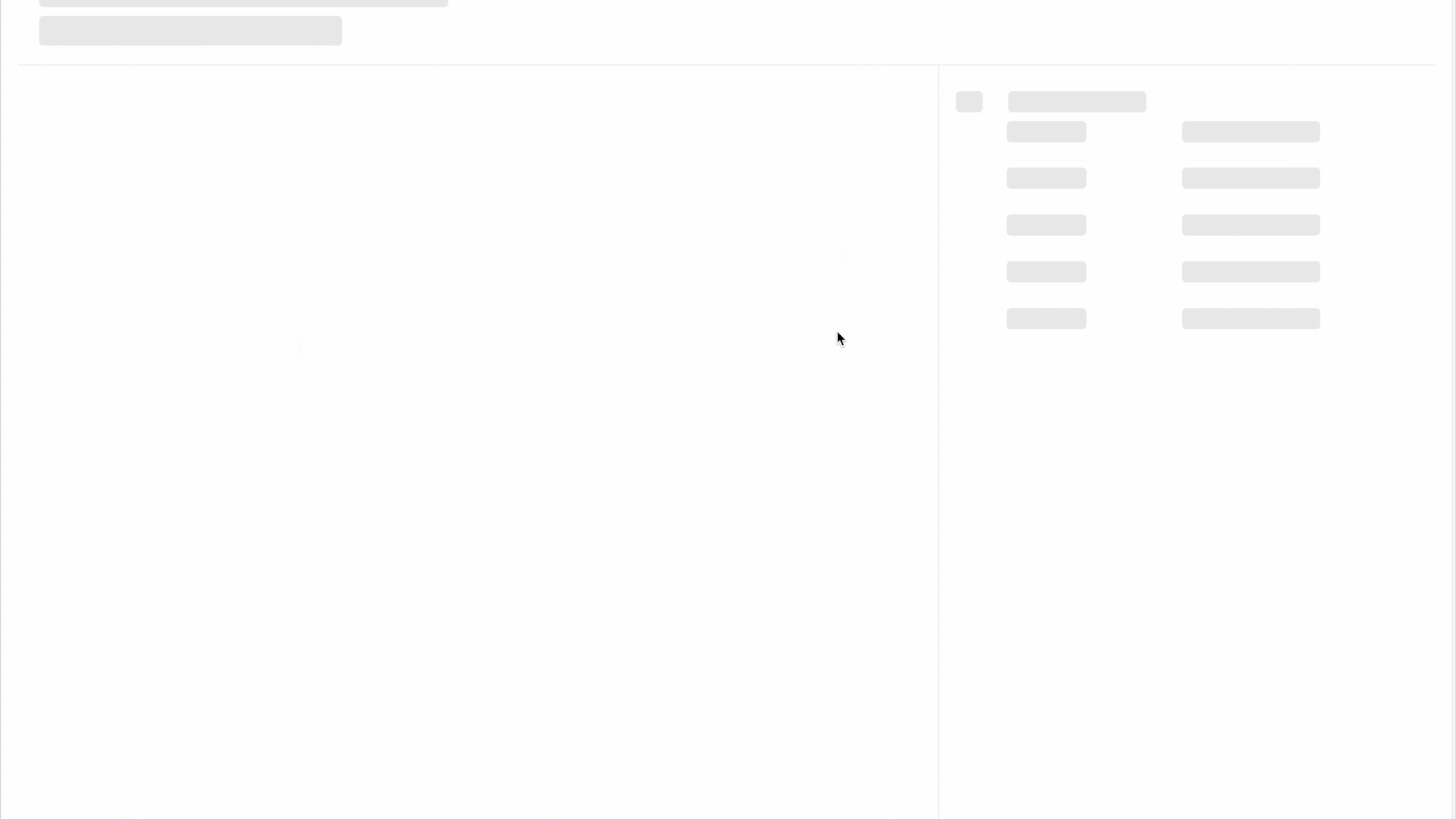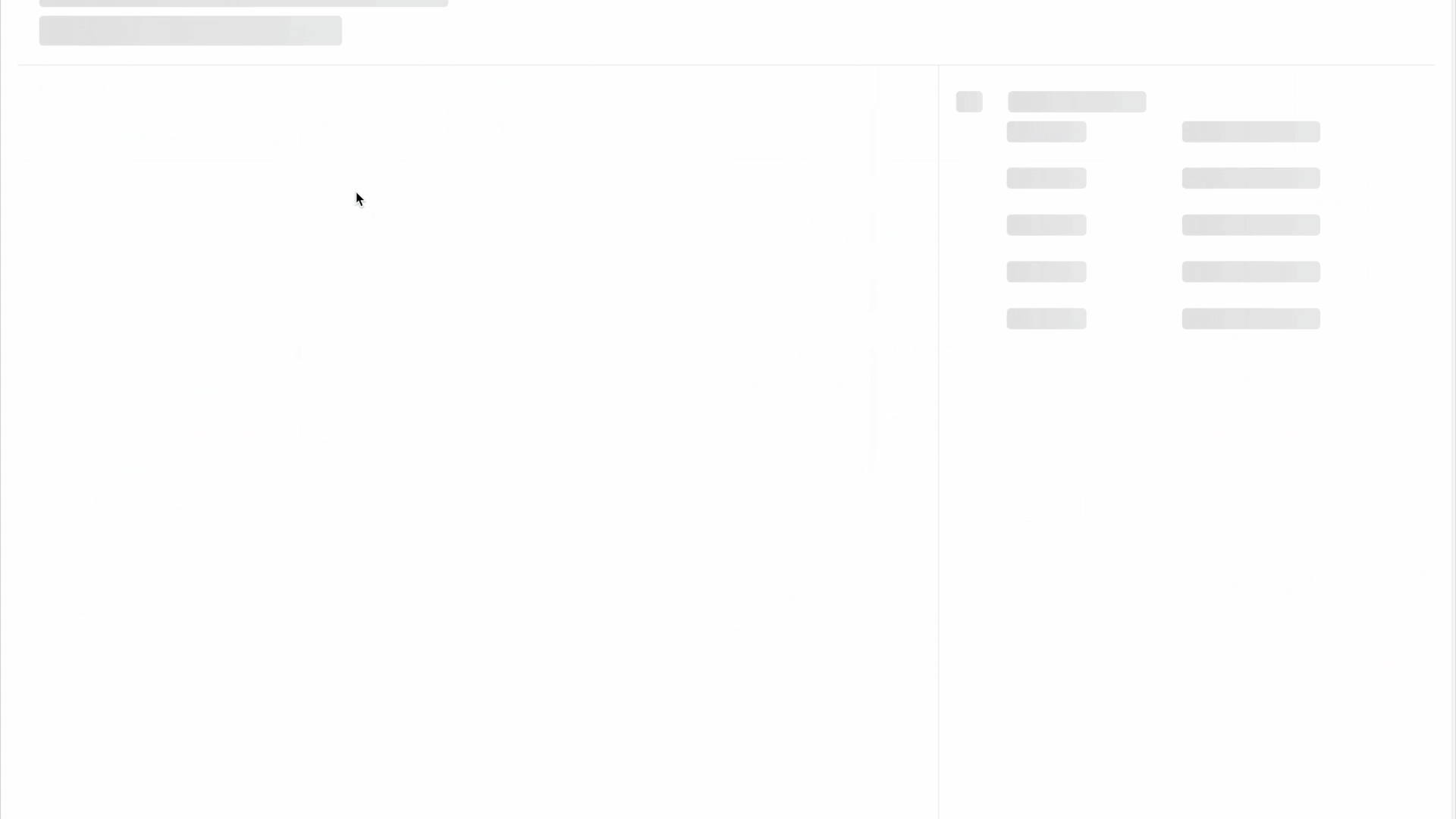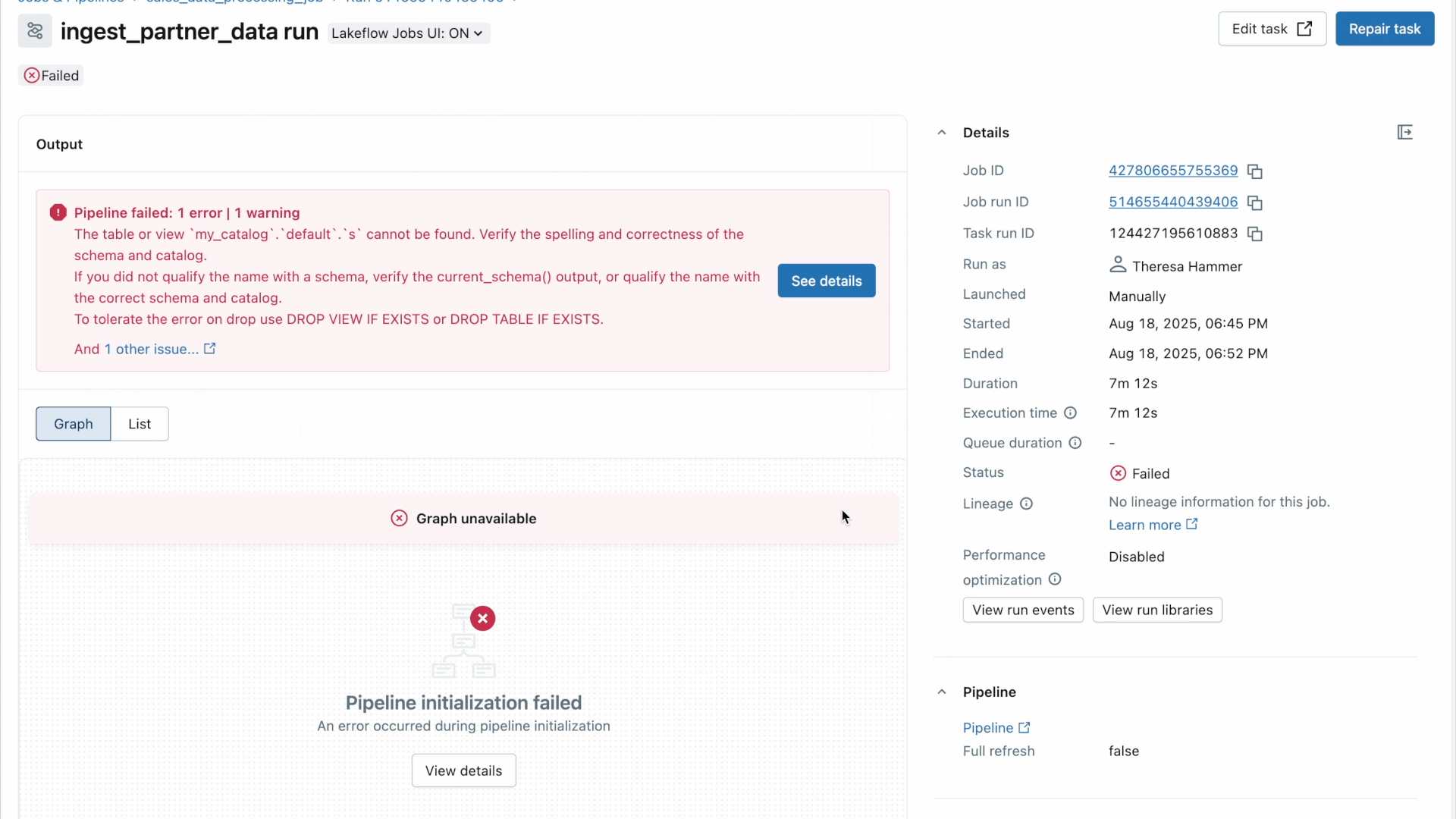
Fewer Blind Spots with a centralized and granular view of your jobs and pipelines
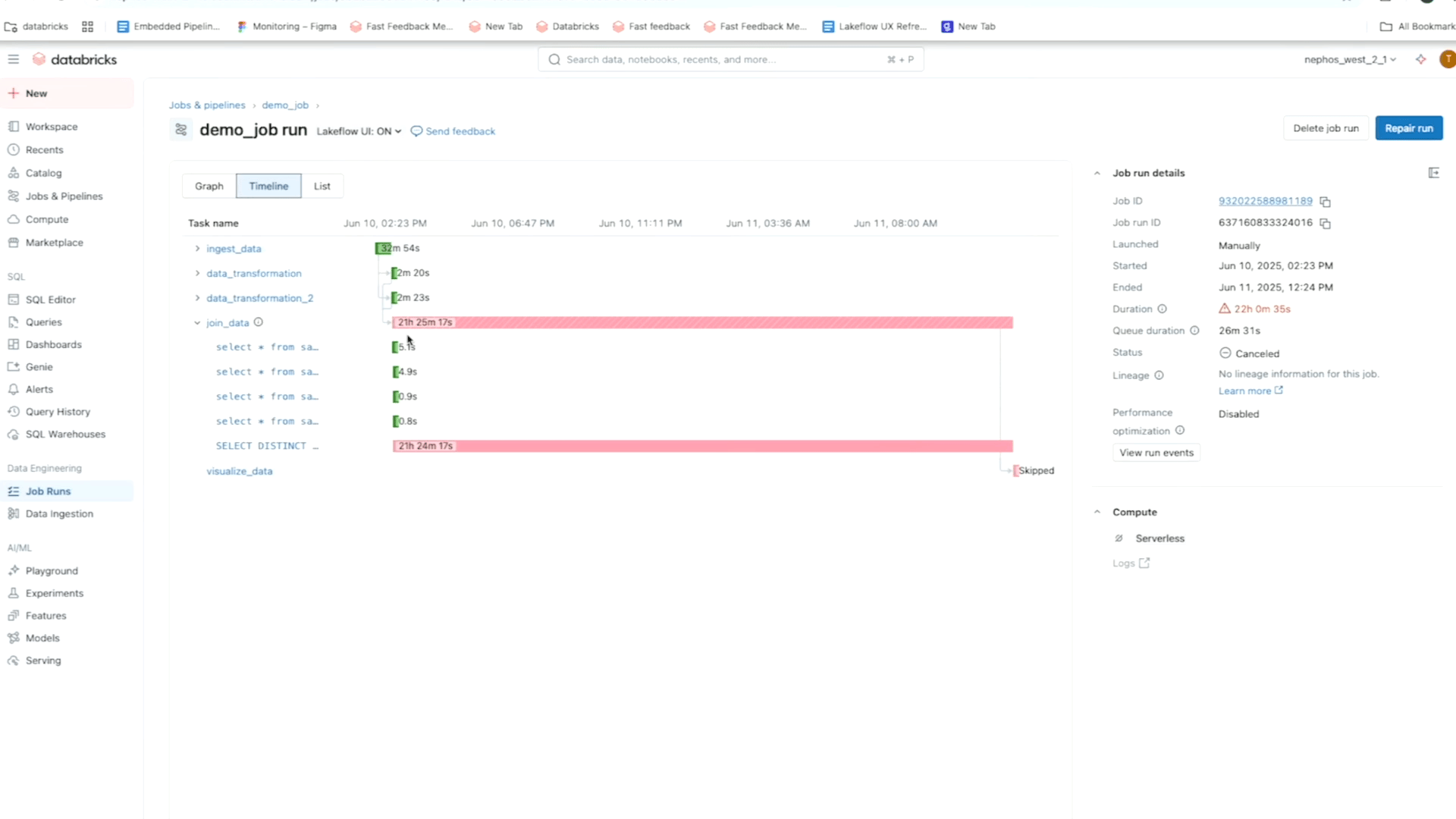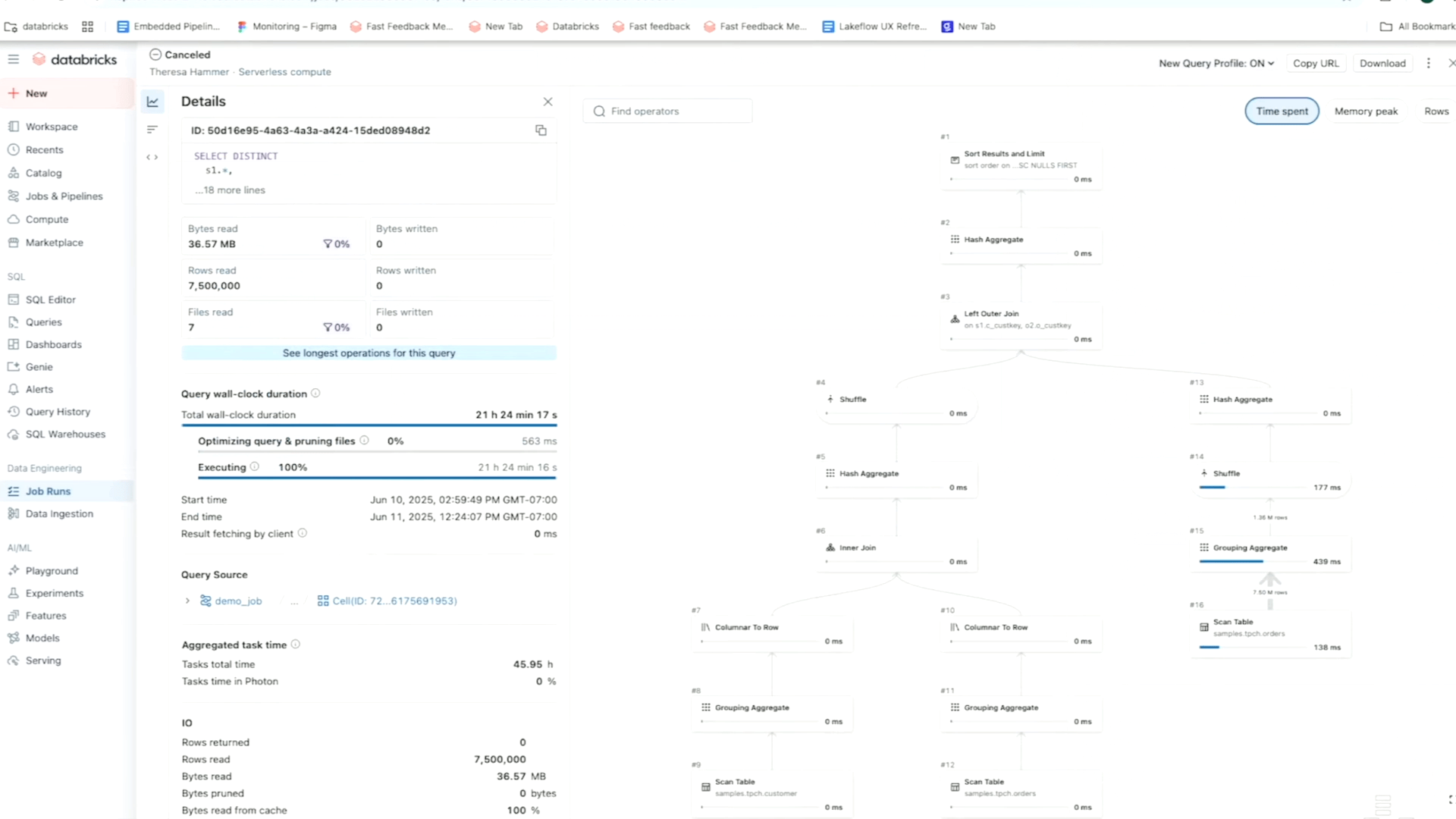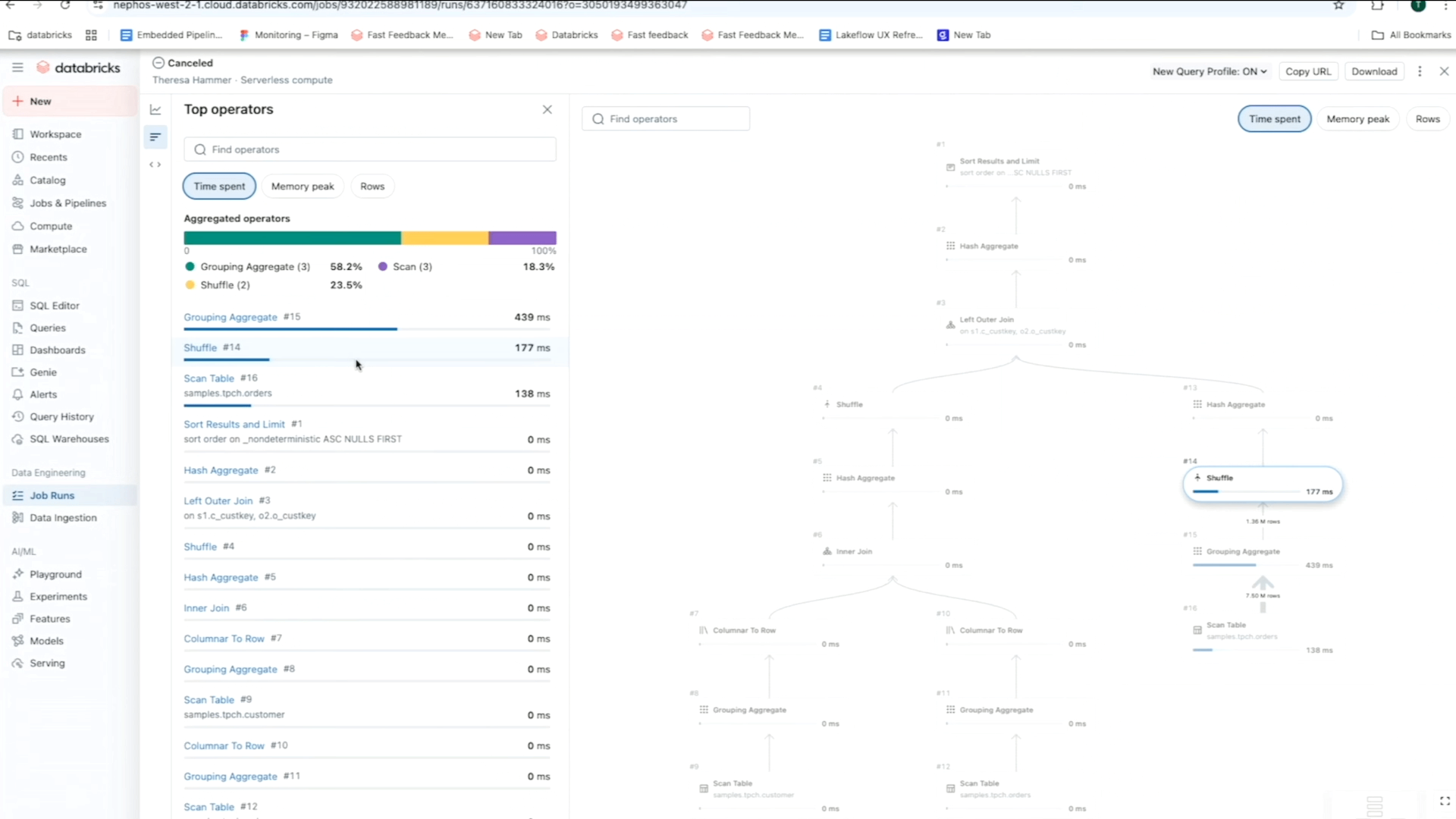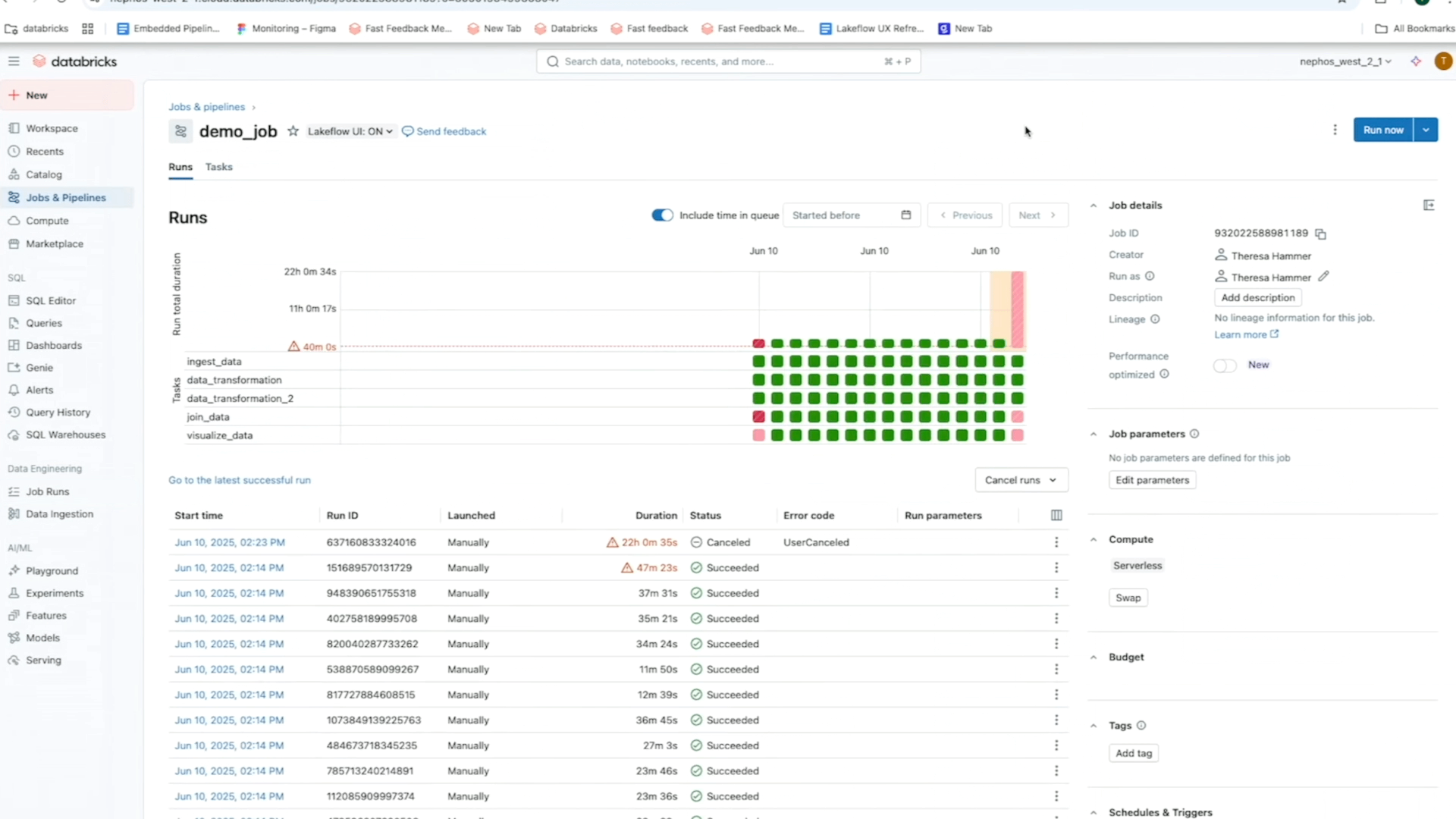
The Jobs and Pipelines web page centralizes entry to all of your jobs, pipelines, and their run historical past throughout the workspace. This unified overview of your runs simplifies the invention and administration of your information pipelines and makes it simpler to visualise executions and monitor developments for extra proactive monitoring.
Searching for extra details about your Jobs? Simply click on on any job to go to a devoted web page that includes a Matrix View and highlights key particulars like standing, length, developments, warnings, and extra. You may:
- simply drill down into a selected Job run for added insights, such because the graph view to visualise dependencies or level of failure
- zoom in to see the duty degree (like pipeline, pocket book output, and so on.) for extra particulars, reminiscent of streaming metrics (accessible in Public Preview).
Lakeflow additionally affords a devoted Pipeline Run web page the place you possibly can simply monitor the standing, metrics, and monitor progress of your pipeline execution throughout tables.
Extra insights with visualization of your information at scale
Along with these unified views, Lakeflow supplies historic observability in your workloads to get insights into your utilization and developments. Utilizing System Tables, Databricks-managed tables that monitor and consolidate each job and pipeline created throughout all workspaces in a area, you possibly can construct detailed dashboards and studies to visualise your jobs and pipelines’ information at scale. With the lately up to date interactive dashboard template for Lakeflow System Tables, it’s a lot simpler and sooner to:
- monitor execution developments: simply floor insights round job conduct over time for higher data-driven choices
- establish bottlenecks: detect potential efficiency points (coated in additional element within the following part)
- cross-reference with billing: enhance value monitoring and keep away from billing surprises
System Tables for Jobs and Pipelines are at the moment in Public Preview.

Visibility extends past simply the duty or job degree. Lakeflow’s integration with Unity Catalog, Databricks’ unified governance answer, helps full the image with a visible of your complete information lineage. This makes it simpler to hint information stream and dependencies and get the total context and influence of your pipelines and jobs in a single single place.

Proactive Monitoring, Early Detection of Job Failures, Troubleshooting, and Optimization
As information engineers, you’re not simply accountable for monitoring your methods. You additionally have to be proactive about any points or efficiency gaps which may come up in your ETL improvement and handle them earlier than they influence your outputs and prices.
Proactive Alerting To Catch Issues Early
With Lakeflow’s native notifications, you possibly can select if and methods to be alerted about vital job errors, durations, or backlogs by way of Slack, e mail, and even PagerDuty. Occasion hooks in Lakeflow Declarative Pipelines (at the moment in Public Preview) offer you much more flexibility by defining customized Python callback features so that you resolve what to watch or when to be alerted on particular occasions.
Sooner Root Trigger Evaluation For Fast Remediation
When you obtain the alert, the subsequent step is to grasp why one thing went fallacious.
Lakeflow lets you bounce from the notification straight into the detailed view of a selected job or process failure for in-context root trigger evaluation. The extent of element and suppleness with which you’ll be able to see your workflow information lets you simply establish what precisely is accountable for the error.
As an illustration, utilizing the matrix view of a job, you possibly can monitor failure and efficiency patterns throughout duties for one particular workflow. In the meantime, the timeline (Gantt) view breaks down the length of every process and question (for serverless jobs) so you possibly can spot sluggish efficiency points in a single job and dig deeper for root causes utilizing Question Profiles. As a reminder, Databricks’ Question Profiles present a fast overview of your SQL, Python, and Declarative Pipeline executions, making it straightforward to establish bottlenecks and optimize workloads in your ETL platform.
It’s also possible to depend on System Tables to make root trigger evaluation simpler by constructing dashboards that spotlight irregularities throughout your jobs and their dependencies. These dashboards assist you shortly establish not simply failures but additionally efficiency gaps or latency enchancment alternatives, reminiscent of latency P50/P90/P99 and cluster metrics. To enrich your evaluation, you possibly can leverage lineage information and question historical past system tables, so you possibly can simply monitor upstream errors and downstream impacts by way of information lineage.
Debugging and Optimization for Dependable Pipelines
Along with root trigger evaluation, Lakeflow provides you instruments for fast troubleshooting, whether or not it’s a cluster useful resource situation or a configuration error. When you’ve addressed the difficulty, you possibly can run the failed duties and their dependencies with out re-running the complete job, saving you computational assets. Dealing with extra advanced troubleshooting use instances? Databricks Assistant, our AI-powered assistant (at the moment in Public Preview), supplies clear insights and helps you diagnose errors in your jobs and pipelines.

We’re at the moment growing extra observability capabilities that will help you higher monitor your information pipelines. Quickly, additionally, you will have the ability to view your workflows and pipelines’ well being metrics and higher perceive the conduct of your workloads with indicators and alerts emitted from Jobs and Pipelines.
Abstract of Lakeflow’s Observability Capabilities
Begin Constructing Dependable Information Engineering with Lakeflow
Lakeflow affords the assist you’ll want to guarantee your jobs and pipelines run easily, are wholesome, and function reliably at scale. Strive our built-in observability options and see how one can construct an information engineering platform prepared in your information intelligence efforts and enterprise wants.

{kind=link}