
LLMs have been a trending subject recently, nevertheless it’s at all times attention-grabbing to grasp how these LLMs work behind the scenes. For these unaware, LLMs have been in improvement since 2017’s launch of the famed analysis paper “Consideration is all you want”. However these early transformer-based fashions had fairly a number of drawbacks attributable to heavy computation and reminiscence necessities from the interior math.
As we generate increasingly more textual content in our LLMs, we begin to devour extra GPU reminiscence. At a sure level, our GPU will get an Out of Reminiscence subject, inflicting the entire program to crash, leaving the LLM unable to generate any extra textual content. Key-Worth caching is a method that helps mitigate this. It principally remembers essential info from earlier steps. As a substitute of recomputing every little thing from scratch, the mannequin reuses what it has already calculated, making textual content era a lot quicker and extra environment friendly. This method has been adopted in a number of fashions, like Mistral, Llama 2, and Llama 3 fashions.
So let’s perceive why KV Caching is so essential for LLMs.
TL;DR
- KV Caching shops beforehand computed Keys/Values, so transformers skip redundant work.
- It massively reduces computation however turns into memory-bound at lengthy sequence lengths.
- Fragmentation & steady reminiscence necessities result in low GPU utilization.
- Paged Consideration (vLLM) fixes this utilizing OS-style paging + non-contiguous reminiscence blocks.
The Consideration Mechanism
We usually generate 3 completely different weight matrices (W_q, W_k, W_v) to provide our Q, Okay, and V vectors. These weight matrices are derived from the info.
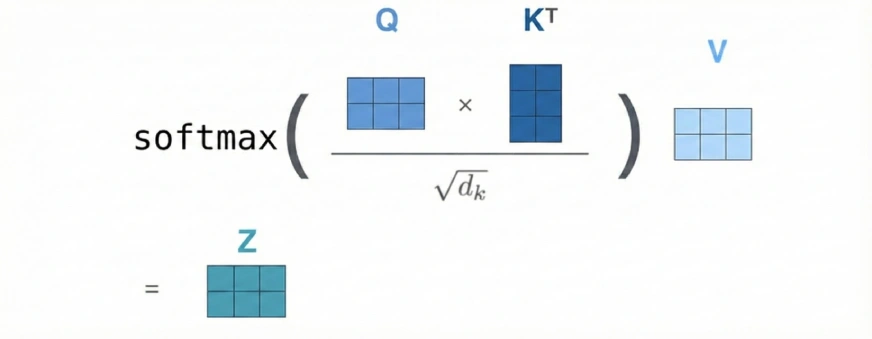
We will take into account our Q to be a vector and the Okay and V to be 2D matrices. It is because Okay and V retailer one vector per earlier token, and when stacked collectively, kind matrices.
The Q vector represents the brand new token that comes within the decoder step.
In the meantime, the Okay matrix represents the knowledge or “keys” of all earlier tokens that the brand new token can question to determine relevance.
At any time when a brand new Question vector is enter, it compares itself with all of the Key vectors. It principally figures out which earlier tokens matter probably the most.
This relevance is represented by way of the weighted common generally known as the tender consideration rating.
The V matrix represents the content material/which means of every earlier token. As soon as the eye scores are computed, they’re used to take a weighted sum of the V vectors. They produce the ultimate contextual output that the mannequin makes use of for the subsequent steps.
In easy phrases, Okay helps determine what to take a look at, and V gives what to take from it.
What was the difficulty?
In a typical causal transformer, which does autoregressive decoding, we generate one phrase at a time, supplied we now have all of the earlier context. As we preserve producing one token at a time, the Okay and V matrices get appended to newer values. As soon as the embedding is computed for this worth, the corresponding worth received’t change in any respect. However the mannequin has to do some heavy computations for the Okay and V matrices for this corresponding worth on all of the steps. This leads to a quadratic variety of matrix multiplications. A really heavy and sluggish activity.
Why we want KV Caching
Let’s attempt to perceive this with a real-life instance – An Examination Preparation State of affairs
We now have our ultimate exams in per week and 20 modules to review in 7 days. We begin with the primary module, which could be considered the primary token. After ending it, we transfer on to the second module and naturally attempt to relate it to what we realized earlier. This new module (the second token), interacting with the earlier modules, is just like how a brand new token interacts with earlier tokens in a sequence.
This relationship is essential for understanding. As we proceed finding out extra modules, we nonetheless keep in mind the content material of the earlier ones, and our reminiscence acts like a cache. So, when studying a brand new module, we solely take into consideration the way it connects to earlier modules as an alternative of re-studying every little thing from the start every time.
This captures the core concept of KV Caching. The Okay and V pairs are saved in reminiscence from the beginning, and every time a brand new token arrives, we solely compute its interplay with the saved context.

How KV Caching helps
As you’ll be able to see, KV Caching saves an enormous quantity of computation as a result of all earlier Okay and V pairs are saved in reminiscence. So when a brand new token arrives, the mannequin solely must compute how this new token interacts with the already-stored tokens. This eliminates the necessity to recompute every little thing from scratch.
With this, the mannequin shifts from being compute-bound to memory-bound, making VRAM the principle limitation. In common multi-head self-attention, each new token requires full tensor operations the place Q, Okay, and V are multiplied with the enter, resulting in quadratic complexity. However with KV Caching, we solely do a single row (vector-matrix) multiplication in opposition to the saved Okay and V matrices to get consideration scores. This drastically reduces compute and makes the method extra restricted by reminiscence bandwidth than uncooked GPU compute.
KV Caching
The core concept behind KV Caching is easy: Can we keep away from recomputing work for tokens the mannequin has already processed throughout inference?
Within the above picture, we see the reddish space to be redundant since we solely care in regards to the computation of the subsequent row in Q-Okay(T).
Right here, Okay corresponds to the Key Matrix and V corresponds to the Worth Matrix.
After we calculate the subsequent token in a causal transformer, we solely want the latest token to foretell the next one. That is the premise of next-word prediction. Since we solely question the nth token to generate the n+1th token, we don’t want the previous Q values and subsequently don’t retailer them. However in commonplace multi-head consideration, Q, Okay, and V for all tokens are recomputed repeatedly as a result of we don’t cache the keys and values.
Within the above picture, Okay and V signify the accrued context from all of the earlier tokens. Earlier than KV Caching existed, the mannequin would recompute all of the Okay and V matrices from the start as much as the most recent token at each decoding step. This additionally meant recomputing all tender consideration scores and ultimate consideration outputs repeatedly, which is compute-intensive. With KV Caching, nonetheless, we retailer all Okay vectors as much as sequence size − 1, and do the identical for the V matrix from 1 to n−1.
Since we solely want to question the most recent token, we don’t recompute the older tokens anymore. The nth token already incorporates all the knowledge required to generate the (n+1)th token.
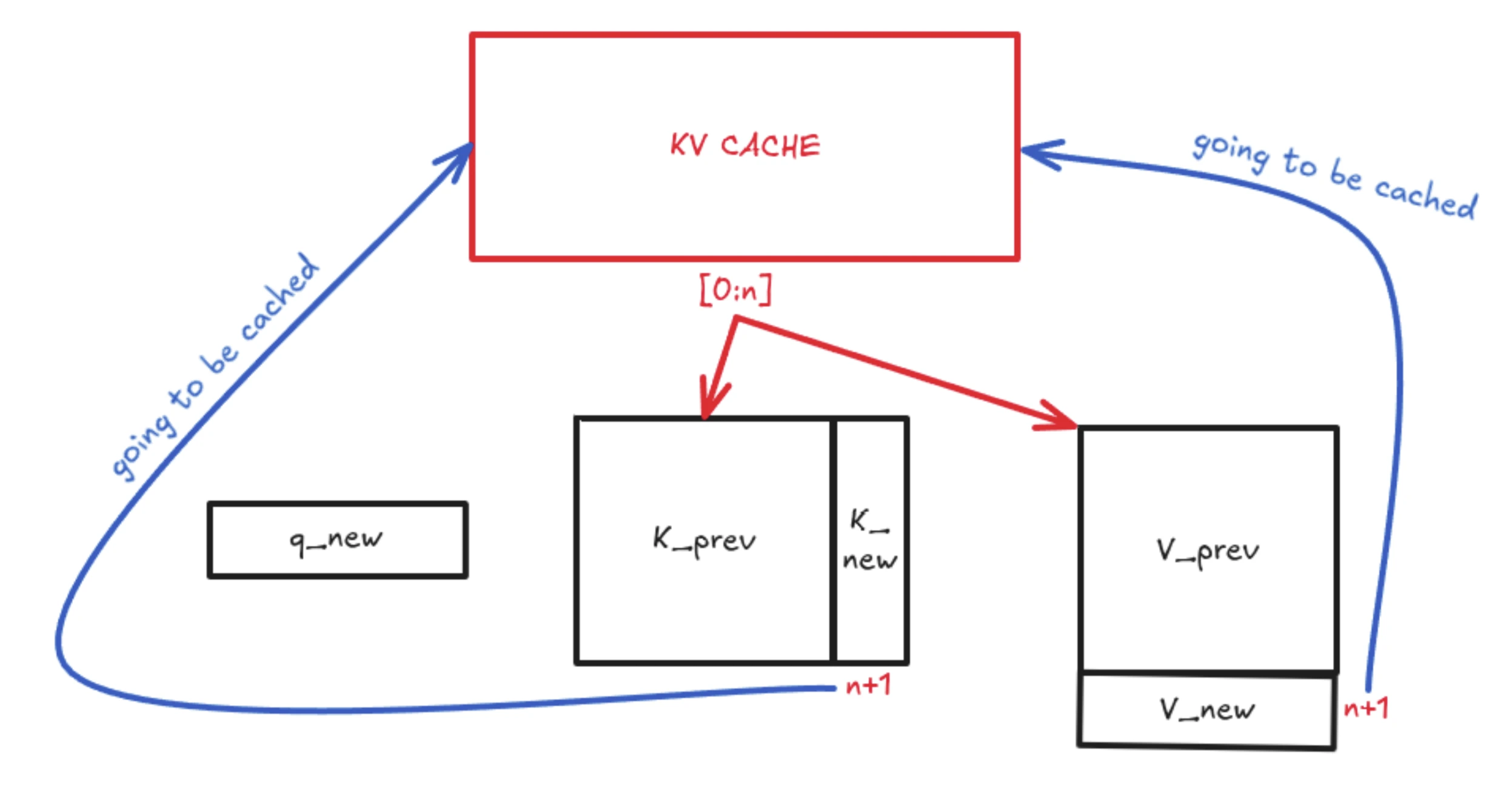
KV Caching: The Core Thought
The primary concept of KV Caching begins from right here…
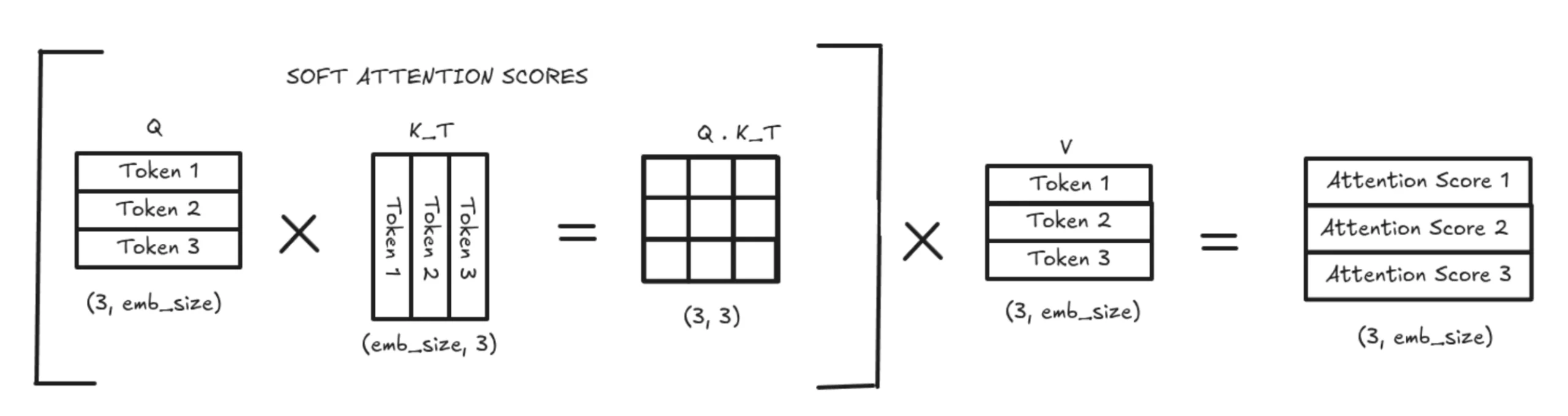
At any time when a brand new token arrives, we compute its new Okay vector and append it as a further column to the present Okay matrix, forming Okay’. Equally, we compute the brand new V vector for the most recent token and append it as a brand new row to kind V’. This can be a light-weight tensor operation.
Illustration
If this feels complicated, let’s break it down with a easy illustration.
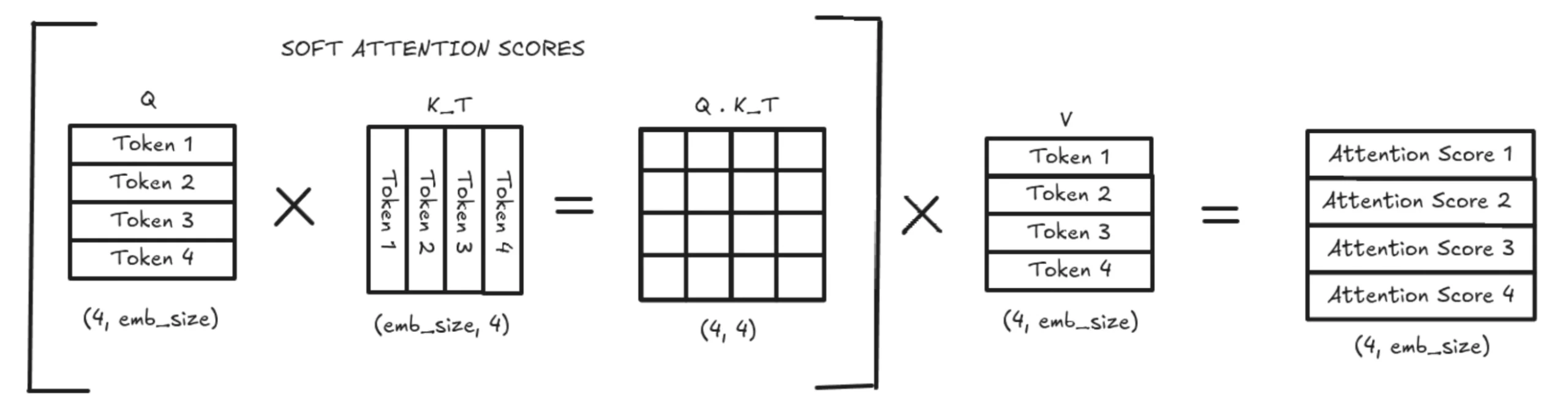
With out KV Caching, the mannequin recomputes your entire Okay and V matrices each time. This leads to a full quadratic-size consideration computation to provide tender consideration scores, that are then multiplied by your entire V matrix. That is extraordinarily costly in each reminiscence and computation.
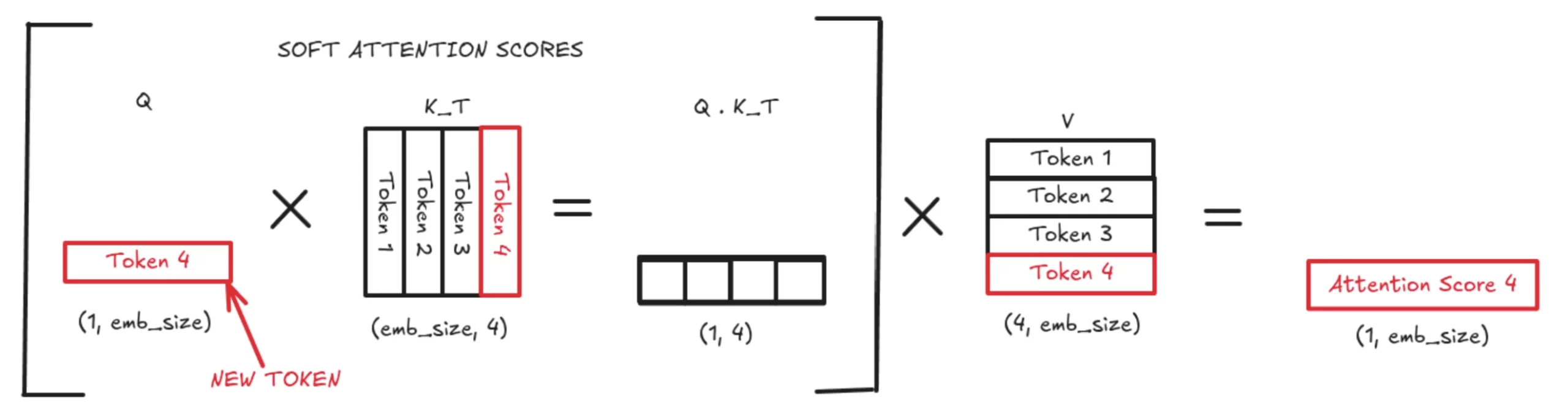
With KV Caching, we solely use the most recent token’s question vector (q_new). This q_new is multiplied by the up to date Okay matrix, which incorporates each K_prev (cached) and K_new (simply computed). The identical logic applies to V_prev, which will get a brand new V_new row. This significantly reduces computation by turning a big matrix-matrix multiplication right into a a lot smaller vector-matrix multiplication. The ensuing consideration rating is appended to the eye matrix and used usually within the transformer circulation.
This 4th consideration worth (on this instance) is then used to compute the subsequent token. With KV Caching, we don’t retailer or recompute earlier Q values, however we do retailer all earlier Okay vectors. The brand new Q is multiplied by Kᵀ to get the Q·Kᵀ vector (the tender consideration scores). These scores are multiplied by the V matrix to provide a weighted common over the saved context, which turns into the 4th token’s output used for prediction.
Consideration solely will depend on previous tokens. This operation will depend on GPU’s VRAM, so we have to retailer these Okay and V matrices. So, successfully, that’s the higher restrict for us as a reminiscence constraint.
There are additionally a number of mentions of KV heads in analysis papers like Llama 2, as a result of we all know transformers have a number of layers, and every layer has a number of heads. For every head KV cache is utilized on it, therefore the title KV head.
Challenges of KV Cache
The challenges we face in KV Caching are:-
- Low GPU Utilization: Regardless of having highly effective GPUs, KV caching usually makes use of solely 20-40% of GPU VRAM, primarily attributable to reminiscence being allotted in methods that can not be totally used.
- Steady Reminiscence Requirement: KV cache blocks have to be saved in contiguous reminiscence, making allocation stricter and leaving many small free gaps unusable.
When coping with KV Cache, GPU reminiscence doesn’t get used completely though GPUs are glorious at dealing with quick, iterative operations. The issue lies in how reminiscence is carved up and reserved for token era.
Inner Fragmentation
Inner fragmentation occurs whenever you allocate extra reminiscence than you really use. For instance, if a mannequin helps a max sequence size of 4096 tokens, we should pre-allocate house for all 4096 positions. However in actuality, most generations may finish at 200-500 tokens. So, though reminiscence for 4096 tokens is sitting there reserved and prepared, solely a small chunk is definitely stuffed. The remaining slots keep empty. This wasted house is inside fragmentation.
Exterior Fragmentation
Exterior fragmentation happens when reminiscence is out there however not in a single clear, steady block. Totally different requests begin and end at completely different instances. This leaves tiny “holes” in reminiscence which are too small to be reused effectively. Though the GPU has VRAM left, it could’t match new KV cache blocks as a result of the free reminiscence isn’t contiguous. This results in low reminiscence utilization though, technically, reminiscence exists.
Reservation Problem
The reservation drawback is principally pre-planning gone unsuitable. We reserve reminiscence as if the mannequin will at all times generate the longest attainable sequence. However era may cease a lot earlier (EOS token, or hitting an early stopping standards). This implies massive chunks of reserved KV cache reminiscence by no means get touched but stay unavailable for different requests.
Paged Consideration
Paged Consideration (utilized in vLLM) fixes the fragmentation drawback by borrowing concepts from how working techniques handle reminiscence. Identical to an OS does paging, vLLM breaks the KV cache into small, fixed-size blocks as an alternative of reserving one massive steady chunk.
- Logical Blocks: Every request sees a clear, steady sequence of KV reminiscence logically. It thinks its tokens are saved one after one other, similar to regular consideration.
- Bodily Blocks: Underneath the hood, these “logical blocks” are literally scattered throughout many non-contiguous bodily reminiscence pages in GPU VRAM. vLLM makes use of a Block Desk (similar to a web page desk in OS) to map logical positions -> bodily places.
So as an alternative of needing one massive 4096 slot steady buffer, Paged Consideration shops tokens in small blocks (like pages) and arranges them flexibly in reminiscence.
This implies:
- No extra inside fragmentation
- No want for steady VRAM
- Immediate reuse of free blocks
- GPU utilization jumps from ~20-40% to ~96%
However we received’t be masking this idea in depth right here. Possibly within the upcoming blogs.
Reminiscence Consumption of KV Cache
To grasp how a lot reminiscence KV cache consumes for a sure mannequin, we have to perceive the next 4 variables right here:-
- num_layers (variety of layers within the transformer mannequin)
- num_heads (KV head for every head within the multi-head self-attention layer)
- head_dim (the dimension of every KV head)
- precision_in_bytes (let’s take 16 bits which is 2 bytes)(FP16 => 16 bits = 2 bytes)
Let’s assume the next values for our use case: num_layers = 32, num_heads = 32, head_dim = 128, and batch_size = 1 (precise deployments often have greater batches).
Let’s now calculate KV cache per token.
KV cache per token = 2 * (num_layers) * (num_heads * head_dim) * precision_in_bytes * batch_size
Why the two?
As a result of we retailer two matrices per token – Okay and V matrices
KV cache per token = 2 * 32 * (32 * 128) * 2 * 1
= 524288 B
= 0.5 MBWe want 0.5 MB to retailer KV per token throughout all of the layers and heads. Shocker!!!
Think about the Llama 2 mannequin, we all know we now have 4096 sequence size if we wish to do 1 request. If we’re requesting sooner than for each request, if we’re utilizing KV cache, we have to retailer all of this info.
Whole KV cache per request = seq_len * KV cache per token
= 4096 * 524288
= 2147483648 / (1024 * 1024 * 1024)
= 2 GBSo principally, we want 2 GB per request. KV cache is required for 1 request.
Conclusion
On this weblog, we mentioned the underlying working of KV Caching and its objective. In doing so, we learnt why it’s such an essential optimization for modern LLMs. We checked out how transformers initially had bother with excessive computation and reminiscence necessities. And the way KV caching considerably reduces redundant work by storing beforehand calculated Key and Worth vectors.
Then, we seemed into the precise issues with KV caching, corresponding to low GPU utilization. The requirement for contiguous reminiscence, and the way issues like reservation, inside fragmentation, and exterior fragmentation end in important VRAM waste.
We additionally briefly mentioned how Paged Consideration (vLLM) resolves these issues utilizing OS type paging logic. It permits KV cache to develop in small, reusable items relatively than huge, inflexible chunks, considerably growing GPU reminiscence utilization.
Lastly, we analysed the computation of KV Cache reminiscence consumption. We noticed that on a mannequin like Llama-2, a single request can simply use nearly 2 GB of VRAM for KV storage. Wild stuff.
If you would like me to enter additional element on Paged Consideration, block tables, and the explanations for vLLM’s quick all through… Let me know within the feedback beneath, and I shall try and cowl the identical in my subsequent weblog. Till then!
GenAI Intern @ Analytics Vidhya | Ultimate Yr @ VIT Chennai
Keen about AI and machine studying, I am desperate to dive into roles as an AI/ML Engineer or Information Scientist the place I could make an actual affect. With a knack for fast studying and a love for teamwork, I am excited to deliver revolutionary options and cutting-edge developments to the desk. My curiosity drives me to discover AI throughout varied fields and take the initiative to delve into information engineering, making certain I keep forward and ship impactful tasks.
Login to proceed studying and revel in expert-curated content material.

{kind=link}