
OpenAI hasn’t launched an open-weight language mannequin since GPT-2 again in 2019. Six years later, they shocked everybody with two: gpt-oss-120b and the smaller gpt-oss-20b.
Naturally, we needed to know — how do they really carry out?
To seek out out, we ran each fashions by way of our open-source workflow optimization framework, syftr. It evaluates fashions throughout completely different configurations — quick vs. low-cost, excessive vs. low accuracy — and consists of help for OpenAI’s new “pondering effort” setting.
In idea, extra pondering ought to imply higher solutions. In apply? Not all the time.
We additionally use syftr to discover questions like “is LLM-as-a-Decide really working?” and “what workflows carry out nicely throughout many datasets?”.
Our first outcomes with GPT-OSS would possibly shock you: the most effective performer wasn’t the most important mannequin or the deepest thinker.
As an alternative, the 20b mannequin with low pondering effort constantly landed on the Pareto frontier, even rivaling the 120b medium configuration on benchmarks like FinanceBench, HotpotQA, and MultihopRAG. In the meantime, excessive pondering effort hardly ever mattered in any respect.
How we arrange our experiments
We didn’t simply pit GPT-OSS in opposition to itself. As an alternative, we needed to see the way it stacked up in opposition to different robust open-weight fashions. So we in contrast gpt-oss-20b and gpt-oss-120b with:
- qwen3-235b-a22b
- glm-4.5-air
- nemotron-super-49b
- qwen3-30b-a3b
- gemma3-27b-it
- phi-4-multimodal-instruct
To check OpenAI’s new “pondering effort” characteristic, we ran every GPT-OSS mannequin in three modes: low, medium, and excessive pondering effort. That gave us six configurations in complete:
- gpt-oss-120b-low / -medium / -high
- gpt-oss-20b-low / -medium / -high
For analysis, we solid a large web: 5 RAG and agent modes, 16 embedding fashions, and a spread of circulate configuration choices. To guage mannequin responses, we used GPT-4o-mini and in contrast solutions in opposition to identified floor reality.
Lastly, we examined throughout 4 datasets:
- FinanceBench (monetary reasoning)
- HotpotQA (multi-hop QA)
- MultihopRAG (retrieval-augmented reasoning)
- PhantomWiki (artificial Q&A pairs)
We optimized workflows twice: as soon as for accuracy + latency, and as soon as for accuracy + value—capturing the tradeoffs that matter most in real-world deployments.
Optimizing for latency, value, and accuracy
After we optimized the GPT-OSS fashions, we checked out two tradeoffs: accuracy vs. latency and accuracy vs. value. The outcomes have been extra stunning than we anticipated:
- GPT-OSS 20b (low pondering effort):
Quick, cheap, and constantly correct. This setup appeared on the Pareto frontier repeatedly, making it the most effective default alternative for many non-scientific duties. In apply, which means faster responses and decrease payments in comparison with increased pondering efforts. - GPT-OSS 120b (medium pondering effort):
Greatest suited to duties that demand deeper reasoning, like monetary benchmarks. Use this when accuracy on advanced issues issues greater than value. - GPT-OSS 120b (excessive pondering effort):
Costly and normally pointless. Hold it in your again pocket for edge circumstances the place different fashions fall quick. For our benchmarks, it didn’t add worth.

Studying the outcomes extra rigorously
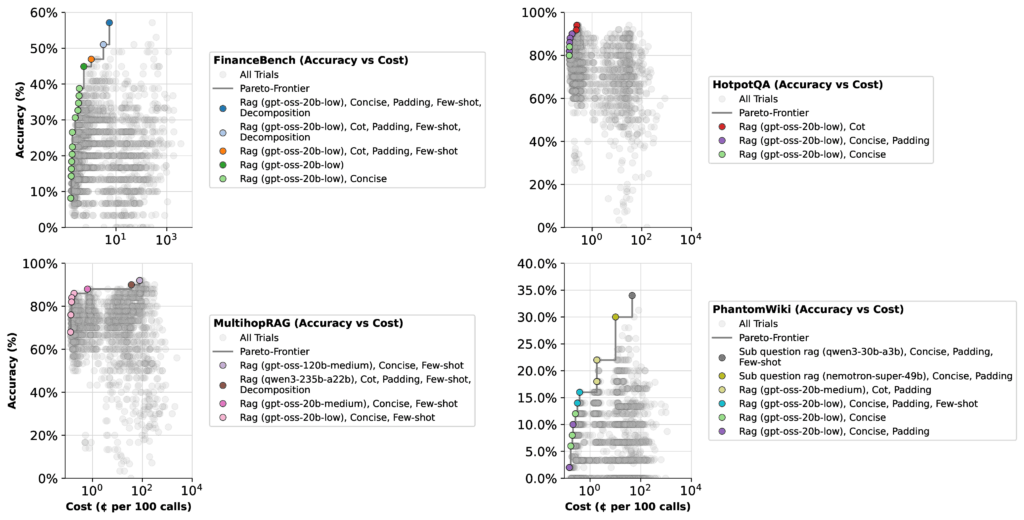
At first look, the outcomes look easy. However there’s an essential nuance: an LLM’s high accuracy rating relies upon not simply on the mannequin itself, however on how the optimizer weighs it in opposition to different fashions within the combine. For example, let’s take a look at FinanceBench.
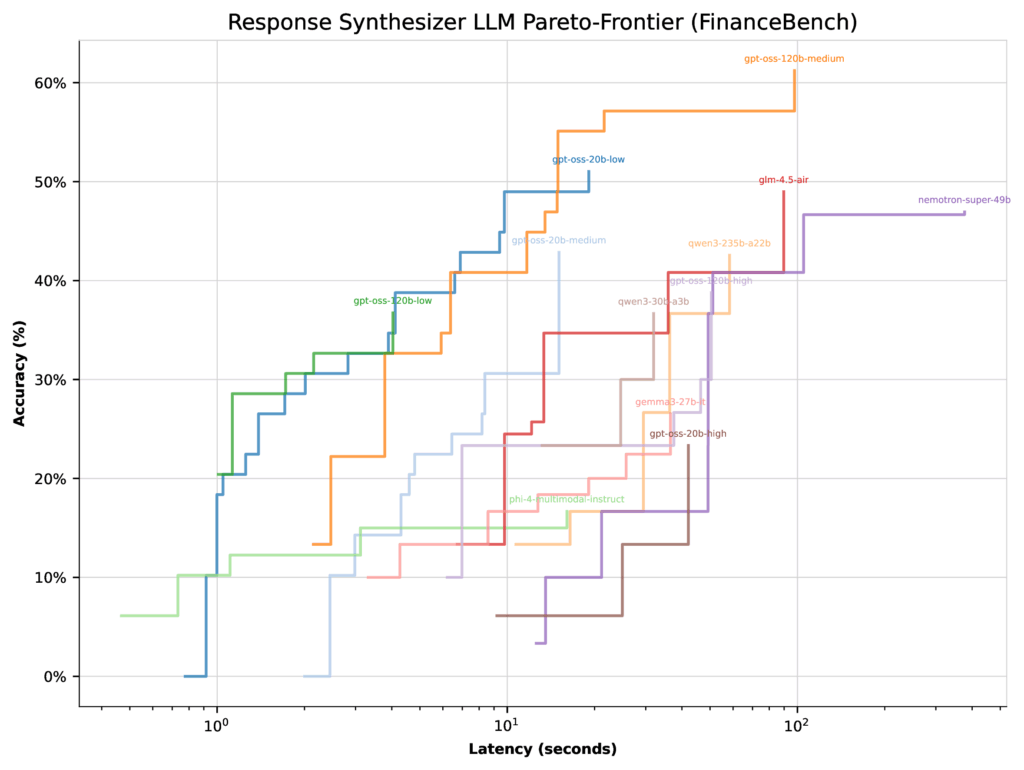
When optimizing for latency, all GPT-OSS fashions (besides excessive pondering effort) landed with related Pareto-frontiers. On this case, the optimizer had little motive to focus on the 20b low pondering configuration—its high accuracy was solely 51%.
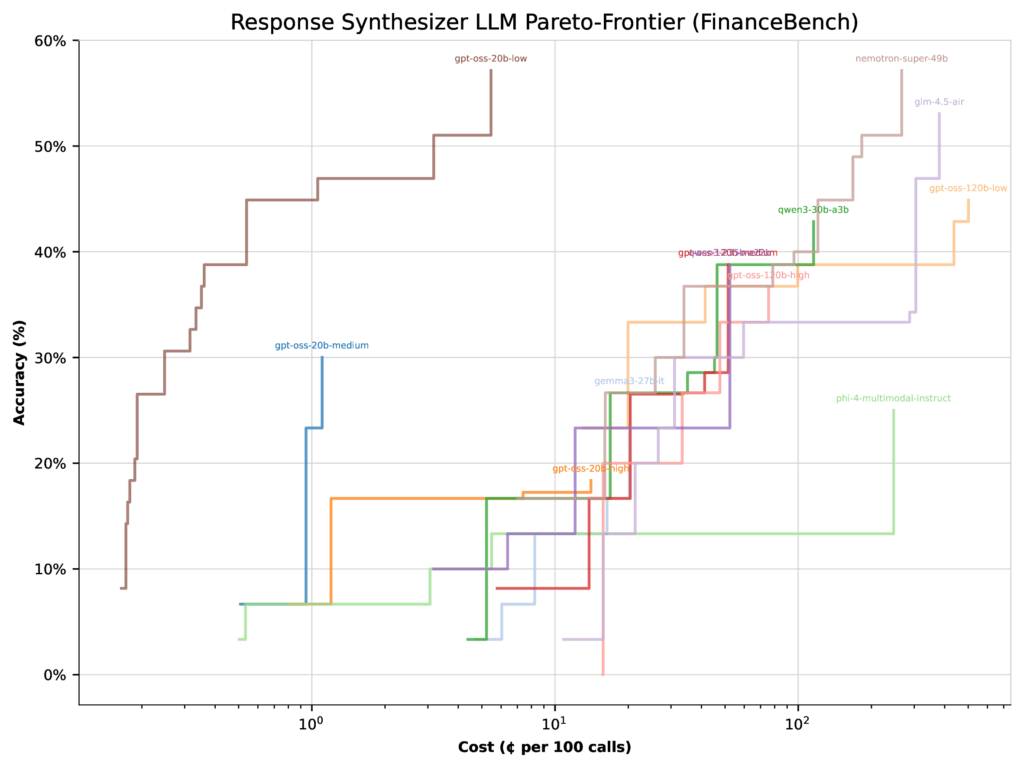
When optimizing for value, the image shifts dramatically. The identical 20b low pondering configuration jumps to 57% accuracy, whereas the 120b medium configuration really drops 22%. Why? As a result of the 20b mannequin is way cheaper, so the optimizer shifts extra weight towards it.
The takeaway: Efficiency is dependent upon context. Optimizers will favor completely different fashions relying on whether or not you’re prioritizing velocity, value, or accuracy. And given the large search house of attainable configurations, there could also be even higher setups past those we examined.
Discovering agentic workflows that work nicely in your setup
The brand new GPT-OSS fashions carried out strongly in our assessments — particularly the 20b with low pondering effort, which regularly outpaced dearer opponents. The larger lesson? Extra mannequin and extra effort doesn’t all the time imply extra accuracy. Generally, paying extra simply will get you much less.
That is precisely why we constructed syftr and made it open-source. Each use case is completely different, and the most effective workflow for you is dependent upon the tradeoffs you care about most. Need decrease prices? Quicker responses? Most accuracy?
Run your individual experiments and discover the Pareto candy spot that balances these priorities to your setup.

{kind=link}